整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
写在文章前:本系列文章用于博主自己归纳复习一些基础知识,同时也分享给可能需要的人,因为水平有限,肯定存在诸多不足以及技术性错误,请大佬们及时指正。
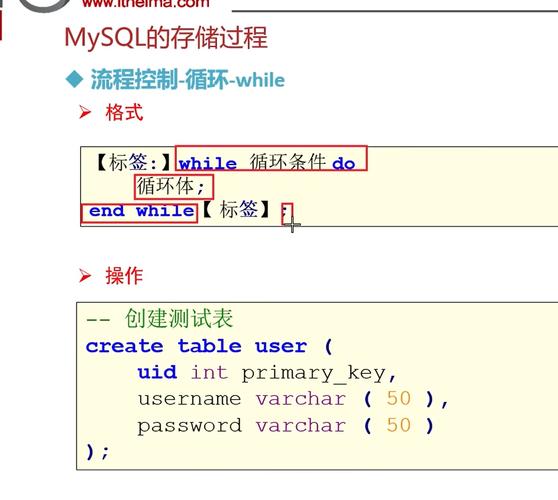
11、存储过程
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合。想要实现相应的功能时,只需要调用这个存储过程就行了(类似于函数,输入具有输出参数)。
优点:
缺点:
Drop/Delete/的区别?
Delete用来删除表的全部或者部分数据,执行delete之后,用户需要提交之后才会执行,会触发表上的DELETE触发器(包含一个OLD的虚拟表,可以只读访问被删除的数据),DELETE之后表结构还在,删除很慢,一行一行地删,因为会记录日志,可以利用日志还原数据;
删除表中的所有数据,这个操作不能回滚,也不会触发这个表上的触发器。操作比DELETE快很多(直接把表drop掉,再创建一个新表,删除的数据不能找回)。如果表中有自增()列,则重置为1。
Drop命令从数据库中删除表,所有的数据行,索引和约束都会被删除。不能回滚,不会触发触发器。
触发器是什么?
触发器(TRIGGER)是由事件(比如INSERT/UPDATE/DELETE)来触发运行的操作(不能被直接调用,不能接收参数)。在数据库里以独立的对象存储,用于保证数据完整性(比如可以检验或转换数据)。
有哪些约束类型?
约束()类型:
12、视图、游标
视图:
从数据库的基本表中通过查询选取出来的数据组成的虚拟表(数据库中只存放视图的定义,而不存放视图的数据)。可以对其进行增/删/改/查等操作。视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变)。
可以跟基本表一样,进行增删改查操作(增删改操作有条件限制,一般视图只允许查询操作),对视图的增删改也会影响原表的数据。它就像一个窗口,透过它可以看到数据库中自己感兴趣的数据并且操作它们。好处:
游标(Cursor):
用于定位在查询返回的结果集的特定行,以对特定行进行操作。使用游标可以方便地对结果集进行移动遍历,根据需要滚动或对浏览/修改任意行中的数据。主要用于交互式应用。它是一段私有的SQL工作区,也就是一段内存区域,用于暂时存放受SQL语句影响的数据,简单来说,就是将受影响的数据暂时放到了一个内存区域的虚表当中,这个虚表就是游标。
游标是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。即游标用来逐行读取结果集。游标充当指针的作用。尽管游标能遍历结果中的所有行,但他一次只指向一行。
游标的一个常见用途就是保存查询结果,以便以后使用。游标的结果集是由SELECT语句产生,如果处理过程需要重复使用一个记录集,那么创建一次游标而重复使用若干次,比重复查询数据库要快的多。通俗来说,游标就是能在sql的查询结果中,显示某一行(或某多行)数据,其查询的结果不是数据表,而是已经查询出来的结果集。
简单来说:游标就是在查询出的结果集中进行选择性操作的工具。
13、SQL语句的优化
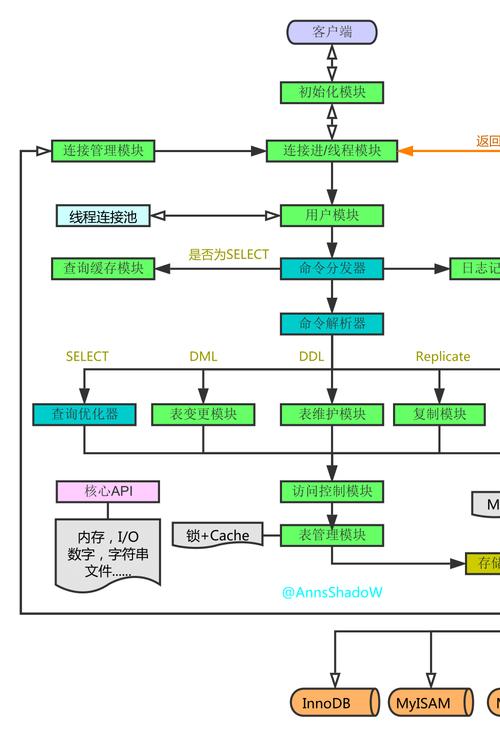
让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余的查询。减少锁竞争。
14、索引
索引是对数据库表中一列或多列的值进行排序的一种结构(说明是在列上建立的),使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。索引的一个主要目的就是加快检索表中数据,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
当表中有大量记录时,若要对表进行查询,第一种搜索信息方式是全表搜索,是将所有记录一一取出,和查询条件进行一一对比,然后返回满足条件的记录,这样做会消耗大量数据库系统时间,并造成大量磁盘I/O操作。第二种就是在表中建立索引,然后在索引中找到符合查询条件的索引值,最后通过保存在索引中的ROWID(相当于页码)快速找到表中对应的记录。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止。有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。
从应用上分,主键索引(聚集),唯一索引(聚集/非聚集),普通索引,组合索引,单列索引和全文索引
索引的优点:
索引的缺点:
索引失效的情况?
哪些地方适合创建索引?
创建索引需要注意的:
机器学习&深度学习资料汇总(含文档,数据集,代码等)(三)
介绍: 1)词频与其降序排序的关系,最著名的是语言学家齐夫(Zipf,1902-1950)1949年提出的Zipf‘s law,即二者成反比关系. 曼德勃罗(,1924- 2010)引入参数修正了对甚高频和甚低频词的刻画 2)Heaps' law: 词汇表与语料规模的平方根(这是一个参数,英语0.4-0.6)成正比
介绍: Jürgen 在Reddit上的AMA(Ask Me )主题,有不少RNN和AI、ML的干货内容,关于开源&思想&方法&建议……耐心阅读,相信你也会受益匪浅.
介绍: 成G上T的学术数据,HN近期热议话题,主题涉及机器学习、NLP、SNA等。下载最简单的方法,通过BT软件,RSS订阅各集合即可
介绍: Scikit-Learn官网提供,在原有的Cheat Sheet基础上加上了Scikit-Learn相关文档的链接,方便浏览
介绍: 深度学习的全面硬件指南,从GPU到RAM、CPU、SSD、PCIe
介绍: paper & data
介绍: 【神经科学碰撞人工智能】在脸部识别上你我都是专家,即使细微的差别也能辨认。研究已证明人类和灵长类动物在面部加工上不同于其他物种,人类使用梭状回面孔区(FFA)。Khaligh-Razavi等通过计算机模拟出人脸识别的FFA活动,堪称神经科学与人工智能的完美结合。
介绍: 神经网络C++教程,本文介绍了用可调节梯度下降和可调节动量法设计和编码经典BP神经网络,网络经过训练可以做出惊人和美妙的东西出来。此外作者博客的其他文章也很不错。
介绍:官网提供的实际应用场景NN选择参考表,列举了一些典型问题建议使用的神经网络。
介绍:一个深度学习项目,提供了Python, C/C++, Java, Scala, Go多个版本的代码
介绍:深度学习教程,github
介绍:自然语言处理的发展趋势——访卡内基梅隆大学爱德华·霍威教授.
介绍:Google对 的有力回击—— FaceNet,在LFW(Labeled Faces in the Wild)上达到99.63%准确率(新纪录),FaceNet 可用于人脸识别、鉴别和聚类.
介绍:本文来自公司网站的一篇博客文章,由Joseph Bradley和Manish Amde撰写,文章主要介绍了Random Forests和-Boosted Trees(GBTs)算法和他们在MLlib中的分布式实现,以及展示一些简单的例子并建议该从何处上手.中文版.
介绍:华盛顿大学Pedro 团队的DNN,提供论文和实现代码.
介绍:基于神经网络的自然语言依存关系解析器(已集成至 CoreNLP),特点是超快、准确,目前可处理中英文语料,基于《A Fast and Parser Using Neural 》思路实现.
介绍:本文根据神经网络的发展历程,详细讲解神经网络语言模型在各个阶段的形式,其中的模型包含NNLM[Bengio,2003]、 NNLM[Bengio, 2005], Log-[Hinton, 2007],SENNA等重要变形,总结的特别好.
介绍:经典问题的新研究:利用文本和可读性特征分类垃圾邮件。
介绍:Kaggle脑控计算机交互(BCI)竞赛优胜方案源码及文档,包括完整的数据处理流程,是学习Python数据处理和Kaggle经典参赛框架的绝佳实例
介绍:IPOL(在线图像处理)是图像处理和图像分析的研究期刊,每篇文章都包含一个算法及相应的代码、Demo和实验文档。文本和源码是经过了同行评审的。IPOL是开放的科学和可重复的研究期刊。我一直想做点类似的工作,拉近产品和技术之间的距离.
介绍:出自MIT,研究加密数据高效分类问题.
介绍:新加坡LV实验室的神经网络并行框架Purine: A bi-graph based deep ,支持构建各种并行的架构,在多机多卡,同步更新参数的情况下基本达到线性加速。12块Titan 20小时可以完成的训练。
介绍:这是一个机器学习资源库,虽然比较少.但蚊子再小也是肉.有突出部分.此外还有一个由zheng Rui整理的机器学习资源.
介绍:Chase Davis在NICAR15上的主题报告材料,用Scikit-Learn做监督学习的入门例子.
介绍:这是一本自然语言处理的词典,从1998年开始到目前积累了成千上万的专业词语解释,如果你是一位刚入门的朋友.可以借这本词典让自己成长更快.
介绍:通过分析1930年至今的比赛数据,用计算世界杯参赛球队排行榜.
介绍:R语言教程,此外还推荐一个R语言教程An to R.
介绍:经典老文,复杂网络社区发现的高效算法,Gephi中的[ ](The Louvain method for in large )即基于此.
介绍: 一个面向 .net 的开源机器学习库,github地址
介绍: 支持node.js的JS神经网络库,可在客户端浏览器中运行,支持LSTM等github地址
介绍: 决策树
介绍: 讨论深度学习自动编码器如何有效应对维数灾难,国内翻译
介绍: CMU的优化与随机方法课程,由A. Smola和S. Sra主讲,优化理论是机器学习的基石,值得深入学习国内云(视频)
介绍: "面向视觉识别的CNN"课程设计报告集锦.近百篇,内容涉及图像识别应用的各个方面
介绍:用Spark的MLlib+GraphX做大规模LDA主题抽取.
介绍: 基于深度学习的多标签分类,用基于RBM的DBN解决多标签分类(特征)问题
介绍: 论文集锦
介绍: 一个开源语音识别工具包,它目前托管在上面
介绍: 免费电子书《数据新闻手册》, 国内有热心的朋友翻译了中文版,大家也可以在线阅读
介绍: 零售领域的数据挖掘文章.
介绍: 深度学习卷积概念详解,深入浅出.
介绍: 非常强大的Python的数据分析工具包.
介绍: 2015文本分析(商业)应用综述.
介绍: 深度学习框架、库调研及Theano的初步测试体会报告.
介绍: MIT的Yoshua Bengio, Ian , Aaron 著等人讲深度学习的新书,还未定稿,线上提供Draft 收集反馈,超赞!强烈推荐.
介绍: Python下开源可持久化朴素贝叶斯分类库.
介绍:Paracel is a for machine , graph and in C++.
介绍: 开源汉语言处理包.
介绍: 使用Ruby实现简单的神经网络例子.
介绍:神经网络黑客入门.
介绍:好多数据科学家名人推荐,还有资料.
介绍:实现项目已经开源在github上面Crepe
介绍:作者发现,经过调参,传统的方法也能和取得差不多的效果。另外,无论作者怎么试,GloVe都比不过.
介绍:深度学习与自然语言处理课程,Richard Socher主讲.
介绍:机器学习中的重要数学概念.
介绍:用于改进语义表示的树型LSTM递归神经网络,句子级相关性判断和情感分类效果很好.实现代码.
介绍:卡耐基梅隆Ryan 和Larry 开设的机器学习课程,先修课程为机器学习(10-715)和中级统计学(36-705),聚焦统计理论和方法在机器学习领域应用.
介绍:《哈佛大学蒙特卡洛方法与随机优化课程》是哈佛应用数学研究生课程,由V Kaynig-Fittkau、P 主讲,Python程序示例,对贝叶斯推理感兴趣的朋友一定要看看,提供授课视频及课上IPN讲义.
介绍:生物医学的SPARK大数据应用.并且伯克利开源了他们的big data 系统ADAM,其他的内容可以关注一下官方主页.
介绍:对自然语言处理技术或者机器翻译技术感兴趣的亲们,请在提出自己牛逼到无以伦比的idea(自动归纳翻译规律、自动理解语境、自动识别语义等等)之前,请通过谷歌学术简单搜一下,如果谷歌不可用,这个网址有这个领域几大顶会的论文列表,切不可断章取义,胡乱假设.
介绍:论文+代码:基于集成方法的Twitter情感分类,实现代码.
介绍:NIPS CiML 2014的PPT,NIPS是神经信息处理系统进展大会的英文简称.
介绍:斯坦福的深度学习课程的 每个人都要写一个论文级别的报告 里面有一些很有意思的应用 大家可以看看 .
介绍:R语言线性回归多方案速度比较具体方案包括lm()、nls()、glm()、()、nls()、mle2()、optim()和Stan’s ()等.
介绍:文中提到的三篇论文(机器学习那些事、无监督聚类综述、监督分类综述)都很经典,的机器学习课也很精彩
介绍:莱斯大学(Rice )的深度学习的概率理论.
介绍:基于马尔可夫链自动生成啤酒评论的开源Twitter机器人,github地址.
介绍:视频+讲义:深度学习用于自然语言处理教程(NAACL13).
介绍:用机器学习做数据分析,David Taylor最近在McGill 研讨会上的报告,还提供了一系列讲机器学习方法的ipn,很有价值GitHub.国内
介绍:基于CNN+LSTM的视频分类,google演示.
介绍:Quora怎么用机器学习.
介绍:亚马逊在机器学习上面的一些应用,代码示例.
介绍:并行机器学习指南(基于scikit-learn和IPython).
介绍:的机器学习基本概念教学.
介绍:一个基于OpenGL实现的卷积神经网络,支持Linux及Windows系统.
介绍:基于Mahout和的推荐系统.
介绍:Francis X. Diebold的《(经济|商业|金融等领域)预测方法.
介绍:Francis X. Diebold的《时序计量经济学》.
介绍:基于Yelp数据集的开源情感分析工具比较,评测覆盖Naive Bayes、、CoreNLP等 .
介绍:国内Pattern And Machine 读书会资源汇总,各章pdf讲稿,博客.
介绍:用于Web分析和数据挖掘的概率数据结构.
介绍:机器学习在导航上面的应用.
介绍:Neural 系列视频,Stephen Welch制作,纯手绘风格,浅显易懂,国内云.
介绍:{swirl}数据训练营:R&数据科学在线交互教程.
介绍:关于深度学习和RNN的讨论 to with Neural .
介绍:Deep .
介绍:()Scikit-Learn机器学习教程, Machine with scikit-learn and IPython.

介绍:PDNN: A Python Toolkit for Deep .
介绍:15年春季学期CMU的机器学习课程,由Alex Smola主讲,提供讲义及授课视频,很不错.国内镜像.
介绍:大数据处理课.内容覆盖流处理、、图算法等.
介绍:用Spark MLlib实现易用可扩展的机器学习,国内镜像.
介绍:以往上千行代码概率编程(语言)实现只需50行.
介绍:ggplot2速查小册子,另外一个,此外还推荐《A new data for R: dplyr, , tidyr, ggplot2》.
介绍:用结构化模型来预测实时股票行情.
介绍:国际人工智能联合会议录取论文列表,大部分论文可使用Google找到.
介绍:一般矩阵乘法(GEMM)对深度学习的重要性.
介绍:A of awesome Machine C++ .
介绍:免费电子书,第一版(1998),第二版(2015草稿),相关课程资料, .
介绍:免费书:Azure ML使用精要.
介绍:A Deep : From to Deep .
介绍:有趣的机器学习:最简明入门指南,中文版.
介绍:深度学习简明介绍,中文版.
介绍:, and machine .
介绍:CNN开源实现横向评测,参评框架包括Caffe 、Torch-7、CuDNN 、 、fbfft、Nervana Systems等,表现突出.
介绍:卡耐基梅隆大学计算机学院语言技术系的资源大全,包括大量的NLP开源软件工具包,基础数据集,论文集,数据挖掘教程,机器学习资源.
介绍:Twitter情感分析工具,视频+讲义.
介绍:华盛顿大学的Machine Paper .
介绍:机器学习速查表.
介绍:最新的Spark summit会议资料.
介绍:最新的Spark summit会议资料.
介绍:Ebook Spark.
介绍:Ebook with Spark, Early Release Edition.
介绍:清华大学副教授,是图挖掘方面的专家。他主持设计和实现的是国内领先的图挖掘系统,该系统也是多个会议的支持商.
介绍:迁移学习的国际领军人物.
介绍:在半监督学习,multi-label学习和集成学习方面在国际上有一定的影响力.
介绍:信息检索,自然语言处理,机器翻译方面的专家.
介绍:吴军博士是当前Google中日韩文搜索算法的主要设计者。在Google其间,他领导了许多研发项目,包括许多与中文相关的产品和自然语言处理的项目,他的新个人主页.
介绍:喵星人相关论文集.
介绍:如何评价机器学习模型系列文章,How to Machine Models, Part 2a: Metrics,How to Machine Models, Part 2b: Ranking and Metrics.
介绍:Twitter新trends的基本实现框架.
介绍:Storm手册,国内有中文翻译版本,谢谢作者.
介绍:Java机器学习算法库.
介绍:机器翻译学术论文写作方法和技巧,Simon Peyton Jones的How to write a good paper同类视频How to Write a Great Paper,how to paper talk.
介绍:神经网络训练中的Tricks之高效BP,博主的其他博客也挺精彩的.
介绍:作者是NLP方向的硕士,短短几年内研究成果颇丰,推荐新入门的朋友阅读.
介绍:UCLA的Jens 根据Google Scholar建立了一个计算机领域的H-index牛人列表,我们熟悉的各个领域的大牛绝大多数都在榜上,包括1位诺贝尔奖得主,35位图灵奖得主,近百位美国工程院/科学院院士,300多位ACM Fellow,在这里推荐的原因是大家可以在google通过搜索牛人的名字来获取更多的资源,这份资料很宝贵.
介绍:用大型语料库学习概念的层次关系,如鸟是鹦鹉的上级,鹦鹉是虎皮鹦鹉的上级。创新性在于模型构造,用因子图刻画概念之间依存关系,因引入兄弟关系,图有环,所以用有环扩散(loopy )迭代计算边际概率( ).
介绍: 这是一款贝叶斯分析的商业软件,官方写的贝叶斯分析的手册有250多页,虽然R语言 已经有类似的项目,但毕竟可以增加一个可选项.
PS. 目前极市拥有上千名视觉算法开发者,分别来自腾讯,华为,百度,网易,联想,努比亚等名企,以及北大,清华,北航,中科院,交大等名校,欢迎从业者加入极市专业CV开发者微信群,请填写下表申请入群~

*请认真填写需求信息,我们会在24小时内与您取得联系。
