整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
关系数据库设计之时是要遵守一定的规则的。尤其是数据库设计范式 现简单介绍1NF(第一范式),2NF(第二范式),3NF(第三范式)和BCNF,另有第四范式和第五范式留到以后再介绍。
在你设计数据库之时,若能符合这几个范式,你就是数据库设计的高手。
第一范式(1NF)
在关系模式R中的每一个具体关系r中,如果每个属性值 都是不可再分的最小数据单位,则称R是第一范式的关系。
例:如职工号,姓名,电话号码组成一个表(一个人可能有一个办公室电话 和一个家里电话号码) 规范成为1NF有三种方法:一是重复存储职工号和姓名。这样,关键字只能是电话号码。二是职工号为关键字,电话号码分为单位电话和住宅电话两个属性三是职工号为关键字,但强制每条记录只能有一个电话号码。以上三个方法,第一种方法最不可取,按实际情况选取后两种情况。
第二范式(2NF)
如果关系模式R(U,F)中的所有非主属性都完全依赖于任意一个候选关键字,则称关系R 是属于第二范式的。例:选课关系 SCI(SNO,CNO,GRADE,CREDIT)其中SNO为学号, CNO为课程号,GRADEGE 为成绩,CREDIT 为学分。由以上条件,关键字为组合关键字(SNO,CNO) 在应用中使用以上关系模式有以下问题:
原因:非关键字属性CREDIT仅函数依赖于CNO,也就是CREDIT部分依赖组合关键字(SNO,CNO)而不是完全依赖。解决方法:分成两个关系模式 SC1(SNO,CNO,GRADE),C2(CNO,CREDIT)。新关系包括两个关系模式,它们之间通过SC1中的外关键字CNO相联系,需要时再进行自然联接,恢复了原来的关系。
第三范式(3NF)
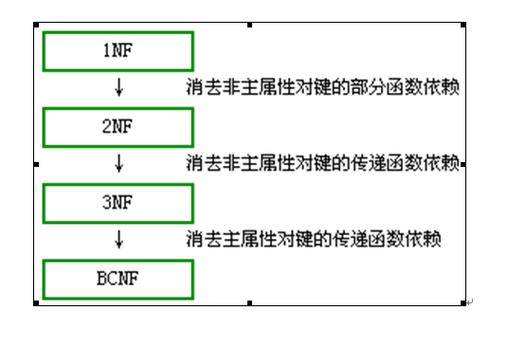
如果关系模式R(U,F)中的所有非主属性对任何候选关键字都不存在传递信赖,则称关系R是属于第三范式的。
例:如S1(SNO,SNAME,DNO,DNAME,) 各属性分别代表学号, 姓名,所在系,系名称,系地址。关键字SNO决定各个属性。由于是单个关键字,没有部分依赖的问题,肯定是2NF。但这关系肯定有大量的冗余,有关学生所在的几个属性DNO,DNAME,将重复存储,插入,删除和修改时也将产生类似以上例的情况。
原因:关系中存在传递依赖造成的。即SNO -> DNO(而DNO -> SNO却不存在),DNO -> , 因此关键字SNO 对 函数决定是通过传递依赖 SNO -> 实现的。也就是说,SNO不直接决定非主属性。
解决目的:每个关系模式中不能留有传递依赖。解决方法:分为两个关系 S(SNO,SNAME,DNO),D(DNO,DNAME,)
注意:关系S中不能没有外关键字DNO。否则两个关系之间失去联系。
BCNF:如果关系模式R(U,F)的所有属性(包括主属性和非主属性)都不传递依赖于R的任何候选关键字,那么称关系R是属于BCNF的。或是关系模式R,如果每个决定因素都包含关键字(而不是被关键字所包含),则BCNF的关系模式。例:配件管理关系模式 WPE(WNO,PNO,ENO,QNT)分别表仓库号,配件号,职工号,数量。有以下条件 a.一个仓库有多个职工。b.一个职工仅在一个仓库工作。c.每个仓库里一种型号的配件由专人负责,但一个人可以管理几种配件。d.同一种型号的配件可以分放在几个仓库中。分析:
因为一个职工仅在一个仓库工作,有ENO -> WNO。由于每个仓库里的一种配件由专人负责,而一个职工仅在一个仓库工作,有 (WNO,PNO)-> QNT。找一下候选关键字,因为(WNO,PNO) -> QNT,(WNO,PNO)-> ENO ,因此 (WNO,PNO)可以决定整个元组,是一个候选关键字。根据ENO->WNO,(ENO,PNO)->QNT,故(ENO,PNO)也能决定整个元组,为另一个候选关键字。属性ENO,WNO,PNO 均为主属性,只有一个非主属性QNT。它对任何一个候选关键字都是完全函数依赖的,并且是直接依赖,所以该关系模式是3NF。分析一下主属性。因为ENO->WNO,主属性ENO是WNO的决定因素,但是它本身不是关键字,只是组合关键字的一部分。这就造成主属性WNO对另外一个候选关键字(ENO,PNO)的部 分依赖,因为(ENO,PNO)-> ENO但反过来不成立,而PNO->WNO,故(ENO,PNO)-> WNO 是传递依赖。虽然没有非主属性对候选关键字的传递依赖,但存在主属性对候选关键字的传递依赖,同样也会带来麻烦。如一个新职工分配到仓库工作,但暂时处于实习阶段,没有独立负责对某些配件的管理任务。由于缺少关键字的一部分PNO而无法插入到该关系中去。又如某个人改成不管配件了去负责安全,则在删除配件的同时该职工也会被删除。
如此例中,由于分解,函数依赖(WNO,PNO)-> ENO 丢失了, 因而对原来的语义有所破坏。没有体现出每个仓库里一种部件由专人负责。有可能出现 一部件由两个人或两个以上的人来同时管理。因此,分解之后的关系模式降低了部分完整性约束。一个关系分解成多个关系,要使得分解有意义,起码的要求是分解后不丢失原来的信息。这些信息不仅包括数据本身,而且包括由函数依赖所表示的数据之间的相互制约。进行分解的目标是达到更高一级的规范化程度,但是分解的同时必须考虑两个问题:无损联接性和保持函数依赖。有时往往不可能做到既有无损联接性,又完全保持函数依赖。需要根据需要进行权衡。
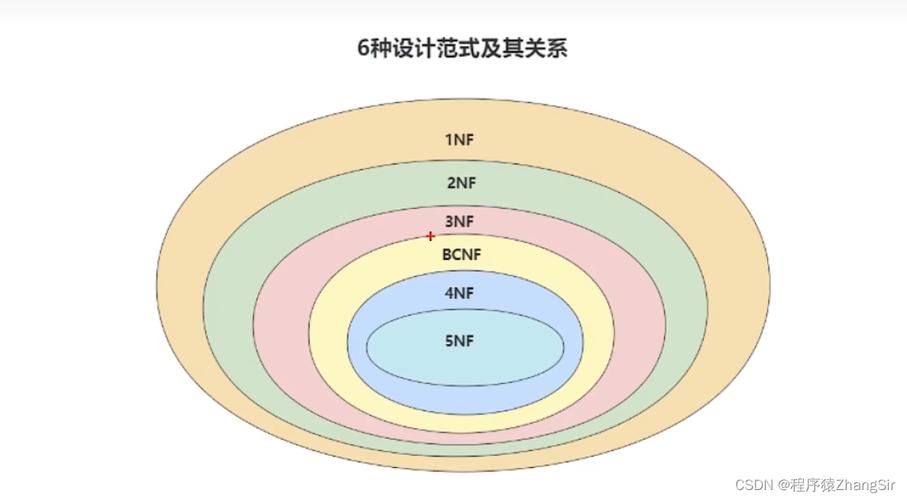
1NF直到BCNF的四种范式之间有如下关系:BCNF包含了3NF包含2NF包含1NF
小结:
目的:规范化目的是使结构更合理,消除存储异常,使数据冗余尽量小,便于插入、删除和更新
原则:遵从概念单一化 "一事一地"原则,即一个关系模式描述一个实体或实体间的一种联系。规范的实质就是概念的单一化。
方法:将关系模式投影分解成两个或两个以上的关系模式。要求:分解后的关系模式集合应当与原关系模式"等价",即经过自然联接可以恢复原关系而不丢失信息,并保持属性间合理的联系。
注意:一个关系模式结这分解可以得到不同关系模式集合,也就是说分解方法不是唯一的。最小冗余的要求必须以分解后的数据库能够表达原来数据库所有信息为前提来实现。其根本目标是节省存储空间,避免数据不一致性,提高对关系的操作效率,同时满足应用需求。实际上,并不一定要求全部模式都达到BCNF不可。有时故意保留部分冗余可能更方便数据查询。尤其对于那些更新频度不高,查询频度极高的数据库系统更是如此。在关系数据库中,除了函数依赖之外还有多值依赖,联接依赖的问题,从而提出了第四范式,第五范式等更高一级的规范化要求。在此,以后再谈。
各位朋友,你看过后有何感想,其实,任何一本数据库基础理论的书都会讲这些东西,考虑到很多网友是半途出家,来做数据库。特找一本书大抄特抄一把,各位有什么问题,也别问我了,自已去找一本关系数据库理论的书去看吧,说不定,对各位大有帮助。说是说以上是基础理论的东西,请大家想想,你在做数据库设计的时候有没有考虑过遵过以上几个范式呢,有没有在数据库设计做得不好之时,想一想,对比以上所讲,到底是违反了第几个范式呢?我见过的数据库设计,很少有人做到很符合以上几个范式的,一般说来,第一范式大家都可以遵守,完全遵守第二第三范式的人很少了,遵守的人一定就是设计数据库的高手了,BCNF的范式出现机会较少,而且会破坏完整性,你可以在做设计之时不考虑它,当然在ORACLE中可通过触发器解决其缺点。以后我们共同做设计之时,也希望大家遵守以上几个范式。
详解身份证验证规则

今天来说说身份证验证规则到底是怎么验证的,原理是什么,希望看完本篇你能正确的去理解身份证验证背后的规则。
身份证号码的编码规则
身份证号码共18位,由17位本体码和1位校验码组成。
身份证最后一位是根据前面十七位数字码,按照ISO 7064:1983.MOD 11-2校验码计算出来的检验码。作为尾号的校验码,是由号码编制单位按统一的公式计算出来的,如果某人的尾号是0-9,都不会出现X,但如果尾号是10,那么就得用X来代替,因为如果用10做尾号,那么此人的身份证就变成了19位,而19位的号码违反了国家标准,并且我国的计算机应用系统也不承认19位的身份证号码。Ⅹ是罗马数字的10,用X来代替10,可以保证公民的身份证符合国家标准。
前6位是地址码,表示登记户口时所在地的行政区划代码,依照《中华人民共和国行政区划代码》国家标准(GB/T2260)的规定执行;7到14位是出生年月日,采用格式;15到17位是顺序码,表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编订的顺序号,顺序码的奇数分配给男性,偶数分配给女性,即第17位奇数表示男性, 偶数表示女性;
第18位是校验码,采用ISO 7064:1983, MOD 11-2校验字符系统,计算规则下一章节说明。
一代身份证与二代身份证的区别在于:
一代身份证是15位,二代身份证是18位;一代身份证出生年月日采用YYMMDD格式,二代身份证出生年月日采用格式;一代身份证无校验码,二代身份证有校验码。校验码计算规则
身份证号码中各个位置上的号码字符值应满足下列公式的校验:
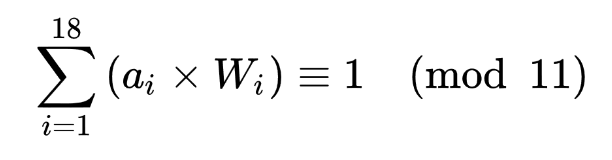
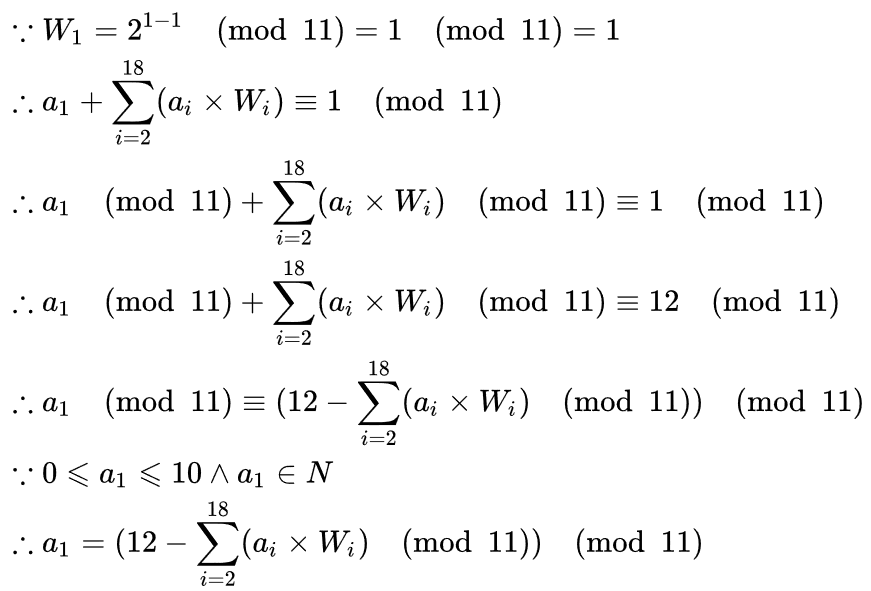

下面通过两种方法用某个真实的男性身份证号(5 3 3 2 2 3 1 9 6 3 0 1 0 5 0 9 1 7)来进行通俗易懂的说明身份证验证规则。
方法一(余数对应法)
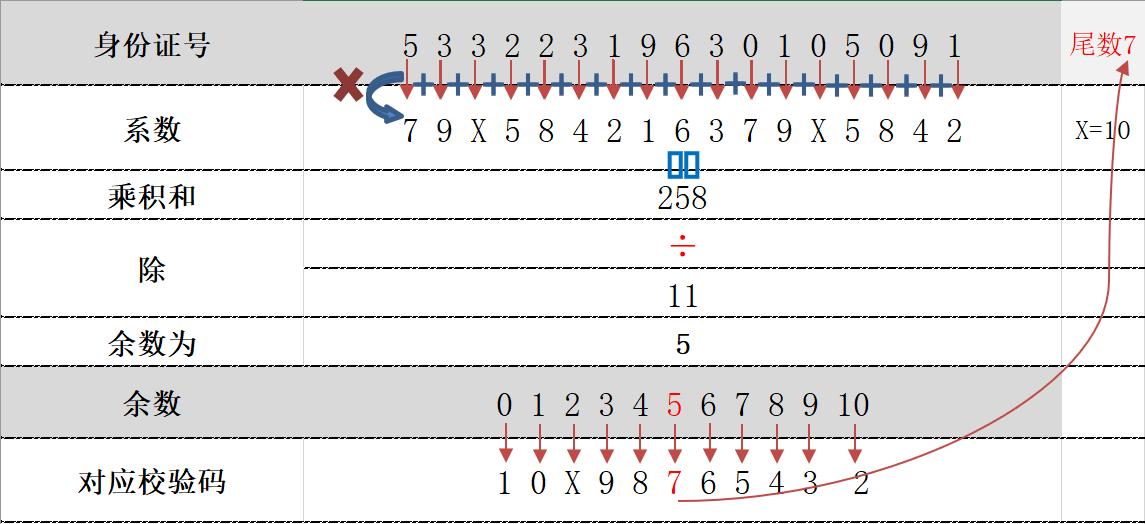
将前面的身份证号码17位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2;将这17位数字和系数相乘的结果相加;用加出来的和除以11,看余数是多少;余数只可能有0 1 2 3 4 5 6 7 8 9 10这11个数字。其分别对应的最后一位身份证的号码为1 0 X 9 8 7 6 5 4 3 2;
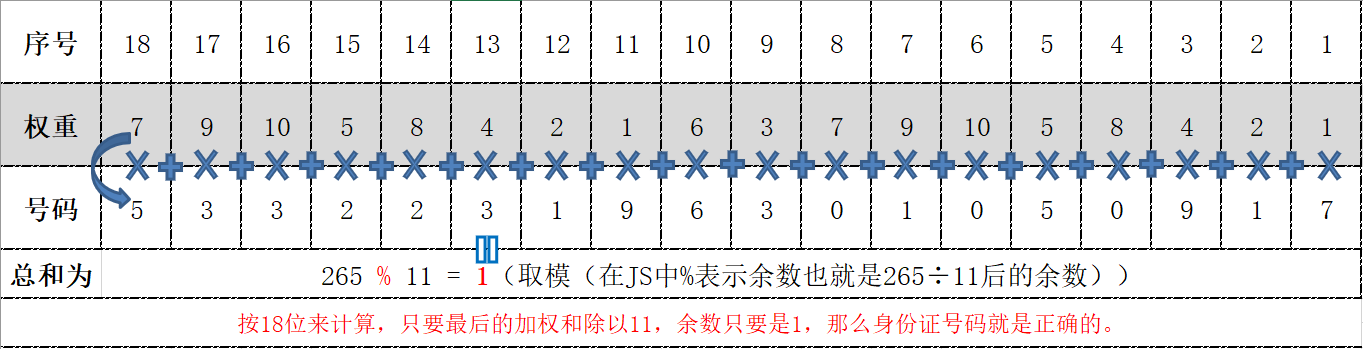
方法二(十八位加权余一法)
按照18位来计算,第一位数的权重是07,第二位是09(见下表)序号从右向左,只要最后的加权和除以11,余数只要是1,那么身份证号码就是正确的。
注意:如果身份证号码第18位是X,那么就按10计算。
其中5 X 7=35,3 X 9=27,3 X 10=30,其余以此类推,
加权求和=35+27+30…..2+7=265;265 % 11其余数是1,所以这个号码是正确的。

用JS实现二代身份证的验证
理解了原理和校验规则开始下手敲起来:
<script type="text/javascript">
/**
* 以下身份证验证适用于18位的二代身份证号码,身份证通常是由17位本体码和1位校验码组成。
**/
function validateIdCard(idCard) {
//15位和18位身份证号码的正则表达式
var regIdCard = /^(^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$)|(^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])((\d{4})|\d{3}[Xx])$)$/;
//如果通过该验证,说明身份证格式正确,但准确性还需计算
if (regIdCard.test(idCard)) {
if (idCard.length == 18) {
var idCardWi = new Array(7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2); //将前17位加权因子保存在数组里
var idCardY = new Array(1, 0, 10, 9, 8, 7, 6, 5, 4, 3, 2); //这是除以11后,可能产生的11位余数、验证码,也保存成数组,10代表X
var idCardWiSum = 0; //用来保存前17位各自乖以加权因子后的总和
for (var i = 0; i < 17; i++) {
idCardWiSum += idCard.substring(i, i + 1) * idCardWi[i];
}
var idCardMod = idCardWiSum % 11;//计算出校验码所在数组的位置
var idCardLast = idCard.substring(17);//得到最后一位身份证号码
//如果等于2,则说明校验码是10,身份证号码最后一位应该是X
if (idCardMod == 2) {
if (idCardLast == "X" || idCardLast == "x") {
return "身份证号码验证通过!";
} else {
return "您输入的身份证号码有误!";
}
} else {
//用计算出的验证码与最后一位身份证号码匹配,如果一致,说明通过,否则是无效的身份证号码
if (idCardLast == idCardY[idCardMod]) {
return "身份证号码验证通过!";
} else {
return "您输入的身份证号码有误!";
}
}
}
} else {
return "您输入的身份证格式不正确!";
}
}
var inputs =validateIdCard(prompt());
var ids = document.getElementById("ids").innerHTML=inputs;
</script>参考资料
*请认真填写需求信息,我们会在24小时内与您取得联系。
