整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
在这个信息化的时代,网络已经成为我们生活中不可或缺的一部分。无论是工作还是娱乐,网络的稳定性都显得尤为重要。然而,有时候我们会遭遇一种让人感到无奈的情况——网络代理IP服务器连接失败。就像一只飞不起来的鸟,心里明明渴望自由,却被现实的桎梏所限制。这种失落感,想必每个网民都曾体验过。

什么是网络代理IP?
在深入探讨连接失败的原因之前,我们先来了解一下什么是网络代理IP。简单来说,网络代理IP是一种中介服务,它允许用户通过代理服务器访问互联网。就好比在一个繁忙的市场中,代理服务器就像是一个经验丰富的导购员,帮助你找到想要的商品,避开那些拥挤的人群。
使用代理IP的好处多多,比如可以隐藏真实IP地址、访问被屏蔽的网站,甚至提高上网速度。可当这个“导购员”突然失联,连接失败时,我们就会感到无比的困惑和无助。
连接失败的常见原因
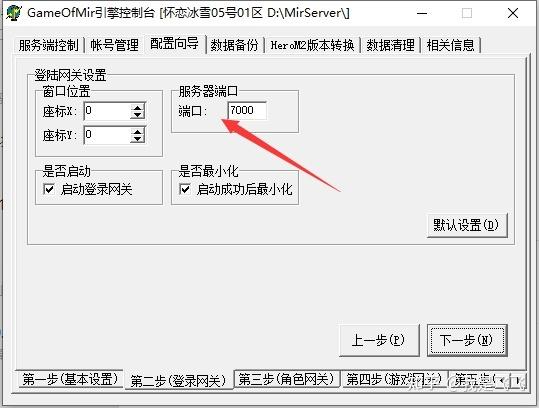
网络代理IP服务器连接失败的原因多种多样,可能是服务器本身的问题,也可能是我们使用的设备或网络设置的问题。以下是一些常见的原因:
如何解决连接失败的问题
面对网络代理IP服务器连接失败的问题,我们不能像无头苍蝇一样四处乱撞,而是要采取一些有效的措施来解决。以下是一些建议:
预防连接失败的小技巧
预防胜于治疗,想要避免网络代理IP服务器连接失败的情况,平时的一些小技巧也是必不可少的:
结语
网络代理IP服务器连接失败的情况,就像是生活中的小插曲,虽然让人感到烦恼,但只要我们认真对待,积极寻找解决方案,最终总能找到出路。记住,网络世界虽复杂,但只要我们保持耐心和细心,便能够在这片虚拟的海洋中畅游无阻。
希望每位读者在遇到网络代理IP服务器连接失败时,能够从这篇文章中找到一些启示,轻松应对,继续享受网络带来的便利与乐趣!
案例详解 DB2 执行计划的各个要点(附:DB2 实用技巧)
对于DB2数据库,很多人并不能理解执行计划所表达的含义,在此推荐一篇社区专家的文章,通过实际案例详细探讨DB2数据库中执行计划的各个要点。文后附上IBM技术团队出品的DB2 实用技巧8招,相信对大家会很有帮助。
《DB2 执行计划浅析》 作者:洪烨,专注于并擅长数据库领域。主要负责哈尔滨银行的服务器、存储、数据库的管理与维护工作。
个人主页:
在数据库调优过程中,SQL语句往往是导致性能问题的主要原因,而执行计划则是解释SQL语句执行过程的语言,只有充分读懂执行计划才能在数据库性能优化中做到游刃有余。
常见的关系型数据库中,虽然执行计划的表示方法各自不同,但执行原理却大同小异。在我看来,SQL语句的执行过程中总共包含两个关键环节:

只要掌握这两个关键环节,我们就可以迅速识别SQL语句在当前数据库中的执行逻辑,发现执行计划中存在的问题及隐患。由于不同数据库之间对于执行计划的表示方法各不相同。对于DB2数据库,很多人并不能理解执行计划所表达的含义,接下来我们就通过实际案例详细探讨DB2数据库中执行计划的各个要点。
读取数据的方式
谈到读取数据就离不开数据库中的物理对象:表及索引。因此谈到数据读取的方式,只需理解表扫描及索引扫描,就能基本把握数据的来源。
全表扫描
在DB2 LUW中可以通过四种方式获取语句的执行计划(工具),虽然工具不同,但展示的内容基本相似,最大的区别就是详细程度。详细程度由大到小排序分别是:。为了方便展示,我们在这里只讨论通过所展示的执行计划信息。首先我们来看一个抓取的完整的执行计划。
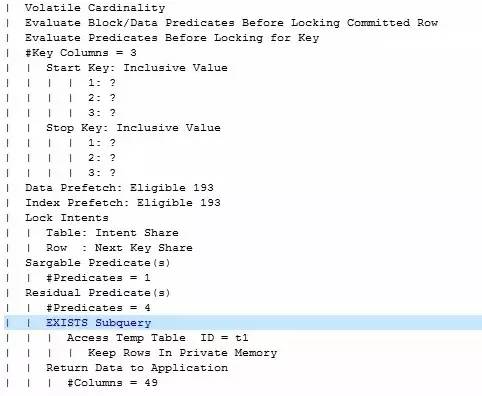
展示的信息总共分为三部分,分别是当前SQL 语句,执行计划详细信息及执行计划图示(需添加-g参数才能展示),第一部分是当前采集执行计划的语句(见图1-1):
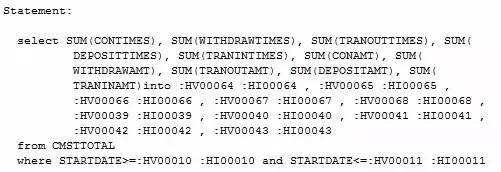
这部分内容基本一目了然,需要注意的就是里面:HV … :HI… 的信息是DB2将参数改写的信息(基本可以忽略)。
接下来我们来看最关键的部分,执行计划的详细信息(见图1-2):

这部分首先包括当前环境的字符集(),下面是根据统计信息评估出的成本及返回行数。在这个例子中执行成本为124470,返回行数为1行。从第6行开始的位置内容比较重要,我们采取逐行解释:


第三部分为执行计划图,我们可以通过执行计划图快速直接地看出SQL语句的执行过程,执行计划图的阅读顺序是从下往上,从左往右,按照编号从大到小的顺序进行阅读。比如在这个例子中,首先看第三步,显示对表进行表扫描操作(TBSCAN),然后对扫描的结果进行group by操作并将最终结果返回,这条SQL语句就执行完毕了。

索引扫描
接下来来看个索引扫描的例子,为了快速理解这个执行计划,我们直接先看执行计划图,可以看到这个SQL语句首先读取索引,获取RID后到表里获取其他数据,进行group by后将结果返回。

其他部分和上一个例子差不多,就不一一详细介绍了,主要看索引扫描的相关细节。从下面的信息可以看出用到的索引中包含4个字段,但这条SQL只用到了一个字段。其他三个字段都没用使用。如果该表上有其他索引包含这条SQL所使用的更多的字段时,这个索引肯定不是最佳选择。

数据读取的方式还有更多的细节,这里暂时不一一讨论了,但不论对数据采用何种方式读取,最核心的内容还是数据从哪里读取,简单来说就是有没有更好的索引可以替代当前的扫描策略,所以,当我们对SQL语句进行优化时,第一步就是需要考虑当前的读取方式是否足够有效。
表连接的方式
接下来我们来谈表之间的连接,写过SQL的童鞋都知道,写SQL时Join方式可以有很多种情况:inner join,left join,right join,full join等,还包括一些子查询,比如exist 或者In等方式。对于星型查询,DB2 10以后还支持ZZJOIN。
Nest Loop(NLJOIN)
Nest Loop是最简单的一种连接方式,数据库会根据表中的记录数选择内表及外表,在定义内外表后,首先会对外表进行全表扫描,然后重复扫描内表并与外表中的每一条记录进行匹配,最终返回程序所需的结果集。

因此NLJOIN的总成本大约为外表扫描的成本+外表返回的行数×内表扫描的成本。NLJOIN作为使用场景最多的连接方式,当外表匹配行数较少或内外表行数差距较大时效率较高,但也正因为NLJOIN的运行方式,也经常会发生性能隐患.
Merge Join(MSJOIN)
合并连接是为了解决Nest Loop中存在的一些问题所采用的一种连接方式,MSJOIN会将需要连接的两张表进行排序,并将排序后的结果集按照交叉方式匹配,最终返回连接后的结果。
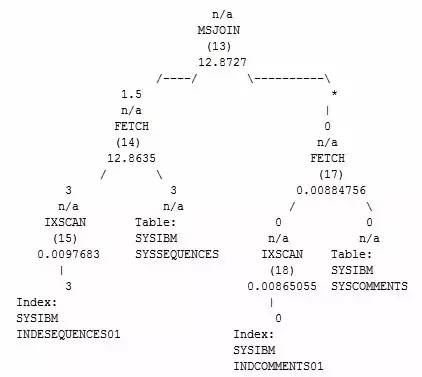
MSJOIN的总成本大约为单次外表扫描的成本+单次内表扫描的成本+排序成本。MSJOIN常见的场景通常是SQL需要返回排序结果,亦或者主外表都比较大的情况,此外MSJOIN只能应用于SQL语句中包含唯一连接谓词的情况,当主外表数量级都比较大,且连接谓词上都存在索引时,MSJOIN的效率较高(避免了排序成本),通常MSJOIN比较稳定,即使统计信息估算错误,也不会导致执行效率出现较大的偏差。
Hash join(HSJOIN)
HSJOIN是一种比较高级的连接方式,进行连接前首先会将外表根据连接谓词进行哈希产生哈希表,然后将哈希表与内表进行连接并返回结果。与MSJOIN类似,HSJOIN也只对内外表分别进行一次扫描,同时HSJOIN也支持多连接谓词。在两张大表通过多连接谓词进行连接时效率很高。
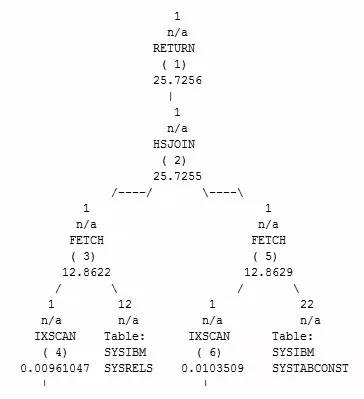
HSJOIN的扫描成本约为内表扫描成本+外表扫描成本。但需要注意的是,生成的哈希表会存放在排序堆中,一旦排序堆内存溢出,会额外产生大量的物理IO,这点需要特别注意。
半连接(semi-join)
半连接属于一种比较奇怪的连接方式,在很多资料里并没有将其划分到连接方式中,因为有的时候,从执行计划中根本看不到连接操作符,比如下面这个SQL:
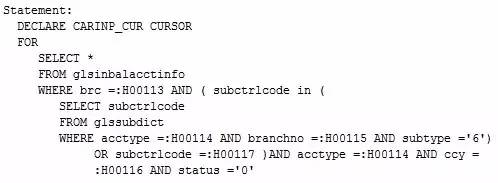
这是一个典型的子查询,我们可以从SQL语句中猜出大概逻辑,首先会读取子查询中的表,然后根据返回的内容与外部表进行匹配并返回结果。但从执行计划图中并不能看到任何关于连接的信息。

执行计划图中并没有显示任何join的信息,只是多个对象进行了fetch,但从文字描述中可以看到更详细的内容。
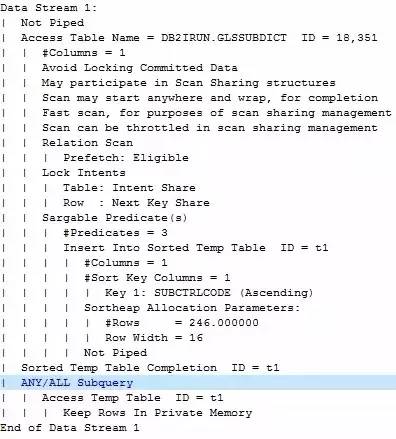
数据流1首先会对内部表进行全表扫描(ANY/),读取后的结果与外部表进行匹配,匹配到结果后不继续扫描立刻返回结果(EXISTS )。
多表间的连接顺序选择
不论在同一条SQL语句中包含了多少张表连接,在同一时刻只有两张表进行连接,但多表间的连接顺序也是决定性能的主要原因。数据库对于表的顺序的选择,往往根据两个表之间连接后得出的行数进行排序,如果统计信息与实际情况偏差较大,有可能会导致由于连接顺序不当而导致的性能问题。
10
总结
通过对执行计划的解析,我们讲解了SQL执行过程中对于性能影响较大的各个要点,但如何在生产上保持SQL的高效稳定,还需对执行计划进行更深入的理解。 再解答一些常见的疑问:
Q & A
Q1:在查询时,有一个驱动表,通常是from后的第一个表,后面一堆左连接右连接,这个驱动表如何选择?对性能有影响么?自己人为该顺序不会影响执行计划?
A1:在数据库中,会根据当前表的情况进行内外表的选择,SQL语句中的写法只能从一定程度上决定连接次序,但不会做连接中内外表的决策。
举个例子, a,( b,c where b.id=c.id)where……,比如这个SQL,在写法中指明了需要先将b c表连接,再与a表连接,但在连接时候的方式以及连接时候内表外表的选择,都由数据库决定。
-----------
Q2:关于连接方式的选择,是由连接的两个表和连接的字段是否排序决定的?
A2:这个不绝对,但是会作为选择的因素之一。
-----------
Q4:访问某表的access plan改变了,统计信息没变,是什么情况?这是优化器自动调整了吗?可是优化器根据统计信息生成访问计划,按道理应该是不会变的啊?
A4:执行计划的选择会根据数据库参数,统计信息作为参考,但在编译过程中数据库还会收集一些物理信息。比如数据的物理分布可能会对扫描的方式产生影响。
-----------
Q5:这个物理信息是什么,是表空间信息吗?
A5:表在物理中存放的情况。
-----------
Q6:有什么手段跟踪一个SQL完整的执行过程,包括你说的动态收集物理信息?
A6:可以抓trace或者stack。db2trc,和db2pd –stack。
-----------
Q7:老师,db2的优化器是对越复杂的sql支持的越好吗?有这个说法吗?
A7:db2的优化器对复杂SQL的支持在关系型数据库里应该是最好的,但是对于联机交易系统来讲,我觉得SQL的稳定性比较重要。但复杂SQL牵扯到的变化因素太多,任何一个表的统计信息改变都有可能导致SQL性能下降,所以在联机交易系统不太推荐写复杂SQL。
-----------
Q8:那我们写sql时该怎么注意呢?NL join类似笛卡尔集,时间复杂度最高,其次是merge。我觉得从sql上避免不了,因为选择了那个列,就基本确定了连接类型。
A8:在编写SQL的时候很难决定用什么连接方式,但有些需要注意的地方,比如避免多张大表连接,这些在开发过程中还是可以办到的。
-----------
Q9:hash连接,如果探测表很大,内建表很小,hash的成本显示很高,因为探测表做了表扫描,没有用到索引,这种如何优化,只能减少探测表的返回集吗?
A9:可以在探测表上创建适当索引。
-----------
Q10:对表做完统计更新后需要做rbind吗?
A10:这个需要取决于你的应用是静态SQL还是动态SQL。静态SQL的话执行计划在bind的时候保持在数据库中,统计信息更新后建议rebind,但动态的就没必要了。
-----------
Q11:通常谓词出现在索引的第一个字段应该就是有效索引,可有时候这个索引存在,但是个复合索引,跑时却建议在这个谓词上创建新的单一的索引,为什么数据库不用现有的复合?
A11:复合索引并不一定高效,这个需要根据数据分布来判断,如果单一索引的非常好(也就是和表存放的顺序匹配度非常高),这样可以用到大量预取操作,性能会比同步读好很多。
-----------
Q12:嵌入式C、C++、COBOL的包BND(包括静态SQL),要绑, 用户SP也建议绑定吧?
A12:UDI的成本其实很大程度上和表设计有关。比如在做DML语句的时候发生行溢出和页重组,带来的消耗远大于插入索引。相关信息可以看db2pd -tcb或者 for table。
-----------
Q13:请问一下对于表压缩有什么建议?比如要做大表的压缩,有没有一些量化指标供参考,因为有一些表开了压缩批次插入较多记录时候影延长了批次1/3的时间。
A13:对于压缩,需要分析当前数据库的瓶颈在哪。压缩是以cpu为代价降低磁盘io,如果瓶颈在磁盘io上,肯定会有帮助,但如果瓶颈在cpu上只会雪上加霜。
-----------
Q14:调整呢?有没有量化的一些指标?
A14:这个不是很好量化。对于磁盘io瓶颈,可以先从索引,语句甚至表设计入手。如果都已经调整到很好了但还是存在iO瓶颈,同时CPU使用率又比较低(30-40以下)。可以考虑压缩。
(本文由作者授权发布)
DB2 实用技巧八招
*请认真填写需求信息,我们会在24小时内与您取得联系。
