整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:

天天在用钱

作者 |朱顺意
出品 | 脚本之家(ID:jb51net)
也许有的人在数字营销行业已经很长时间,天天和各种各样的名词打交道,但一不留神还是容易混淆一些名词,甚至很多人连java和都混为一谈。一起来看看容易混淆的都有哪些:
01
h5和html5
平时我们常说的h5是指移动端网页(包括pad和phone),因为网页涉及到html5的代码规范,所以大家习惯了叫h5。但实际上h5与html5并不是完全一个意思,你会听到人家说“这个h5挺炫”,而不会听到“这个html5挺炫”。
准确来说,html5是html的一种规范,文档类型声明、标签语义化、功能比以往的html更便捷更强大;h5是通常指移动端网页,例如手机上的活动页、专题页。
h5还有另一种含义,就是h5标题标签。在SEO工作中,h1标题标签包裹的关键词会被强化SEO效果(仅次于title标签),h2-h6次之。

02
前端就是离用户视觉最近的一面,例如样式(颜色/图片/大小/宽高/布局)、交互(下拉/隐藏/渐变/动画),常用技术包括html/css/;后端就是服务器数据传输、网络安全,通常用户接触不到,常用技术包括PHP/Python/Java等等。
拿一个新闻网站来举例,前端负责页面的布局、文字大小颜色等等,后端负责把数据库的新闻内容、新闻时间等按一定顺序在页面呈现,所以前后端实际上是互相合作的关系。近年来流行的“前后端分离”,并不是指前后端不再合作,而是通过API来解耦前端和后端。
在数字营销也会有人把广告监测称为前端,网站、小程序、APP监测称为后端,甚至有人把销售称为前端,运营称为后端。
03
自适应和响应式
乍一看这好像没有什么区别,自适应和响应式都能让页面适应不同的屏幕尺寸,不同的是,自适应要先通过判断当前设备是PC、平板还是手机,然后再去请求服务器给予不同的页面模板,而响应式是可以随着当前浏览器可视区域的大小而实时改变布局。
换句话来说,自适应需要做PC、平板、手机这3种页面模板,对应的宽度分别是>=1200px(PC大屏幕)、>=992px(PC中等屏幕)、>=768px(平板)、而响应式只需要做一个页面模板,自由改变布局。
如果你还有疑问,打开以下网站调整浏览器的宽度,对比一下布局就明白了:
自适应:
响应式:

04
动态页面和静态页面
这2者不能单纯以页面有无动态效果(例如动画)来区分,而要看数据有没有从服务器端查询。也不能以网址有没有包含“?”来区分动静态网页,在数字营销中“”表示用户来源于百度,但并不代表这个页面是动态的。
常见动态网页的网址后缀常为.asp/.jsp/.php/.perl/.cgi,页面内容是通过后端语言(例如java)去请求服务器连接数据库拿到的;静态页面的网址后缀常为.html/.htm/.xml/shtml,页面内容是固定写在页面上的。当然动态页面也可以通过伪静态以实现网址以.html等结尾。
所以,只通过浏览器查看源代码,是不能判断页面为动态还是静态的。
05
第1方cookie和第3方cookie
这两者本质上没有什么区别,都是cookie,为存放在本地的文本文件,所谓的第1方和第3方只是身份说明。cookie 有 domain 属性,当 cookie 的 domain 与当前地址栏的域名不同时,这个 cookie 为第3方 cookie,反之为第1方 cookie。
由于 domain 的不同,第1方 cookie 记录的是用户在指定站点的行为,第3方 cookie 记录的是用户在不同站点的行为。监测工具为你的站点创建了第1方 cookie,这个 cookie 的domain 属于你的站点,仅能用于记录你站点的用户行为,同时监测工具也创建了第3方 cookie,这个 cookie 的domain 属于监测工具,这个 cookie 用于记录所有部署了它的监测代码的站点数据。

关于这2者的详细说明,我在另一篇文章《如何用Chrome读懂网站监测Cookie》有写到。
06
openID和unionID
这2者在微信生态都用于标识用户,openid是用户在某一应用下的唯一标识,例如同一个用户在A小程序和B小程序是2个不同的openid。然而,同一用户在同一个微信开放平台账号下的不同应用(移动应用、网站应用、公众号、小程序),unionid是相同的。
虽然有2个天然标识用户的ID,但在微信小程序监测中,很多第3方工具会通过wx.以键值对的形式创建具有唯一性的用户ID,这个ID会一直稳定存在,除非用户主动删除或因存储空间原因被系统清理。
07
、MAC地址、IMEI、OAID
这几种都是安卓设备ID。的获取不需要用户授权,在Android 8.0及以上,由应用签名、用户和设备三者的组合,而不直接为设备唯一标识;
MAC地址属于硬件ID,具有唯一性,涉及用户隐私;
IMEI为国际移动设备识别码,具备唯一性(当然也要考虑双卡双待的情况)。在Android 6.0以上,IMEI的获取需要用户授权,也可以通过拨打*#06#查询。
由于IMEI已被认定为用户隐私的一部分,Android 10.0起将彻底禁止第三方应用获取设备的IMEI,从而中国信通院联合国内手机厂商共同推出新的设备识别字段 - OAID,OAID为匿名设备标识符,用户可以禁用、重置。

08
api和sdk
api是指一个功能或者一个函数,我们把相关参数传入,调用api然后由它返回数据(返回的形式通常是json),例如使用谷歌天气预报api时,传入城市id和日期等参数,然后谷歌会返回天气、温度、湿度、舒适指数等信息。

SDK是一个或多个文件的组合(包括代码文件也包括文档),是一种工具包,下载之后可以嵌入你的网页或移动应用,由sdk去调用api实现具体功能,例如嵌入第三方的广告SDK接入联盟广告。所以说,SDK通常会包含很多不同的API。
09
维度和指标
简单来说,维度和指标的关系是:以维度查看指标。
维度是指数据的属性、特征或范围,例如城市、设备、浏览器、时间、广告来源等等。当1个维度后面关联第2个维度时,第2个维度被称为次级维度,例如需要统计城市为北京、手机为苹果的浏览量时,手机为次级维度。
指标是计算数值或者计算结果,例如浏览量、会话量、用户数、访问时长、跳出率、退出率等等。当然也不能把所有数值都当成指标,例如第1天签到了100人,第2天签到50人,那么第1天、第2天是维度,100人、50人才是指标。
10
ecpm、cpm、ocpm
ecpm是指广告每展现1千次,媒体所获得的收入,这个指标用于衡量媒体的广告盈利能力;cpm指的是广告每展现1千次,广告主所付出的成本。看上去好像2个指标是一样,实际上如果一种广告背后是cpc、cpt、cpm等几种计费方式,此时计算ecpm则需要进行换算。

ocpm是在广告投放中,一种以转化为优化目标的展现出价,也就是说按转化出价,计费方式为展现计费。同样的道理,ocpc也是按转化出价,计费方式为点击计费。无论是ocpm还是ocpc的投放方式,广告展现胜出的能力还是要看ecpm,也就是要看1次转化所花的钱换算成千次展现收入是多少。
也许你还听说过ecpc,ecpc也是一种投放方式,有的人叫点击出价系数控制,是指你设置一个出价系数区间,系统会根据流量转化率动态调整出价,优化转化效果。
11
跳出率和退出率
跳出率(Bounce Rate)是落地页指标,跳出率=跳出次数/访问次数。跳出次数是指用户来到网站,没有任何交互就离开的访问次数。至于是否有交互,要以监测工具是否收到监测请求为准,需要注意的是一般监测工具的热力图请求不参与跳出率的计算。
退出率(Exit Rate)则是退出页面(离开网站前浏览的最后1个页面)的指标,退出率=退出次数/页面浏览量。退出次数是指作为退出页面的次数,当然如果用户访问的最后一个页面还触发了虚拟PV,那么此时退出页面为虚拟PV页面。
12
KOL和KOC
KOL(Key Opinion Leader)是关键意见领袖,指某个领域的专家、名人、明星,在相关用户群体有较大影响力;KOC(Key Opinion )是关键意见消费者,指通过自身试用推荐影响身边消费者的素人、爱好者。
KOC虽然知名度不高,但是离消费者更近,与消费者互动效果也更强。KOC概念的产生,是由于随着流量的稀缺,商家从花钱在大平台买流量到利用熟人关系推介产品转变,提高效果的同时也降低了营销门槛。

13
无埋点/全埋点、可视化埋点、代码埋点
无埋点也叫全埋点,是指SDK部署到产品(网页、小程序、APP)之后,将自动监听用户的各种行为,并且全部上报给监测工具,随后分析人员通过监测工具的可视化面板将需要的数据按组件(按钮、图片、链接等等)进行圈选。这种方式比较方便,但由于采集的数据实在太多,难免有丢包的情况,以及会存在明显的数据冗余;
可视化埋点是先通过可视化面板将需要统计数据的组件进行圈选,备注监测信息,然后等待数据回传,跟无埋点/全埋点的顺序刚好相反。这种方式相对精确,但是有些交互难以通过圈选的方式来指定(例如下拉刷新);
代码埋点则为根据统计目的,提前把监测代码交给开发人员配置到产品,代码内容一般包括触发条件、事件维度、事件指标等等,这种监测方式比较准确但是工作量也比较大。
简言之,无埋点/全埋点:全部上报 -> 可视化圈选 -> 下载数据;可视化埋点:可视化圈选 -> 上报数据 -> 下载数据;代码埋点:配置代码 -> 上报数据 -> 下载数据。
机器学习基础之《回归与聚类算法(4)—逻辑回归与二分类(分类算法)》
一、什么是逻辑回归
1、逻辑回归( )是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛
2、叫回归,但是它是一个分类算法
二、逻辑回归的应用场景
1、应用场景
广告点击率:预测是否会被点击
是否为垃圾邮件
是否患病
金融诈骗:是否为金融诈骗
虚假账号:是否为虚假账号
均为二元问题
2、看到上面的例子,我们可以发现其中的特点,那就是都属于两个类别之间的判断。逻辑回归就是解决二分类问题的利器
会有一个正例,和一个反例
三、逻辑回归的原理
1、逻辑回归的输入
线性回归的输出,就是逻辑回归的输入
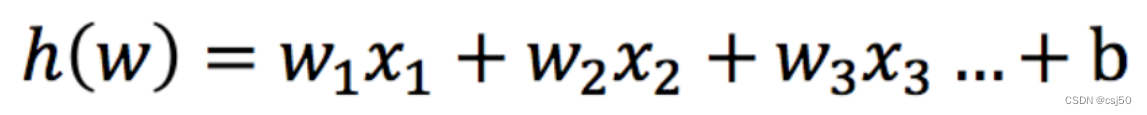
逻辑回归的输入就是一个线性回归的结果
2、怎么用输入来分类
要进行下一步处理,带入到sigmoid函数当中,我们把它叫做激活函数
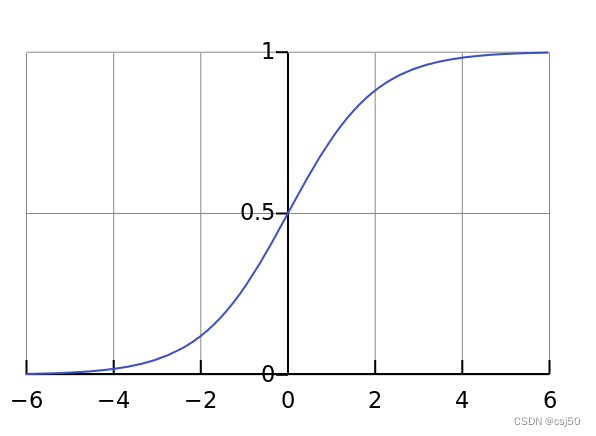
3、sigmoid函数
可以理解为,f(x)=1/(1+e^(-x)),1加上e的负x次方分之1
sigmoid函数又称S型函数,它是一种非线性函数,可以将任意实数值映射到0-1之间的值,通常用于分类问题。它的表达式为:f(x)=1/(1+e^(-x)),其中e为自然对数的底数。它的输出值均位于0~1之间,当x趋向正无穷时,f(x)趋向1;当x趋向负无穷时,f(x)趋向0
4、分析
将线性回归的输出结果,代入到x的部分
输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
5、假设函数/线性模型
1/(1 + e^(-(w1x1 + w2x2 + w3x3 + ... + wnxn +b)))
如何得出权重和偏置,使得这个模型可以准确的进行分类预测呢?
6、损失函数(真实值和预测值之间的差距)
我们可以用求线性回归的模型参数的方法,来构建一个损失函数
线性回归的损失函数:( - y_true)平方和/总数,它是一个值
而逻辑回归的真实值和预测值,是否属于某个类别
所以就不能用均方误差和最小二乘法来构建
要使用对数似然损失
7、优化损失(正规方程和梯度下降)
用一种优化方法,将损失函数取得最小值,所对应的权重值就是我们求的模型参数
四、对数似然损失
1、公式
逻辑回归的损失,称之为对数似然损失
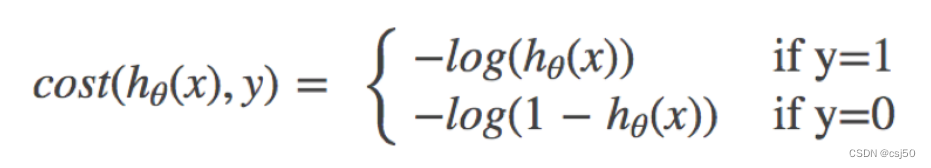
(1)它是一个分段函数
(2)如果y=1,真实值是1,属于这个类别,损失就是 -log(y的预测值)
(3)如果y=0,真实值是0,不属于这个类别,损失就是 -log(1-y的预测值)
2、怎么理解单个的式子呢?这个要根据log的函数图像来理解
当y=1时:(横坐标是y的预测值)
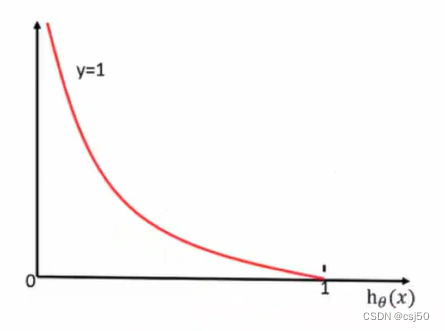
前提真实值是1,如果预测值越接近于1,则损失越接近0。如果预测值越接近于0,则损失越大
当y=0时:(横坐标是y的预测值)
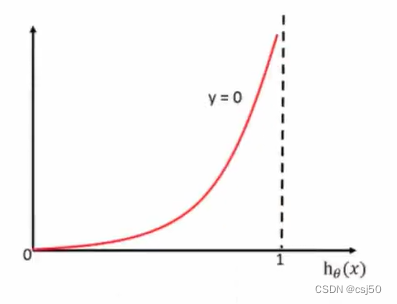
前提真实值是0,如果预测值越接近1,则损失越大
3、综合完整损失函数
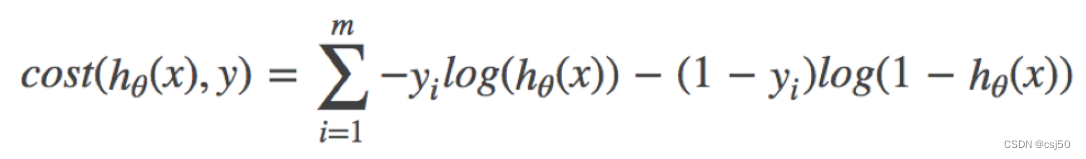
损失函数:-(y真实*logy预测+(1-y真实)*log(1-y预测)),求和
是线性回归的输出,经过sigmoid函数映射之后的一个概率值
4、计算样例

五、优化损失
同样使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率
六、逻辑回归API
1、sklearn..(solver='', penalty='l2', C=1.0)
solver:优化求解方式(默认开源的库实现,内部使用了坐标轴下降法来迭代优化损失函数)
auto:根据数据集自动选择,随机平均梯度下降
penalty:正则化的种类
C:正则化力度
2、方法相当于(loss="log", penalty=" ")
是一个分类器
实现了一个普通的随机梯度下降学习,也支持平均随机梯度下降法(ASGD),可以通过设置average=True
而使用它的优化器已经可以使用SAG
七、案例:癌症分类预测-良 / 恶性乳腺癌肿瘤预测
1、数据集
数据:
数据的描述:
2、数据的描述
# Attribute Domain
-- -----------------------------------------
1. Sample code number id number
2. Clump Thickness 1 - 10
3. Uniformity of Cell Size 1 - 10
4. Uniformity of Cell Shape 1 - 10
5. Marginal Adhesion 1 - 10
6. Single Epithelial Cell Size 1 - 10
7. Bare Nuclei 1 - 10
8. Bland Chromatin 1 - 10
9. Normal Nucleoli 1 - 10
10. Mitoses 1 - 10
11. Class: (2 for benign, 4 for malignant)第一列:样本的编号
第二到十列:特征
第十一列:分类(2代表良性,4代表恶性)
3、流程分析
(1)获取数据
读取的时候加上names
(2)数据处理
处理缺失值
(3)数据集划分
(4)特征工程
无量纲化处理—标准化
(5)逻辑回归预估器
(6)模型评估
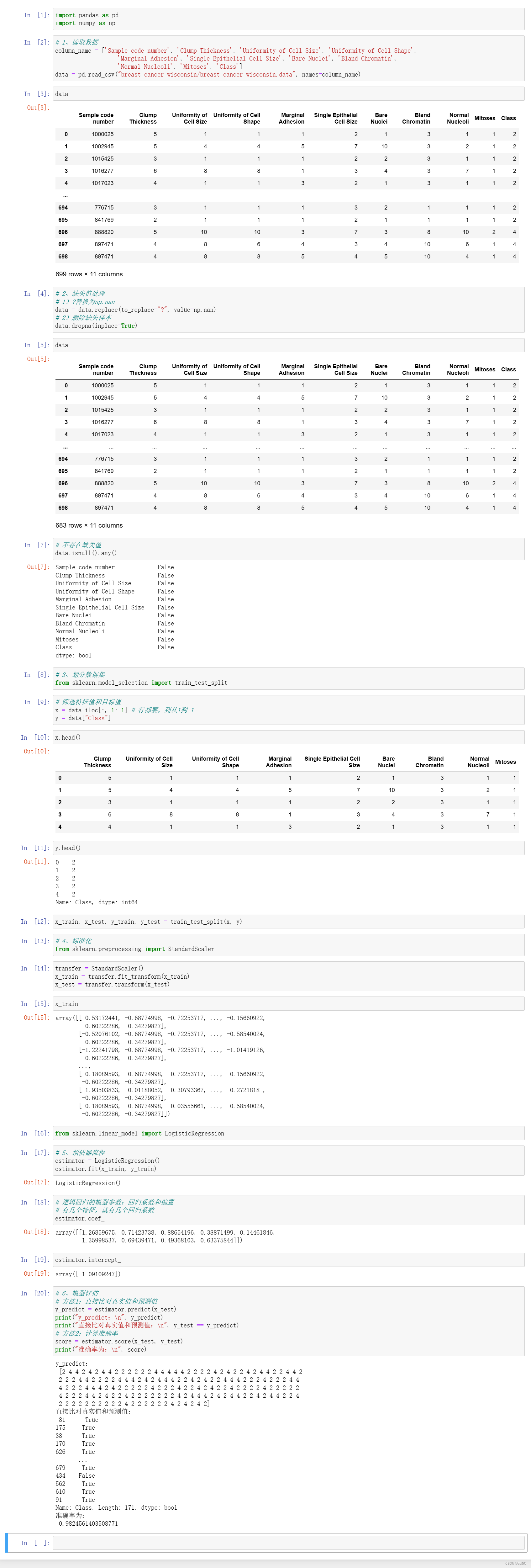
4、代码
import pandas as pd
import numpy as np
# 1、读取数据
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column_name)

data
# 2、缺失值处理
# 1)?替换为np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失样本
data.dropna(inplace=True)
data
# 不存在缺失值
data.isnull().any()
# 3、划分数据集
from sklearn.model_selection import train_test_split
# 筛选特征值和目标值
x = data.iloc[:, 1:-1] # 行都要,列从1到-1
y = data["Class"]
x.head()
y.head()
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 4、标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
x_train
from sklearn.linear_model import LogisticRegression
# 5、预估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 逻辑回归的模型参数:回归系数和偏置
# 有几个特征,就有几个回归系数
estimator.coef_
estimator.intercept_
# 6、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
5、运行结果
*请认真填写需求信息,我们会在24小时内与您取得联系。
