整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
什么是灰色关联分析
灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度。
通常可以运用此方法来分析各个因素对于结果的影响程度,也可以运用此方法解决随时间变化的综合评价类问题,其核心是按照一定规则确立随时间变化的母序列,把各个评估对象随时间的变化作为子序列,求各个子序列与母序列的相关程度,依照相关性大小得出结论。
灰色关联分析的步骤
灰色关联分析的具体计算步骤如下:
第一步:确定分析数列。
确定反映系统行为特征的参考数列和影响系统行为的比较数列。反映系统行为特征的数据序列,称为参考数列。影响系统行为的因素组成的数据序列,称比较数列。
(1)参考数列(又称母序列)为
(2)比较数列(又称子序列)为
第二步,变量的无量纲化
由于系统中各因素列中的数据可能因量纲不同,不便于比较或在比较时难以得到正确的结论。因此在进行灰色关联度分析时,一般都要进行数据的无量纲化处理。主要有一下两种方法
(1)初值化处理:
(2)均值化处理:
其中k kk 对应时间段,i ii 对应比较数列中的一行(即一个特征)
第三步,计算关联系数
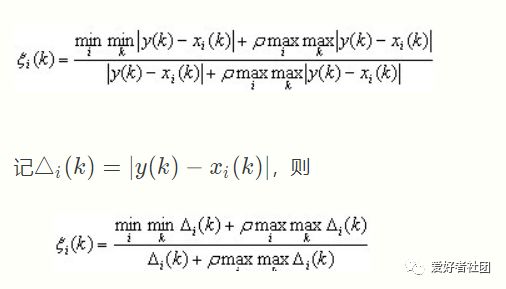
ρ∈(0,∞),称为分辨系数。ρ越小,分辨力越大,一般ρ的取值区间为(0,1) (0,1)(0,1),具体取值可视情况而定。当ρ≤0.5463时,分辨力最好,通常取ρ=0.5。
第四步,计算关联度
因为关联系数是比较数列与参考数列在各个时刻(即曲线中的各点)的关联程度值,所以它的数不止一个,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻(即曲线中的各点)的关联系数集中为一个值,即求其平均值,作为比较数列与参考数列间关联程度的数量表示,关联度ri riri公式如下:
第五步,关联度排序
关联度按大小排序,如果r1
在算出Xi(k)序列与Y(k)序列的关联系数后,计算各类关联系数的平均值,平均值ri就称为Y(k)与Xi(k)的关联度。
灰色关联分析的实例
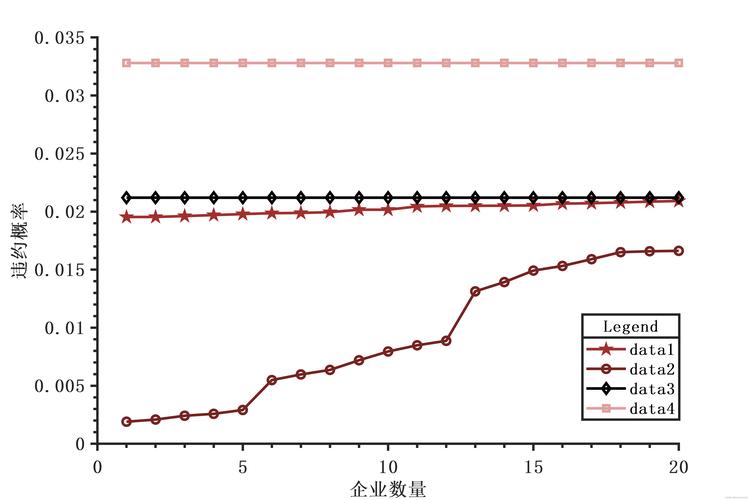
下表为某地区国内生产总值的统计数据(以百万元计),问该地区从2000年到2005年之间哪一种产业对GDP总量影响最大。
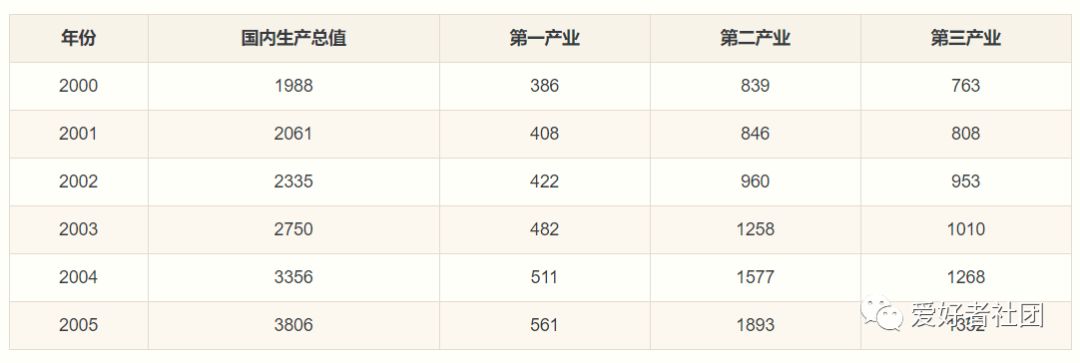
步骤1:确立母序列
在此需要分别将三种产业与国内生产总值比较计算其关联程度,故母序列为国内生产总值。若是解决综合评价问题时则母序列可能需要自己生成,通常选定每个指标或时间段中所有子序列中的最佳值组成的新序列为母序列。
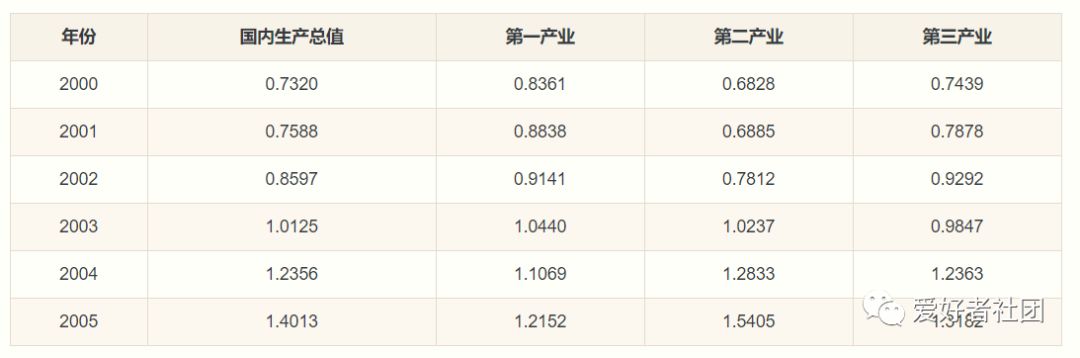
步骤2:无量纲化处理

在此采用均值化法,即将各个序列每年的统计值与整条序列的均值作比值,可以得到如下结果:
步骤3:计算每个子序列中各项参数与母序列对应参数的关联系数
其中ξi(k) 表示第i个子序列的第k个参数与母序列(即0序列)的第k个参数的关联系数,$\rho\ 为分辨系数取值范围在 为分辨系数取值范围在为分辨系数取值范围在[0,1]$,其取值越小求得的关联系数之间的差异性越显著,在此取为0.5进行计算可得到如下结果:
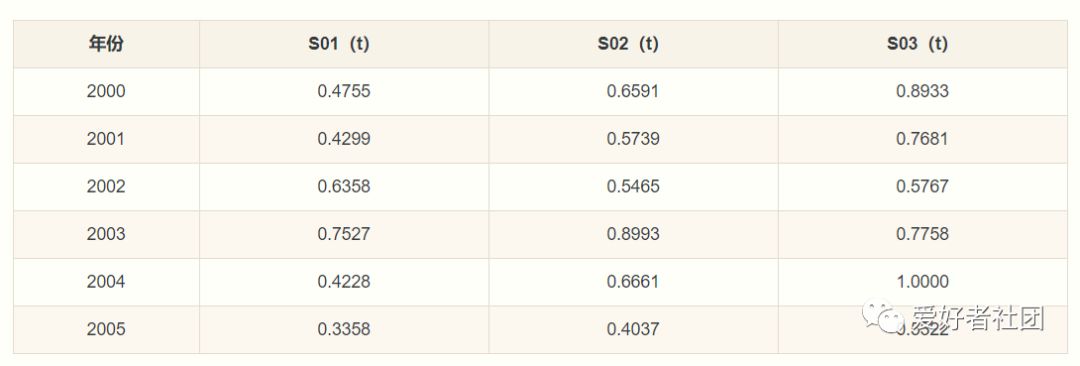
步骤4:计算关联度
用公式,
可以得到r1=0.5088,r2=0.6248,r3=0.7577通过比较三个子序列与母序列的关联度可以得出结论:该地区在2000年到2005年期间的国内生产总值受到第三产业的影响最大。
灰色关联分析matlab的实现
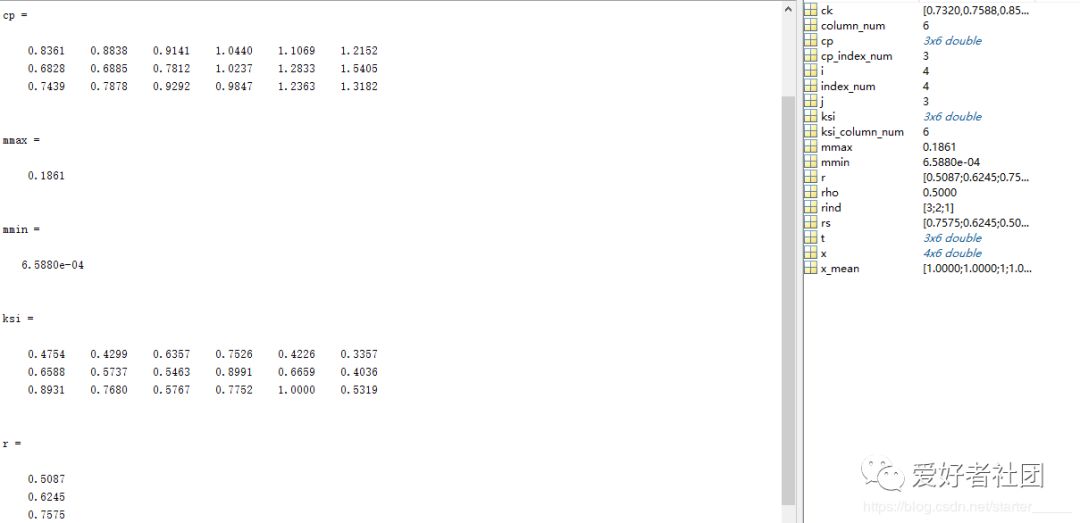
clc;close;clear all;x=xlsread('data.xlsx');x=x(:,2:end)';column_num=size(x,2);index_num=size(x,1);% 1、数据均值化处理x_mean=mean(x,2);for i = 1:index_numx(i,:) = x(i,:)/x_mean(i,1);end% 2、提取参考队列和比较队列ck=x(1,:)cp=x(2:end,:)cp_index_num=size(cp,1);%比较队列与参考队列相减for j = 1:cp_index_numt(j,:)=cp(j,:)-ck;end%求最大差和最小差mmax=max(max(abs(t)))mmin=min(min(abs(t)))rho=0.5;%3、求关联系数ksi=((mmin+rho*mmax)./(abs(t)+rho*mmax))%4、求关联度ksi_column_num=size(ksi,2);r=sum(ksi,2)/ksi_column_num;%5、关联度排序,得到结果r3>r2>r1[rs,rind]=sort(r,'descend');
运行结果:
灰色关联分析python的实现
import pandas as pdx=pd.read_excel('data.xlsx')x=x.iloc[:,1:].T# 1、数据均值化处理x_mean=x.mean(axis=1)for i in range(x.index.size):x.iloc[i,:] = x.iloc[i,:]/x_mean[i]# 2、提取参考队列和比较队列ck=x.iloc[0,:]cp=x.iloc[1:,:]# 比较队列与参考队列相减t=pd.DataFrame()for j in range(cp.index.size):temp=pd.Series(cp.iloc[j,:]-ck)t=t.append(temp,ignore_index=True)#求最大差和最小差mmax=t.abs().max().max()mmin=t.abs().min().min()rho=0.5#3、求关联系数ksi=((mmin+rho*mmax)/(abs(t)+rho*mmax))#4、求关联度r=ksi.sum(axis=1)/ksi.columns.size#5、关联度排序,得到结果r3>r2>r1result=r.sort_values(ascending=False)
Linux新建用户组g1,并设置其gid为800linux新建用户组
如何创建Linux的用户组?
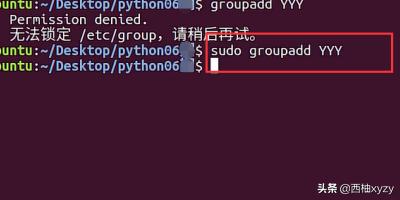
1、首先我们在Linux系统命令行中输入命令,用它创建一个用户组,如下图所示。
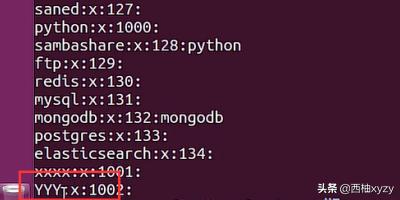
2、创建好了以后运用cat命令,打开etc下面的group文件,我们创建的用户组都会在里面,如下图所示。
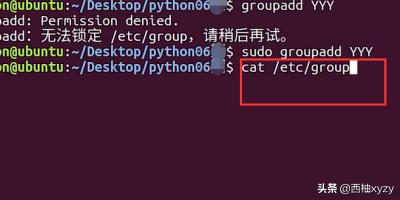
3、打开group文件以后,我们看到了刚才创建的用户组,这是鉴别用户组是否创建成功的根据。
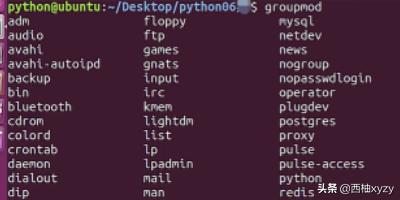
4、还可以通过在命令行中输入命令后,多敲几次tab键,终端会自动列举出当前所有的组,如下图所示。
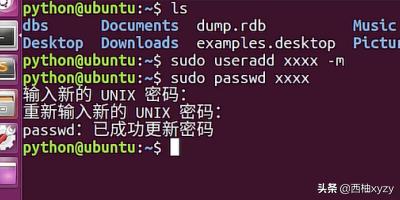
5、另外,如果你创建一个用户的时候,如下图所示,运用useradd命令创建一个用户,默认是已经创建了用户组的,用户组和用户名称一样。
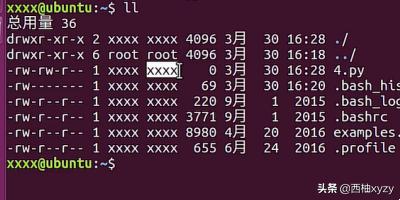
6、最后当你在创建文件的时候,你用哪个用户创建的,文件的所属组就会自动归属这个用户的所属组,如下图所示。
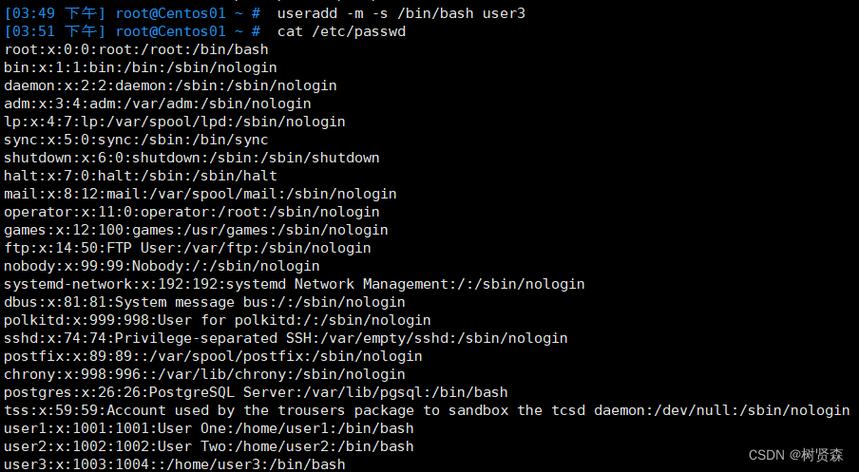
如何在Linux下添加/删除/修改,用户及用户组?
Linux删除用户组和用户时常用的一些命令和参数。
1、从组中删除用户
编辑/etc/group找到GROUP1那一行,删除A
或者用命令
gpasswd-dAGROUP
2、建用户:
//新建phpq用户
//给phpq用户设置密码
3、建工作组
//新建test工作组
4、新建用户同时增加工作组
useradd-//新建phpq用户并增加到test工作组
注::-g所属组-d家目录-s所用的SHELL
5、给已有的用户增加工作组
usermod-
或者:gpasswd-
6、临时关闭:在/etc/shadow文件中属于该用户的行的第二个字段(密码)前面加上*就可以了。想恢复该用户,去掉*即可。
或者使用如下命令关闭用户账号:
重新释放:
6、永久性删除用户账号
(强制删除该用户的主目录和主目录下的所有文件和子目录)
7、显示用户信息
iduser
cat/etc/passwd
linux用户组,和,用户的区别?
组呢,就像一个社团,用户呢就像成员,一般linux下创建用户默认是自动给该用户创建一个组的,除非是指定组,比如创建用户名:那么就同时自动后台执行,所以fly这个用户属于fly组,如果将多个用户划入一个组,那么特别是对于ftp、samba等服务是有很大的好处的,这样只要对组设定权限就行了,也减少了很多后台管理上的麻烦。
*请认真填写需求信息,我们会在24小时内与您取得联系。
