整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
X-Engine是阿里云数据库产品事业部自研的联机事务处理OLTP(On-Line )数据库存储引擎。目前已经广泛应用在阿里集团内部诸多业务系统中,包括交易历史库、钉钉历史库等核心应用,大幅缩减了业务成本,同时也作为双十一大促的关键数据库技术,挺过了数百倍平时流量的冲击。
重要
X-Engine引擎已进入下线阶段,详情参见【停售/下线】2024年11月1日存储引擎类型为X-Engine的云数据库RDS MySQL版实例停止新购。
为什么设计一个新的存储引擎
X-Engine的诞生是为了应对阿里内部业务的挑战,早在2010年,阿里内部就大规模部署了MySQL数据库,但是业务量的逐年爆炸式增长,数据库面临着极大的挑战:
这两个问题虽然可以通过扩展数据库节点的分布式方案解决,但是堆机器不是一个高效的手段,我们更想用技术的手段将数据库性价比提升,实现以少量资源换取性能大幅提高的目的。
传统数据库架构的性能已经被仔细的研究过,数据库领域的泰斗,图灵奖得主Michael 就此写过一篇论文 《OLTP Through the Looking Glass, and What We Found There》,指出传统关系型数据库,仅有不到10%的时间是在做真正有效的数据处理工作,剩下的时间都浪费在其它工作上,例如加锁等待、缓冲管理、日志同步等。
造成这种现象的原因是近年来我们所依赖的硬件体系发生了巨大的变化,例如多核(众核)CPU、新的处理器架构(Cache/NUMA)、各种异构计算设备(GPU/FPGA)等,而架构在这些硬件之上的数据库软件却没有太大的改变,例如使用B-Tree索引的固定大小的数据页(Page)、使用ARIES算法的事务处理与数据恢复机制、基于独立锁管理器的并发控制等,这些都是为了慢速磁盘而设计,很难发挥出现有硬件体系应有的性能。
基于以上原因,阿里开发了适合当前硬件体系的存储引擎,即X-Engine。
X-Engine架构
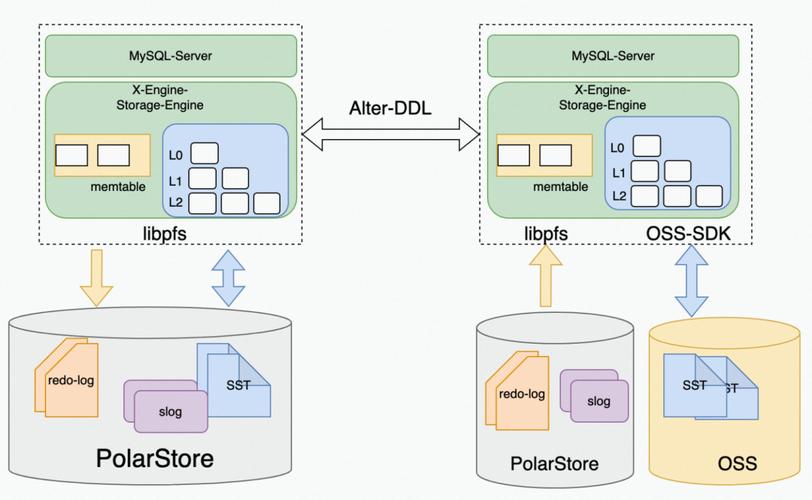
全新架构的X-Engine存储引擎不仅可以无缝对接兼容MySQL(得益于MySQL Storage Engine特性),同时X-Engine使用分层存储架构。
因为目标是面向大规模的海量数据存储,提供高并发事务处理能力和降低存储成本,在大部分大数据量场景下,数据被访问的机会是不均等的,访问频繁的热数据实际上占比很少,X-Engine根据数据访问频度的不同将数据划分为多个层次,针对每个层次数据的访问特点,设计对应的存储结构,写入合适的存储设备。
X-Engine使用了作为分层存储的架构基础,并进行了重新设计:
同时使用更细粒度的访问控制和缓存机制,优化读的性能。
说明
X-Engine的架构和优化技术已经被总结成论文 《X-Engine: An Storage Engine for Large-scale E- 》,在数据管理国际会议SIGMOD'19发表,这是中国内地公司首次在国际性学术会议上发表OLTP数据库内核相关的技术成果。
技术特点
LSM基本逻辑
LSM的本质是所有写入操作直接以追加的方式写入内存。每次写到一定程度,即冻结为一层(Level),并写入持久化存储。所有写入的行,都以主键(Key)排序好后存放,无论是在内存中,还是持久化存储中。在内存中即为一个排序的内存数据结构(、B-Tree等),在持久化存储也作为一个只读的全排序持久化存储结构。
普通的存储系统若要支持事务处理,需要加入一个时间维度,为每个事务构造出一个不受并发干扰的独立视域。例如存储引擎会对每个事务定序并赋予一个全局单调递增的事务版本号(SN),每个事务中的记录会存储这个SN以判断独立事务之间的可见性,从而实现事务的隔离机制。
如果LSM存储结构持续写入,不做其他的动作,那么最终会成为如下结构。
这种结构对于写入是非常友好的,只要追加到最新的内存表中即完成,为实现故障恢复,只需记录Redo Log,因为新数据不会覆盖旧版本,追加记录会形成天然的多版本结构。
但是如此累积,冻结的持久化层次越来越多,会对查询产生不利的影响。例如对同一个key,不同事务提交产生的多版本记录会散落在各个层次中;不同的key也会散落在不同层次中。读操作需要查找各个层并合并才能得到最终结果。
因此LSM引入了操作解决这个问题,操作有2种作用:
高度优化的LSM
X-Engine的memory tables使用了无锁跳表(Locked-free ),并发读写的性能较高。在持久化层如何实现高效,就需要讨论每层的细微结构。
操作是比较重要的,需要把相邻层次交叉的Key Range数据读取合并,然后写到新的位置。这是为前面简单的写入操作付出的代价。X-Engine为优化这个操作重新设计了存储结构。
如前文所述,X-Engine将每一层的数据划分为固定大小的Extent,一个Extent相当于一个小而完整的排序字符串表(SSTable),存储了一个层次中的一个连续片段,连续片段又进一步划分为一个个连续的更小的片段Data Block,相当于传统数据库中的Page,只不过Data Block是只读而且不定长的。
回看并对比 1和 2,可以发现Extent的设计意图。每次修改只需要修改少部分有交叠的数据,以及涉及到的Meta Index节点。两个 结构实际上共用了大量的数据结构,这被称为数据复用技术(Data Reuse),而Extent大小正是影响数据复用率的关键,Extent作为一个完整的被复用的物理结构,需要尽可能的小,这样与其他Extent数据交叉点会变少,但又不能非常小,否则需要索引过多,管理成本太大。
X-Engine中的数据复用是非常彻底的,假设选取两个相邻层次(Level1, Level2)中的交叉的Key Range所涵盖的Extents进行合并,合并算法会逐行进行扫描,只要发现任意的物理结构(包括Data Block和Extent)与其他层中的数据没有交叠,则可以进行复用。只不过Extent的复用可以修改Meta Index,而Data Block的复用只能拷贝,即便如此也可以节省大量的CPU。
一个典型的数据复用在中的过程可以参见下图。
可以看出数据复用的过程是在逐行迭代的过程中完成的,不过这种精细的数据复用带来另一个副作用,即数据的碎片化,所以在实际操作的过程中也需要根据实际情况进行分析。
数据复用不仅给操作本身带来好处,降低操作过程中的I/O与CPU消耗,更对系统的综合性能产生一系列的影响。例如过程中数据不用完全重写,大大降低了写入时空间的增大;大部分数据保持原样,数据缓存不会因为数据更新而失效,减少合并过程中因缓存失效带来的读性能抖动。
实际上,优化的过程只是X-Engine工作的一部分,更重要的是优化调度的策略,选什么样的Extent、定义任务的粒度、执行的优先级等,都会对整个系统性能产生影响,可惜并不存在什么完美的策略,X-Engine积累了一些经验,定义了很多规则,而探索更合理的调度策略是未来一个重要方向。
适用场景
请参见。
如何使用X-Engine
请参见。
后续发展
作为MySQL的存储引擎,持续地提升MySQL系统的兼容能力是一个重要目标,后续会根据需求的迫切程度逐步加强原本取消的一些功能,例如外键,以及对一些数据结构、索引类型的支持。
X-Engine作为存储引擎,核心的价值还在于性价比,持续提升性能降低成本,是一个长期的根本目标,X-Engine还在调度、缓存管理与优化、数据压缩、事务处理等方向上进行深层次的探索。
*请认真填写需求信息,我们会在24小时内与您取得联系。
