整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
“非结构化数据在大多数情况下需要实现结构化才便于后续的数据产品化。”
结构化数据,非结构化数据这两个术语伴随数据要素的全生命周期,特别是在前期治理阶段,是大家经常会打交道的两个术语,如果还有朋友对这个两个术语的区别不是很清楚,今天的内容就值得看一看。
01 定义
——————————————————
我们谈到数据,第一反应就会想到数据库。其实数据库中存储的,绝大部分就是 结构化数据。
就像档案馆里的文件管理方式一样,要分门别类放在该放的位置,然后还要建立索引以方便查找。

接触过数据库设计的朋友都知道,要向数据库中存储数据,首先要做的就是数据库的结构设计,要定义库,表,字段,以及字段的类型和长度,才能进行下一步的数据操作。
而非结构化数据的定义,正好和数据库中的结构化数据相反,它是“数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。”,常见的包括办公文档、文本、图像和音频/视频信息等等,这些数据的特征就是量大,只能作为一个整体来使用。
比如我们日常工作用遇到的如下一些类型:
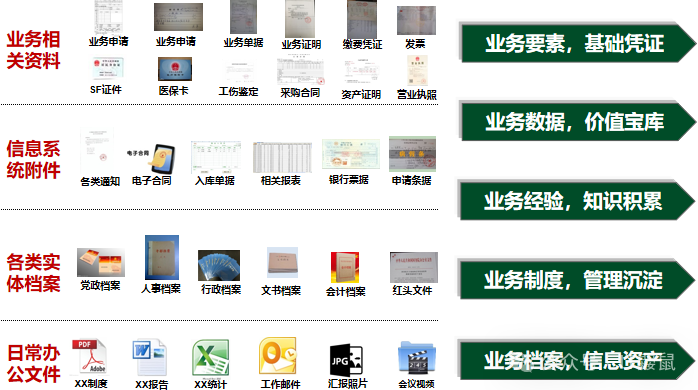
这些数据在使用过程中,如果要搜索内容,就只能用工具比如WORD打开以后,对全文进行检索。而不是像数据库,就像我们的日常OA里边一样,可以指定某个条件,还可以指定判断方式是等于大于小于,然后设定值就可以查询,这就是使用中结构化和非结构化的区别。
我们用表格来对比一下二者的关系和区别
结构化数据
非结构化数据
适合预定义数据模型或架构的数据。
没有底层模型来辨别属性的数据。
基本示例
Excel 表。
视频文件的集合。
最适用于
离散、简短、非连续数字和文本值的关联集合。
属性更改或未知的关联数据、对象或文件集合。
存储类型
关系数据库、图形数据库、空间数据库、OLAP 多维数据集等。
文件系统、DAM 系统、CMS、版本控制系统等。
最大的优势
更易于组织、清理、搜索和分析。
可以分析无法轻松形成结构化数据的数据。
最严峻的挑战
所有数据均必须符合规定的数据模型。
可能很难分析。
主要分析技术
SQL 查询。
复杂。
此外,还有一个定义,就是半结构化数据,顾名思义就是介于二者之间,有点结构,但是又不像数据库那么严格。比如下边百度百科对非结构化数据介绍的页面。

这里边,就会有中文名,外文名,特点,这样的标记,是不是很像数据库的字段?但是又没有严格的按照字段来存储和使用,而是统统放在了文本里。但是对文本处理的时候,如果我预知了有这些字段,我就可以更加快捷高效的处理这些文本,同时存储的时候也不用设计数据库那么麻烦,这就是半结构化数据的优势,二者兼备。
02非结构化数据的特点和价值
——————————————————
结构化数据的价值我们就不多说了,从1970年IBM Codd提出关系型数据库的理论到现在,没有数据库,可以认为就不会有我们现在所有信息化系统。
当然,除了关系型数据库,还有其他的数据库理论和产品,但是关系型,也就是我们现在使用最多的比如IBM DB2,Oracle,开源的Mysql/MariaDB/,都是关系型数据库的实现。
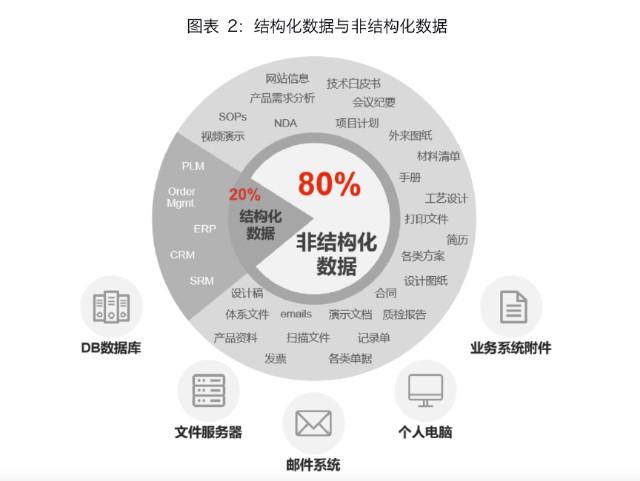
而随着互联网的发展,大量的非结构化数据被生产和传播,首先是第一代互联网的HTML文本,他们构成了我们的网页内容。后来随着网速的提升,特别是从3G以后,大量的图片和视频开始在互联网传播,这些形成了非结构化数据的主体。
而且很明显的,非结构化数据的所占用的存储空间,会远远大于结构化数据,实际上现在大体是28开。
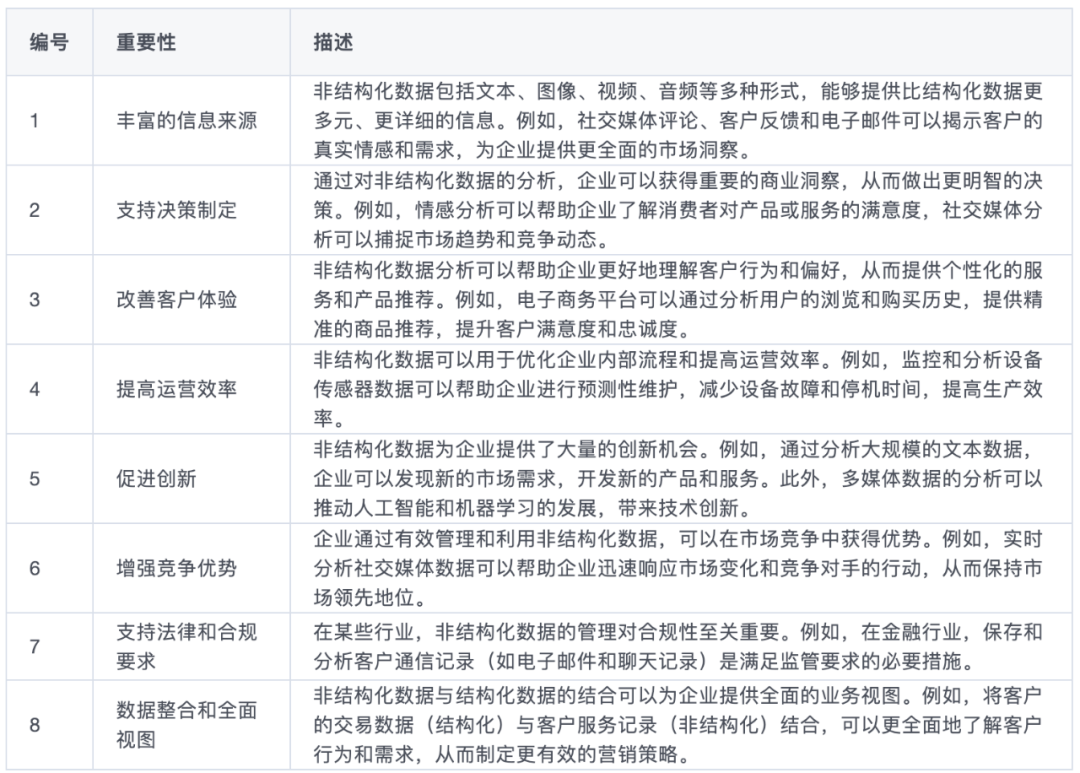
但是,非结构化数据自然也有其优势,我们借用傅一平博士的总结:
特别是在丰富信息来源,提供更丰富的呈现方式,促进创新方面都有优势。
03非结构化治理的挑战
——————————————————
非结构化数据因其自身特点而具备上述优势的同时,也带来了治理的难度。举个简单的例子,大家对手机上的照片和视频是不是都觉得头疼?对企业来讲,更加巨量的数据带来了治理的挑战。
1、数据种类繁杂,形式多样
由于企业日常经营管理和业务管理的需要,建立了功能各异的应用系统或信息化管理平台,而这些管理系统和平台中生成了形式多样的非结构化文档数据,用以支撑企业的各类管理工作。
除此之外,还有大量与管理相关的非结构化文档数据散存在员工个人工作电脑中。这些数据种类繁杂,有的来源于外部,有的是经过内部整理编研形成的,有的则是完全产生于内部;涵盖了不同格式、不同存储载体、不同管理阶段的非结构化文档数据。
企业拥有形式多样的存储设备,包括个人工作电脑以及信息化管理平台中管理的设备,且归属于不同的专业领域,业务活动中产生的非结构化文档数据除了常见的与办公活动相关的非结构化文档数据外,还包括了如照片、视频、设计图纸等多种形式。目前,这些不同种类的非结构化文档数据基本处于分散状态,很难进行有效的关联和整合。
2、非结构化文档数据管理功能不全
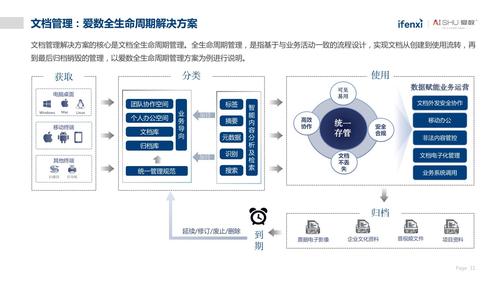
企业一些信息系统(如OA系统、ERP系统等)中文档多以表单(如办文单)的形式进行流转,需要办理的文档通常作为表单的附件,其中既有word或pdf等格式的文本文档,也有多种格式的图片、音视频文件等。这些非结构化文档往往只能借助其所依附的表单信息或者简单的文件标题等元数据加以检索和利用,检全率低,开发利用不足,难以开展深度的数据挖掘与分析。
3、存在过多的“账外”非结构化文档数据,缺少统一管控
由于企业的归档制度不够完善,集团制订的归档范围未将一些应归档但无法通过系统流转的文档纳入其中,部门相当一部分非结构化文档数据仍保存在个人电脑之中,没有统一的管理和控制,难以进行检索和共享利用,导致企业文档数据资产存在着流失的风险。
4、相关制度体系不健全、管理缺位
企业现有的文档管理制度并不是建立在彻底的数据清理基础之上,因此,对于企业中生成哪些非结构化文档,哪些需要归档,如何进行归档?如何进行管理和利用等问题,现有制度中均缺少系统、细致、可操作的规定和描述。
而且,非结构化文档数据缺少必要的分类及元数据项。尤其是文档生命周期流程,即从文档生成、流转、办结到归档、保存、利用的全过程,并没有非常清晰和规范的管理流程和要求。
04非结构化数据如何治理
——————————————————
非结构化数据的治理相比结构化数据,更加复杂。
非结构化数据都散落在各个文件系统中,甚至是以原始物理文件存储的,盘点的时候就不能像结构化数据一样,直接连接数据库读元数据进行盘点。
我们这里也只能围绕如何启动治理提出建议,而盘点之后的步骤,更多就要依赖企业的治理软件进行开展了。
按照DAMA的规范,首先要构建元数据,非结构化数据的盘点的核心毫无疑问也是元数据。而且这个环节完全无法依赖系统,是需要人工结合业务实际情况开展的。
元数据的建立和盘点大致流程如下:
1、梳理业务流程;
2、整理业务输入;
3、整理业务输出;
4、整理非结构化数据元数据,并形成标准;
5、补充业务信息(包括编码、业务分类、业务含义、摘要、标签等);
6、编制成册
最终的成果就是类似这样的一套表格,包括文档名称、编号、业务所需各类信息。
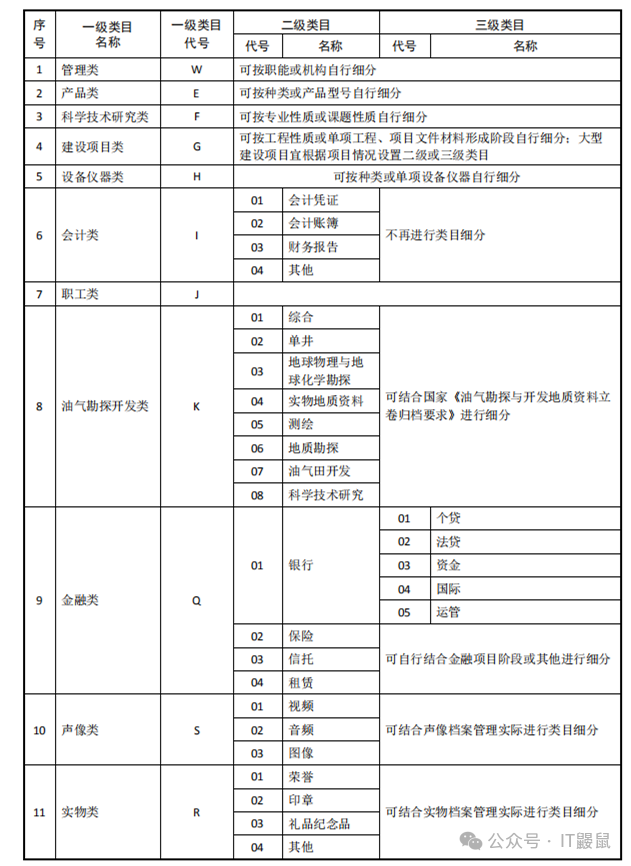
大家是不是有点特殊的感觉,这不是结构化数据吗?
没错,非结构化数据的管理,其实很大程度上就是要依赖于提取其中的结构化数据,才可以进行有效的管理。比如照片中的时间,以及GPS位置信息,视频的长度信息和封面的文字等等,否则,管理就无从谈起。
回到企业业务相关场景,有了上边一套来自业务实践的表格,我们就可以启动相关的系统化建设,通过对数据库的设计,开始把非结构化数据管理起来了。
后边我们可以就这里的两个细节,即非结构化数据中结构化信息的提取,以及如何管理再去深入探讨。今天先到这里。
—————————————————————————
数据资产化,鼹鼠哥与你一起。

欢迎大家公众号后台留言,或者后台回复“进群”,进群一起聊。
*请认真填写需求信息,我们会在24小时内与您取得联系。
