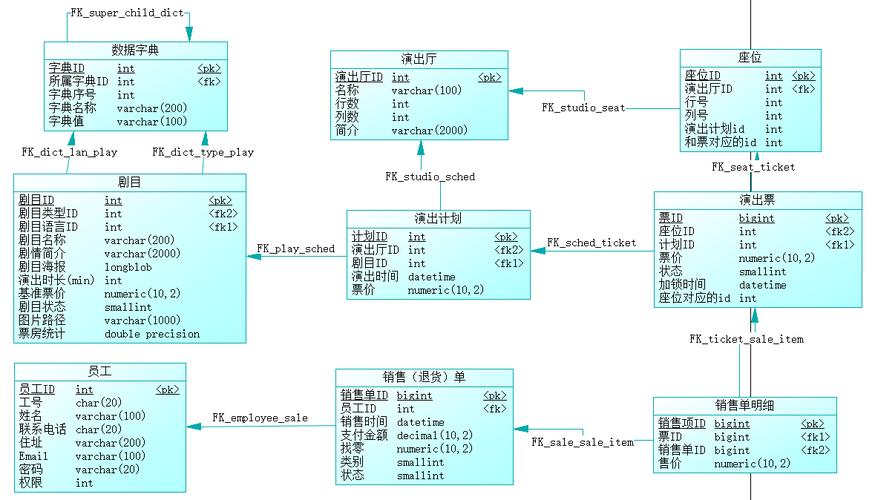
整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
不时有那句话吗:“浓缩的都是精华”!
在后面的文章中,您会陆续看到浩浩荡荡的设计实例连篇累牍,却都是利用这四种基本模式设计出来的。《易传·系辞》曰:“易有太极,是生两仪,两仪生四象,四象生八卦。”老子在《道德经》中也说:“道生一,一生二,二生三,三生万物。”
设计模式不必多,只要掌握其中关键的几个,再结合实际的业务需求,一个完整的数据库模型就可以推导出来。
===============================================================================================
下面让我们来逐一介绍这四种主要设计模式:
(一)主扩展模式
主扩展模式,通常用来将几个相似的对象的共有属性抽取出来,形成一个“公共属性表”;其余属性则分别形成“专有属性表”,且“公共属性表”与“专有属性表”都是“一对一”的关系。
“专有属性表”可以看作是对“公共属性表”的扩展,两者合在一起就是对一个特定对象的完整描述,故此得名“主扩展模式”。
举例如下(注:这个例子已经作了相当程度的简化,仅仅是用来帮助大家理解“主扩展模式”这个概念来使用的,请大家注意)。
假设某公司包括如下6种类型的工作人员:采购员、营销员、库房管理员、收银员、财务人员和咨询专家,采用主扩展模式进行设计,如下图所示。
无论哪种类型的工作人员,都要访问公司的办公软件,所以都有“登陆代码”和“登录密码”;并且作为一般属性,“姓名”、“性别”、“身份证号”、“入职时间”、“离职时间”等属性,都与个人所从事的工作岗位无关,所以可以抽取出来作为公共属性,创建“公司员工”表。
很显然,公司委派员工采购哪些商品是“采购员”的专有属性,这是由公司的实际业务特点决定的。换句话说,公司不可能把采购任务放到“营销员”身上,也不可能放到“库房管理员”身上,“采购商品”属性就是“采购员”的专用属性。
“采购员”表的主键与“公司员工”表的主键是相同的,包括字段名称和字段的实际取值;“采购员”表的主键同时是“公司员工”表主键的外键。在PDM图里可以看到“采购员”表中的“员工ID”字段后面有一个“
”标记,这个标记就说明“员工ID”字段既是“采购员”表的主键,同时也是该表的外键。
“公司员工”表是主表,“采购员”表是扩展表,二者是“一对一”的关系,两个表的字段合起来就是对“采购员”这个对象的完整说明。同理,“公司员工”表和其他5个表之间也都分别构成了“一对一”的关系。
对于主表来说,从表既可以没有记录,也可以有唯一一条记录来对主表进行扩展说明,这就是“主扩展模式”。
(二)主从模式
主从模式,是数据库设计模式中最常见、也是大家日常设计工作中用的最多的一种模式,它描述了两个表之间的主从关系,是典型的“一对多”关系。
举例如下(注:这个例子已经作了相当程度的简化,仅仅是用来帮助大家理解“主从模式”这个概念来使用的,请大家注意)。
比如论坛程序。一个论坛通常都会有若干“板块”,在每个板块里面,大家可以发布很多的新帖。这时候“板块”和“发帖”就是主从模式,主表是“板块”,从表是“发帖”,二者是“一对多”的关系。
多个潜水员也可以对感兴趣的同一份发帖进行回复,以表达各自的意见,这时候,一个“发帖”就有了多份“回复”,又构成了一个“主从模式”。
(三)名值模式
名值模式,通常用来描述在系统设计阶段不能完全确定属性的对象,这些对象的属性在系统运行时会有很大的变更,或者是多个对象之间的属性存在很大的差异。
举例如下(注:这个例子已经作了相当程度的简化,仅仅是用来帮助大家理解“名值模式”这个概念来使用的,请大家注意)。
1. 使用名值模式进行设计时,如果对“其他属性”仅作浏览保存、不作其它任何特殊处理,则通常会设计一个“属性模板”表,该表的数据记录在系统运行时动态维护。
系统运行时,如需维护“产品其他属性”,可先从“属性模板”中选择一个属性名称,然后填写“属性值”保存,系统会将对应的产品ID、属性模板ID及刚刚填写的“属性值”一起保存在“产品其他属性”里,这样就完成了相关设置。无论产品的其他属性需求发生怎样的变化、怎样增删改属性,都可以在运行时实现,而不必修改数据库设计和程序代码。(见下图)
2. 使用名值模式进行设计时,如果对“其他属性”有特殊处理,比如统计汇总,那么这个属性名称需要在程序代码中作“硬编码”,即该属性名称需要在程序代码中有所体现,此时可以在“产品其他属性”表中直接记录“属性名称”,不再需要“属性模板”表。
系统运行时,如需维护“产品其他属性”,程序直接列出“属性名称”,然后填写“属性值”保存,系统会将对应的产品ID、属性名称及刚刚填写的“属性值”一起保存在“产品其他属性”里,这样就完成了相关设置。以后如果需求发生变更,则只需修改相应的程序代码即可,不必修改数据库设计。(见下图)
(四)多对多模式
多对多模式,也是比较常见的一种数据库设计模式,它所描述的两个对象不分主次、地位对等、互为一对多的关系。对于A表来说,一条记录对应着B表的多条记录,反过来对于B表来说,一条记录也对应着A表的多条记录,这种情况就是“多对多模式”。
“多对多模式”需要在A表和B表之间有一个关联表,这个关联表也是“多对多模式”的核心所在。根据关联表是否有独立的业务处理需求,可将其划分为两种细分情况。
1. 关联表有独立的业务处理需求。
举例如下(注:这个例子已经作了相当程度的简化,仅仅是用来帮助大家理解“多对多模式”这个概念来使用的,请大家注意)。
比如网上书店,通常都会有“书目信息”和“批发单”。一条“书目信息”面对不同的购买客户、可以存在多张“批发单”,反过来,一张“批发单”也可以批发多条书目,这就是多对多模式。中间的“批发单明细”表就是两者的关联表,具备独立的业务处理需求,是一个业务实体对象,因此它具备一些特有的属性,比如针对每一条明细记录而言的“累计退货次数”、“累计退货数量”、“累计结算次数”、“累计结算数量”;由于批发单明细在数据产生后已经打印出纸质清单提供给客户,因此在“批发单明细”表里对纸质清单中打印的书目信息属性作了冗余(逆标准化),这样在将来即使修改了“书目信息”表中的属性,也不会影响跟客户核对批发单明细,不会影响未来的财务结算业务。
2. 关联表没有独立的业务处理需求
举例如下(注:这个例子已经作了相当程度的简化,仅仅是用来帮助大家理解“多对多模式”这个概念来使用的,请大家注意)。
比如用户与角色之间的关系,一般系统在做权限控制方面的程序时都会涉及到“系统用户表”和“系统角色表”。一个用户可以从属于多个角色,反过来一个角色里面也可以包含多个用户,两者也是典型的“多对多关系”。其中的关联表“用户角色关联表”在绝大多数情况下都是仅仅用作表示用户与角色之间的关联关系,本身不具备独立的业务处理需求,所以也就没有什么特殊的属性。
(五)使用上述四种模式的一般原则
1. 什么时候用“主扩展模式”?
对象的个数不多;各个对象之间的属性有一定差别;各个对象的属性在数据库设计阶段能够完全确定;各个扩展对象有独立的、相对比较复杂的业务处理需求,此时用“主扩展模式”。将各个对象的共有属性抽取出来设计为“主表”,将各个对象的剩余属性分别设计为相应的“扩展表”,“主表”与各个“扩展表”分别建立一对一的关系。
2. 什么时候用“主从模式”?
对象的个数较多且不固定;各个对象之间的属性几乎没有差异;对象的属性在数据库设计阶段能够完全确定;各个对象没有独立的业务处理需求,此时用“主从模式”。将各个对象设计为“从表”的记录,与“主表”对象建立一对多的关系。
3. 什么时候用“名值模式”?
对象的个数极多;各个对象之间的属性有较大差异;对象属性在数据库设计阶段不能确定,或者在系统运行时有较大变更;各个对象没有相互独立的业务处理需求,此时用“名值模式”。
4. 什么时候用“多对多模式”?
两个对象之间互为一对多关系,则使用“多对多模式”。
数据库物理模型设计的其他模式
除了上面提到的四种主要设计模式,还有一些其他模式,在某些项目中可能会用到,在这里先简单做个说明,暂不做深入讨论,等到以后的项目用到这些模式的时候,再结合实际需求详细解说。
(一)继承模式
继承模式,可以看作是“主从模式”的一种特殊情况(或者说是“变形”),它所代表的两个对象也是“一对多”的关系。它与“主从模式”的区别是,“继承模式”中从表的主键是复合主键,并且复合主键中必定包含主表的主键列。
根据从表继承主表的列的数量,继承模式又分以下两种情况:
1. 从表继承主表的全部列
在这种情况下,从表除了代表自身的专用字段以外,还冗余了主表的全部字段。这种设计方式的缺点显而易见:
数据冗余度大
一致性差
磁盘存储量大
它的优点也显而易见:
正因为它的冗余度大、所以它不易丢失数据。假设主表数据丢失、或者被误操作删改,也能依据从表数据重新生成主表数据;这种设计方式,可以在发生数据损坏的时候从应用的角度进行一定程度的数据恢复,等于是在SQL Server数据库级别的数据恢复功能之上又加了一道保险。
正因为它一致性差、主表数据被重复存储,所以可依据外键关系进行数据验证。将主从表记录作关联比较,如果数据不一致,就可以得知数据要么被人为改动,或者要么程序代码中存在bug。
尽管磁盘存储量大,但是数据在查询统计的时候,只需针对从表进行搜索即可,无需关联操作,可以加快检索的速度。这就是数据库模型设计中经常提到的“以空间换时间”。
2. 从表只继承主表的主键列
这种设计方式,从表只继承了主表的主键列,这种方式的优缺点与前面刚好相反。
优点:
数据冗余度小
一致性高
磁盘存储量小
缺点:
正因为它的冗余度小、所以它易丢失数据。假设主表数据丢失、或者被误操作删改,就只能通过SQL Server数据库级别的数据恢复操作来找回丢失的数据了。
正因为它一致性高,所以无法进行应用程序级的数据验证。
由于采用了一致性设计,磁盘存储量较小,但是数据在查询统计的时候,必须要对两个表进行内连接(INNER JOIN)操作,才能搜索到相关数据。而内连接操作时需要耗费一定的时间的。这就是数据库模型设计中经常提到的“以时间换空间”。
当然,在实际的数据库模型设计过程中,还会有介于上述两者之间的第3种情况出现,那就是从表继承了主表的主键列以及部分其他列。这就要求我们设计人员要依据实际的业务需求进行综合分析、权衡、折中,给出最符合业务需求的设计结果。
(二)自联结模式
自联结模式,也可以看作是“主从模式”的一种特殊情况(或者说是“变形”),它在一张表内实现了“一对多关系”,并且可以根据业务需要实现“有限层”或者“无限层”的主从嵌套。
这种模式用得最多的情况就是实现“树形结构”数据的存储,比如各大网站上常见的细分类别、应用系统的组织结构、Web系统的菜单树等都能用到这种模式。
自联结模式有很多变体,且每种变体的优缺点同样鲜明。由于本连载的重点在于对跨行业通用数据库模型设计进行分析,所以对每种具体模式的细节方面的设计技巧不能作详细论述,请大家原谅。这里仅举两个例子说明:
1. 简单自联结
简单自联结,就是在一个表里设置当前类ID、父类ID,同时规定最顶层类的父类ID为一个固定值(比如0),在生成树的时候使用递归算法,记录的前后顺序通过“排序号”字段来确定。
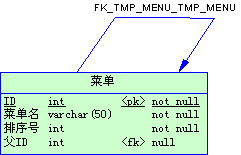
这个表用来存储菜单树很方便。首先会有一个主菜单,主菜单下有子菜单,子菜单下面又有孙菜单……菜单的数量不确定、层级不确定,用户可以在任意菜单下增加新的子菜单,或者删除某个子菜单及其下的所有孙菜单……这种设计方式很多人都会用到,短小精悍、维护方便、且完全满足用户需求,而且树的层次不限,扩展起来非常容易。这些都是它的优点。
它的缺点就是树结构的生成由于使用了递归算法,必然要对该表进行多次读取(读取的次数 = 表内的记录数 – 最深层级的记录数),多次读取就来了比较低的运行效率,当表里的记录很多的时候,这个缺点可以称得上是致命的。
于是就有了下面的这种设计模式。
2. 扩展自联结
扩展自联结,与简单自联结的最大区别就是通过附加冗余字段来避免递归运算,所要实现的主要目标就是一次读取就能生成整个树,一次提高树的生成效率。
但是,鱼与熊掌不可兼得,凡事都有两面性。
生成树的效率提高了,增删改表内记录的算法就会相应复杂,并且树的层数也变为有限的了。
所以在此类设计的时候,大家还是要认真分析业务需求,看看实际业务的重点在什么地方,然后再作具体设计。比如一些门户网站在首页显示产品类别是业务重点,那么我们在设计的时候就要尽可能的提高生成树的效率,采取扩展自联结模式;相反,一些基于Web的业务系统,要求对菜单树的增删改维护操作尽量简单,由于菜单的数目不多,所以菜单树的生成效率不是瓶颈,那么我们设计的时候就可以采取简单自联结模式。
关于附加冗余字段实现扩展自联结的方法很多,网上也有很多这方面的帖子,大家可以到Google上搜一下。
在这里仅举一个例子如下:
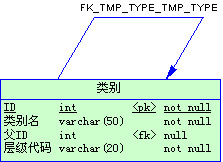
这个设计与前面的设计最大的区别就是排序字段,前面的简单自联结用了一个整数型的字段来实现排序,这里用了一个型的字段“层级代码”来实现大排序。这个字段的取值两位一组,代表一层,假定最深为5层,初始值为。
按照这样的设计,表内的数据记录可能就是这样的:
ID
1 根类别 0 000000
2 类别1 1 010000
3 类别1.1 2 010100
4 类别1.2 2 010200
5 类别2 1 020000
6 类别2.1 5 020100
7 类别3 1 030000
8 类别3.1 7 030100
9 类别3.2 7 030200
10 类别1.1.1 3 010101
……
现在按字段进行排序,执行如下SQL语句:SELECT * FROM ORDER BY
列出记录集如下:
ID
1 总类别 0 000000
2 类别1 1 010000
3 类别1.1 2 010100
10 类别1.1.1 3 010101
4 类别1.2 2 010200
5 类别2 1 020000
6 类别2.1 5 020100
7 类别3 1 030000
8 类别3.1 7 030100
9 类别3.2 7 030200
……
在控制显示类别的层次时,只要对“层级代码”字段中的数值进行判断,每2位一组,如大于0则向右移2个空格。
Altium Designer的元件库
Altium 的元件库
1、AD自带的两个基本库
原理图和PCB封装库可以合成不可编辑的集成库

点击AD软件界面最右下角的 Panels 按钮(有的版本是点击上方windows ),激活和两个窗口。得到如图3所示的AD一般窗口布局,最左边是工程窗口,中间是主窗口,最右边是元件库窗口。
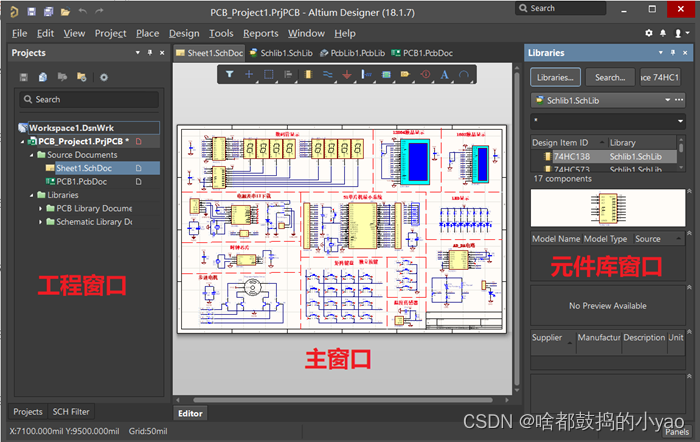
图3 AD一般使用的窗口布局
加载和使用现成元件库的方法如图4所示:
(1)点击1所示的,激活 窗口,通过2所示的Install就可以选择元件库文件进行加载,这与通常软件操作方法无异。
(2)点击3可以选择已加载的不同元件库,同时在下方的搜索栏可以搜索具体元件,可以使用*通配符。
(3)区域4中是元件库中的元件列表,直接点击选中具体元件,就可以拖放到主窗口的原理图或PCB图窗口使用。
(4)区域5展示是元件的原理图符号,区域6显示元件的模型参数,例如三极管bce对应123引脚排列。
(5)区域7中点击2D/3D按钮可以切换显示元件PCB封装和3D模型
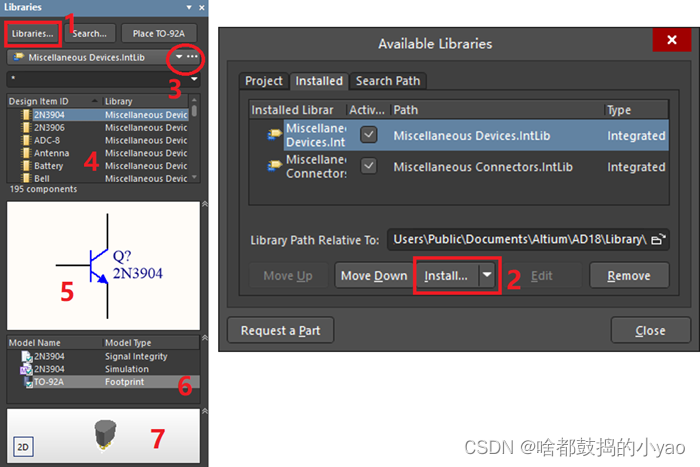
图4 元件库窗口的使用方法
如图5所示为 Devices的195种元件名称。结合图4,可以发现以下特点:
(1)涵盖大部分通用元件,如电阻、电容、二极管、三极管。
(2)集成电路较少。
(3)原理图符号标准,但对应PCB封装未必与用户实际使用一致。
(3)3D模型比较粗糙。
结论:原理图符号部分可copy,pcb封装需检查后进一步加工。
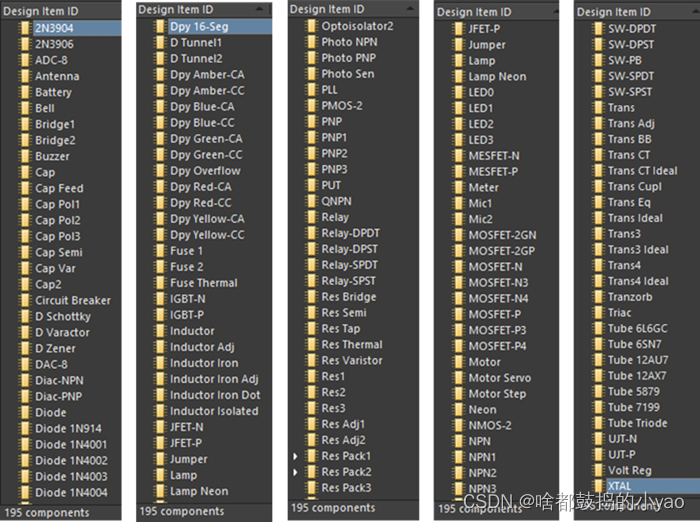
图5 Devices的195种元件
如图6所示为 连接器库的两类典型元件。
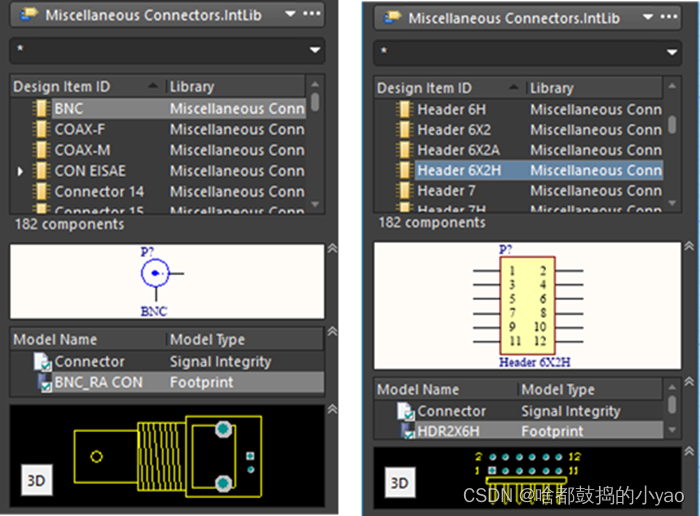
图6 库的几种典型元件
连接器库中最有用的就是各种标准间距(例如2.54mm/100mil)的排针。如图7所示,特别注意看清双列排针的引脚顺序以及间距。而非排针的连接器的PCB引脚尺寸大部分与用户实际使用有差异,难以直接使用。
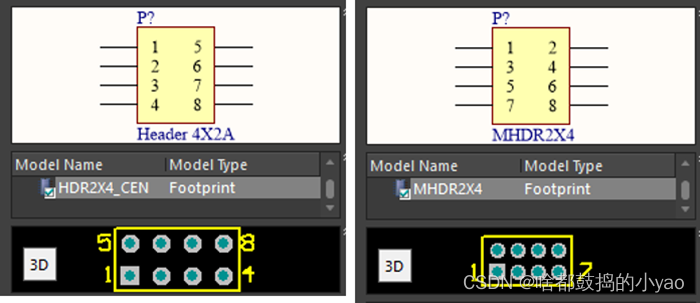
图7 不同引脚顺序和引脚间距的双列排针元件
2、AD10配套的集合厂商元件库
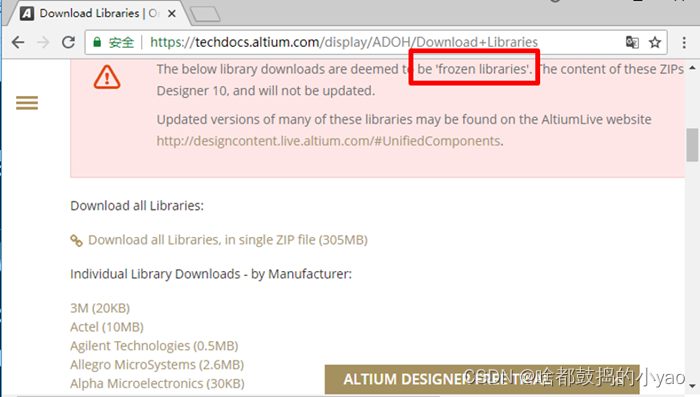
虽然AD自带的两个元件库中几乎没有芯片类元件,但是AD公司另外提供了芯片厂商的元件库供下载,其中最全面的是一个针对AD10发布的,各大元器件厂商的集成库压缩包下载。如图8所示为下载页面,特别注意红框中的一句话“frozen ”,这代表这个集成库压缩包不会再更新了。
3、AD官网维护的厂商元件库
如图10所示,AD的官网也提供实时更新维护的厂商元件库。
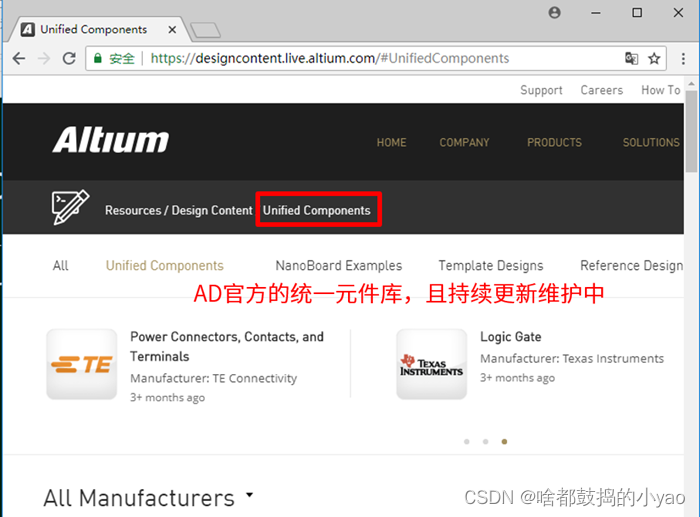
但是,我们只在用到具体器件时,才去查找下载使用。这是因为这个实时元件库不仅按器件厂商分类,而且同一厂商还细分了产品类别,如图11所示,难以提前全部下载。
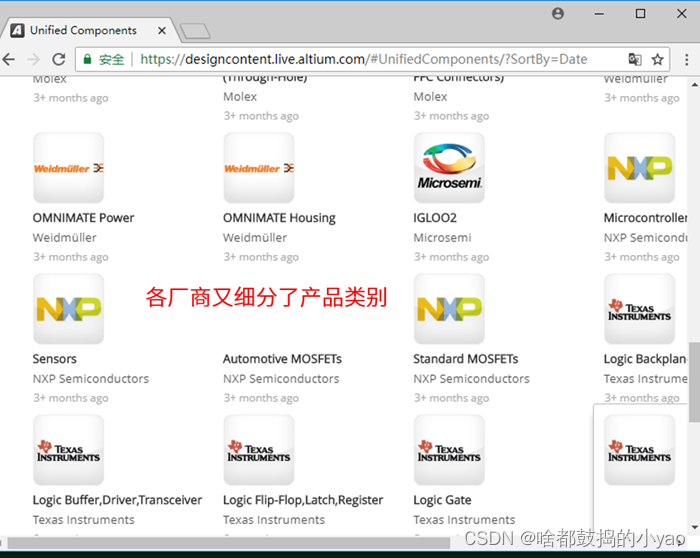
图11 细分类别的厂商库文件
4、元件厂商提供的元件模型及转换方法
如果以上3类库还不能解决问题,我们还可以从元器件厂商处获取具体元件的封装。由于EDA软件有非常多种,所以元器件厂商通常不会给出所有EDA软件的库,而是提供通用的封装文件。这样一来就需要格式转换软件,下面以BXL格式封装文件为例,讲解如何获取AD元件库。
如图12所示,在TI官网搜索,找到质量与封装选项。
图12 的官网资料页
在图13所示的芯片的符号和封装下载页面,bxl为元件封装文件,stp为3D模型。stp文件的使用方法我们后面课程会单独讲解。这里先下载bxl文件并安装读取器软件Ultra 。
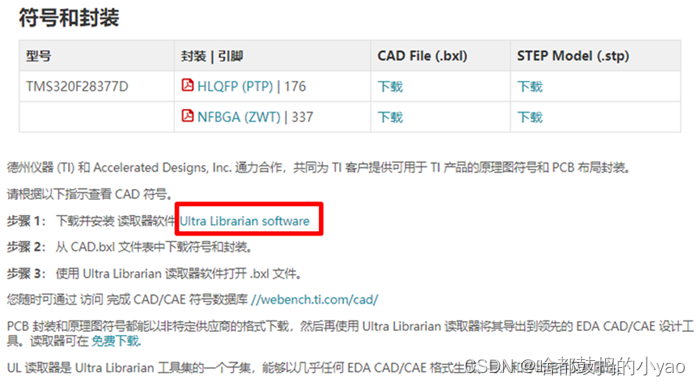
图13 芯片的符号和封装下载页面
(1)从TI的链接中下载免费的Ultra ,并安装。安装过程中有勾选项都勾上,如图14所示。
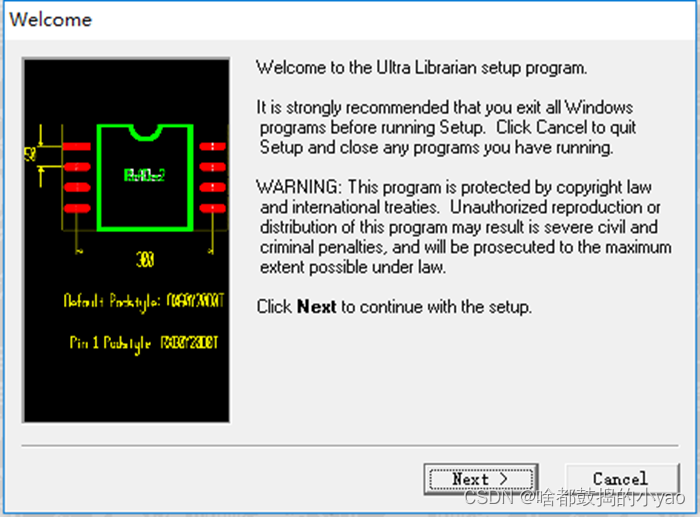
图14 Ultra 软件
(2)如图15所示,点击使用免费版本。
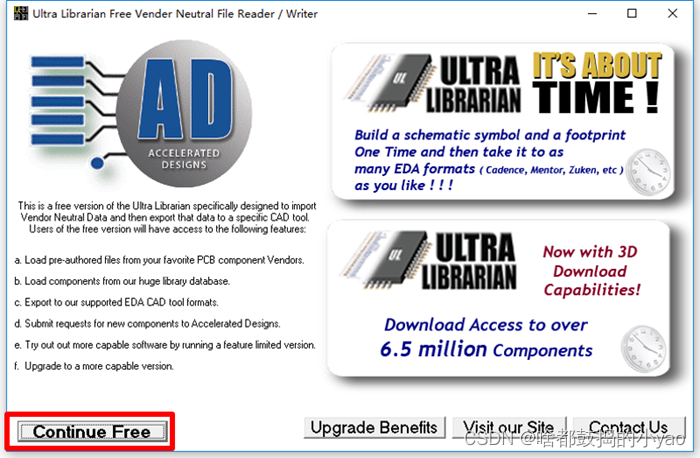
图15 Ultra 软件安装选项
使用Ultra 软件转换元件模型分三步:
(1)如图16所示,在Ultra 软件中点击Load Data,加载TI网站上下载的元件bxl文件。
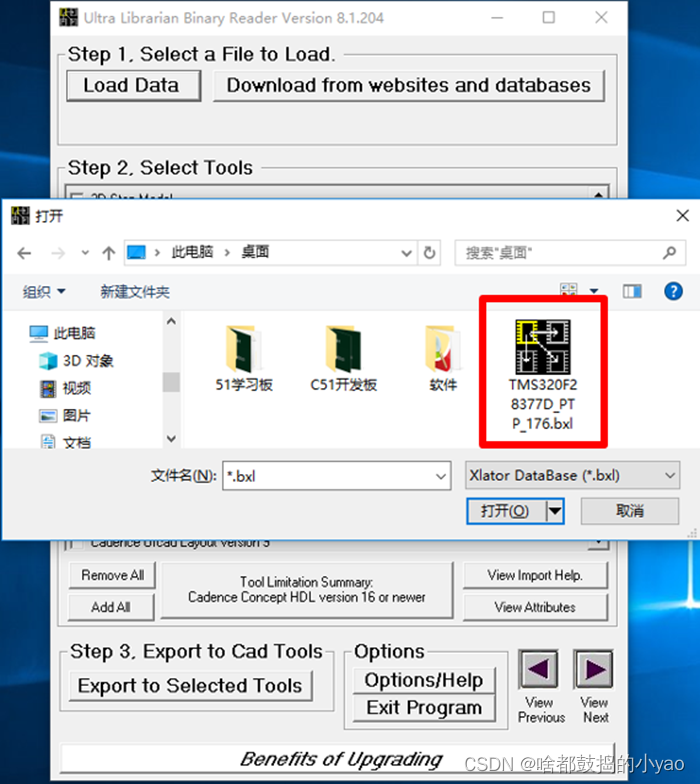
图16 加载bxl文件
(2)参考图17,勾选目标格式Altium
(3)点击输出Export to Tools。
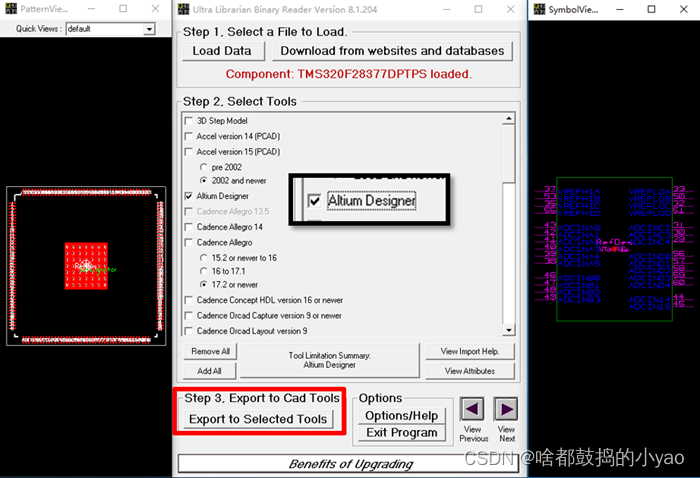
图17 Ultra 软件加载和转换模型
如图18所示,转换完成后自动打开一个read.txt说明文档。在文档提示的存储位置(时间文件夹)获得几个有用文件。
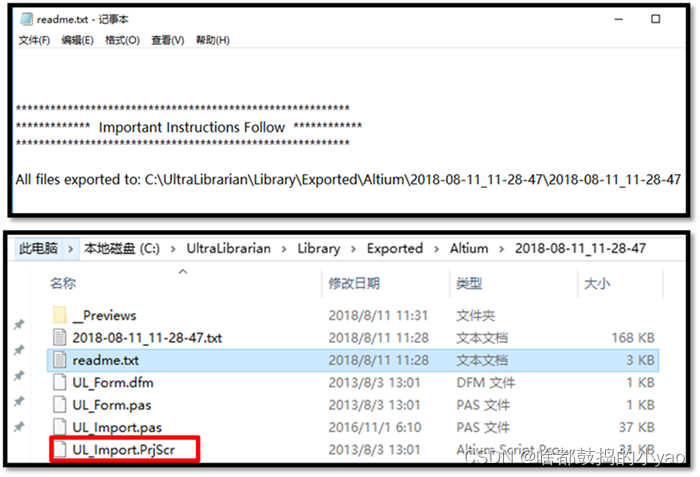
图18 Ultra 软件生成的各种文件
接下来是用AD转换识别Ultra 软件生成的脚本。
(1)用AD打开图18所示的.Prjscr工程文件。然后,双击其中的.pas文件,如图19所示。
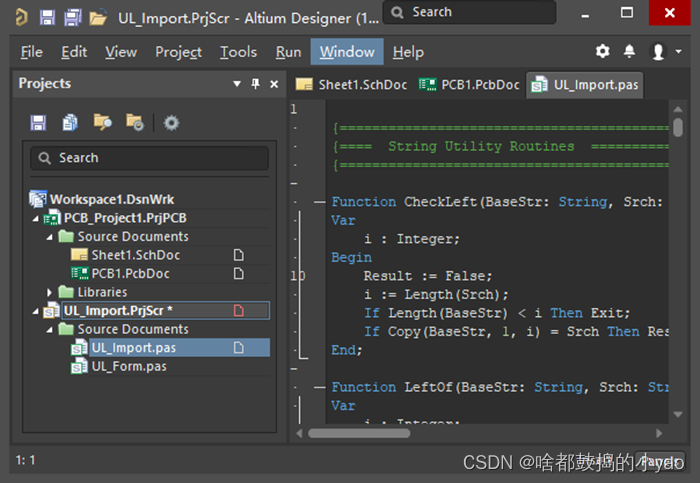
图19 AD打开Ultra 软件生成的脚本
(2)如图20所示,运行脚本
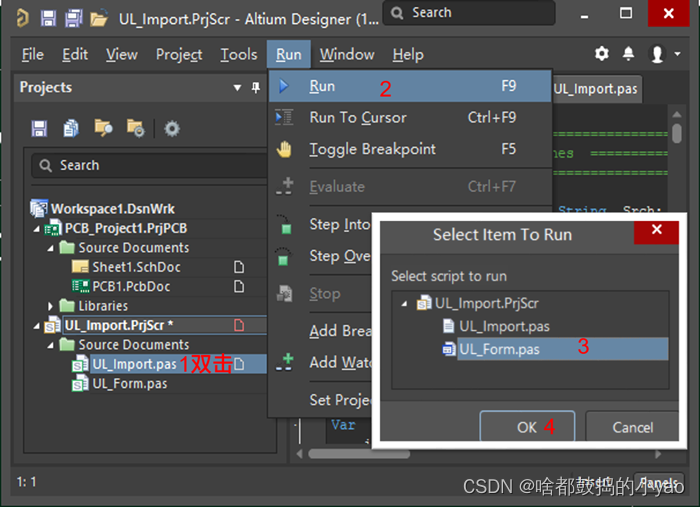
图20 AD运行Ultra 软件生成的脚本
(3)参考图21,运行脚本后,选择日期.txt文件,导入。
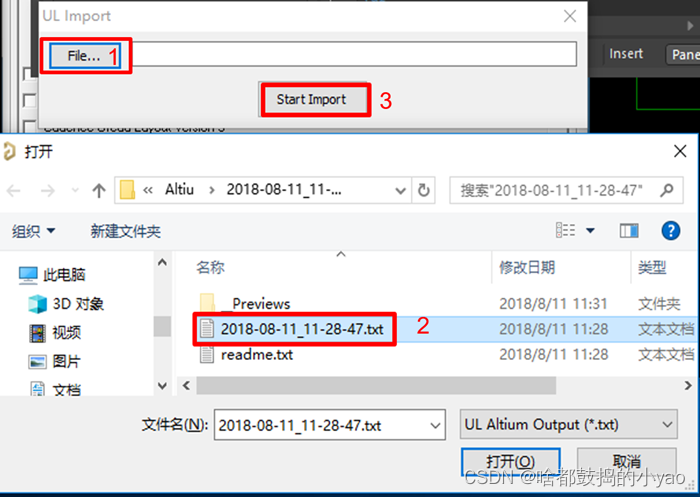
图21 UL Import窗口
(4)得到如图22所示的AD格式的库工程文件。
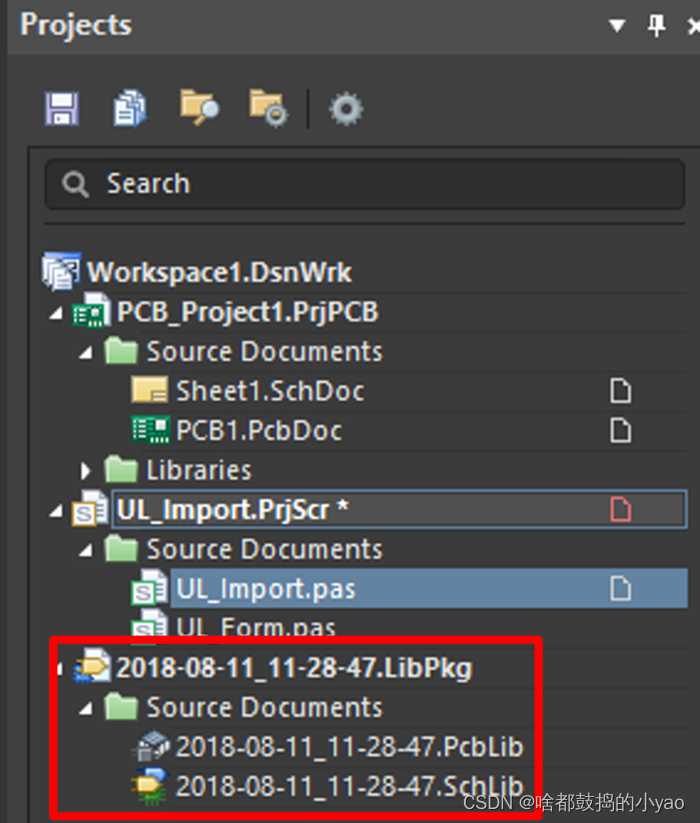
图22 最终获得的AD格式的库文件
接下来可以查看获得的库文件。
(1)点击Panel->SCH Library查看原理图库,如图23所示,原理图库里有一个默认待编辑元件,还有一个5部件的28377D的原理图符号。复杂功能或包含多个相同单元的元件原理图往往设计成多部件元件。
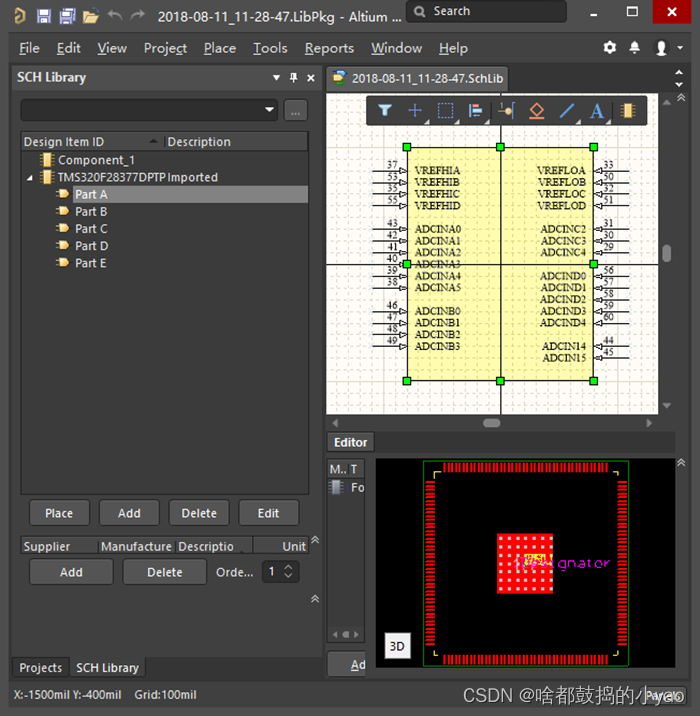
图23 原理图库中默认的待编辑元件
(2)点击Panel->PCB Library查看PCB封装库,如图24所示,官方的PCB封装的焊盘往往会有大中小三种规格供用户选择。后缀N普通,M肥大,L细小。
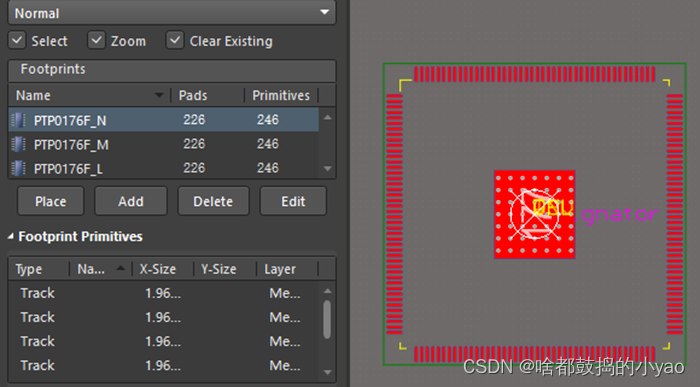
图24 PCB封装库中默认的待编辑元件

5、将外部库添加进自己的库
分离的SCH Library和PCB Library直接可编辑,其中的元件都可以很方便的复制粘贴,一般情况下直接使用这两种库就可以正常设计电路。而IntLib可以类比是“压缩文件”,对其操作需要先进行“解压缩”。
下面举例说明如何新建库,并添加已有库文件元件模型(比如上小节获得的库)。
(1)如图25所示,分别新建集成库工程、原理图库文件、PCB库文件。
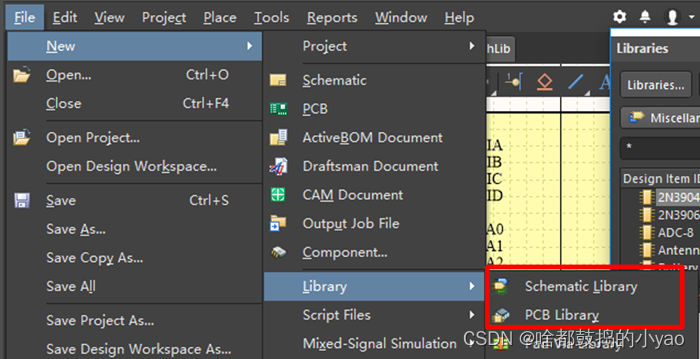
图25 新建集成库工程、原理图库文件、PCB库文件
(2)如图26所示,将新建的SchLib文件和PcbLib文件拖入集成库工程。并能够熟练切换工程文件:Panel->Project、Panel->SCH Library、Panel->PCB Library。
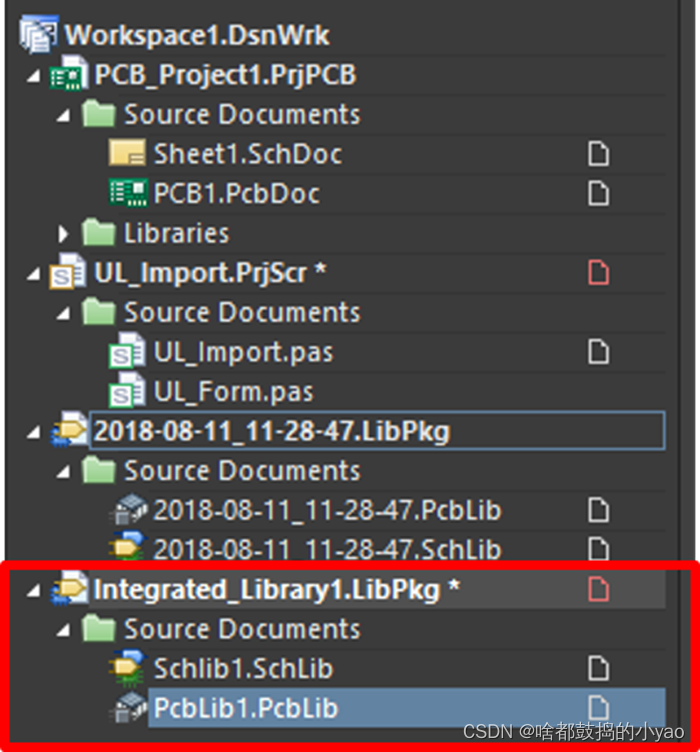
图26 包含原理图库和PCB库的集成库工程目录
(3)如图27所示,原理图库和PCB库都默认有一个待编辑元件
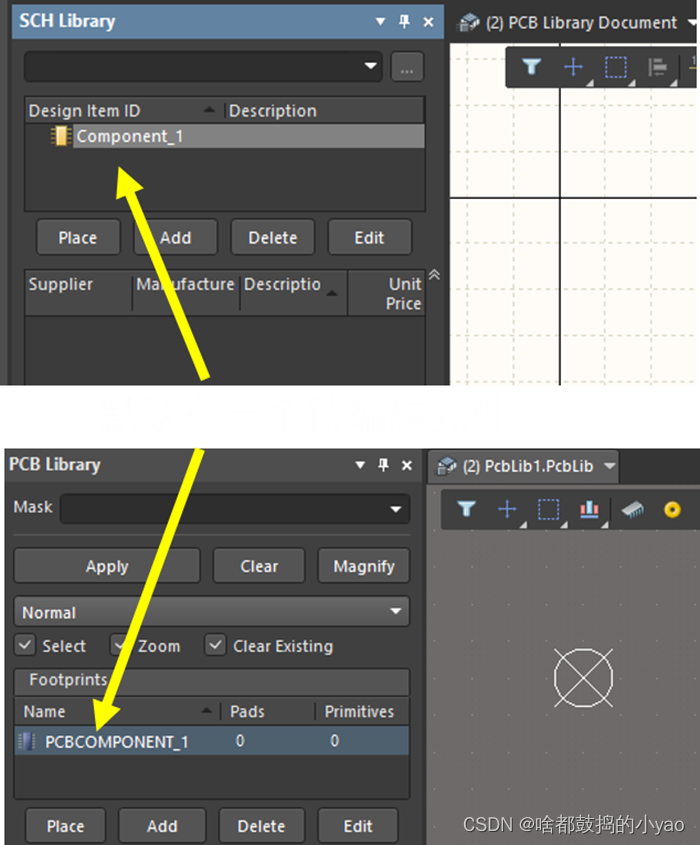
图27 原理图库和PCB库默认的待编辑元件
(4)如图28所示,从已有SchLib库中复制元件(可同时复制多个),此处用的就是上小节原理图库。
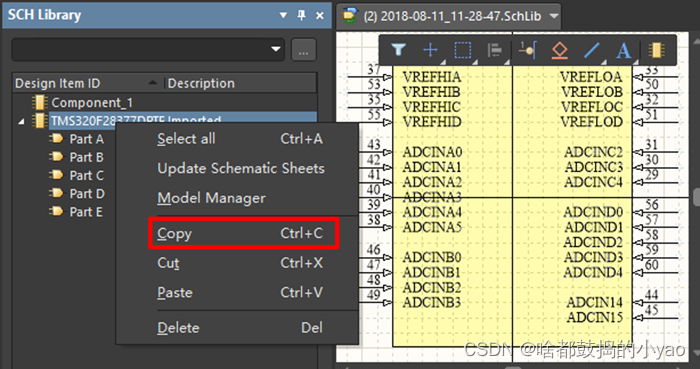
图28 复制元件原理图
(5)如图29所示,在自建的SchLib库中粘贴元件。
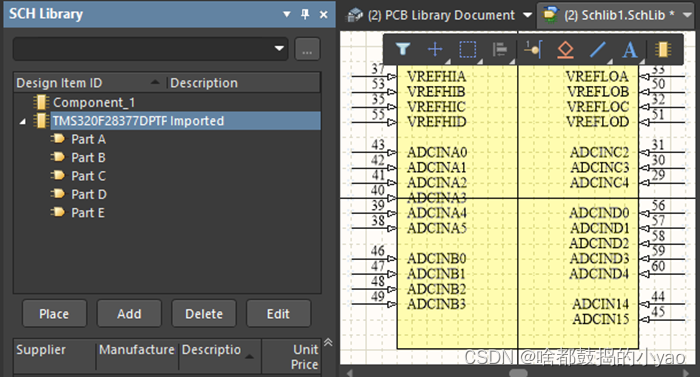
图29 粘贴元件原理图
(6)如图30所示,从已有PCBLib库中复制元件(可同时复制多个),此处用的就是上小节的PCB库。选中多个PCB封装进行复制。
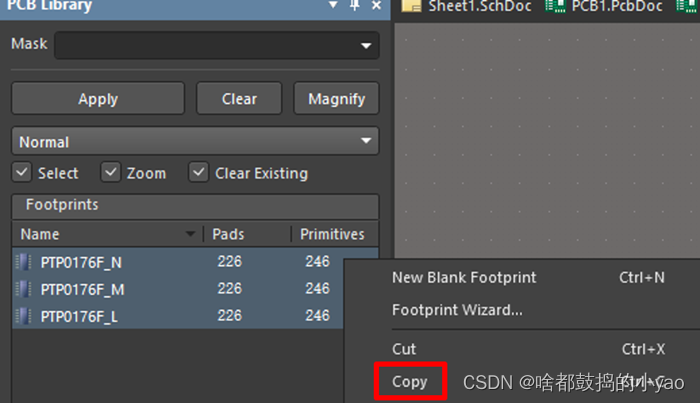
图30 复制元件PCB封装
(7)如图31所示,在自建库中粘贴,会有提示是粘贴3个元件。
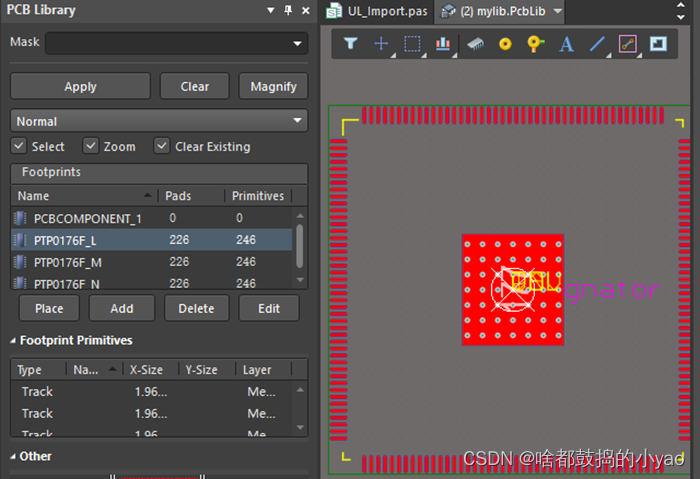
图31 粘贴元件PCB封装
(8)如图32所示,在合适位置保存集成库工程及子文件,自行取名,例如mylib。
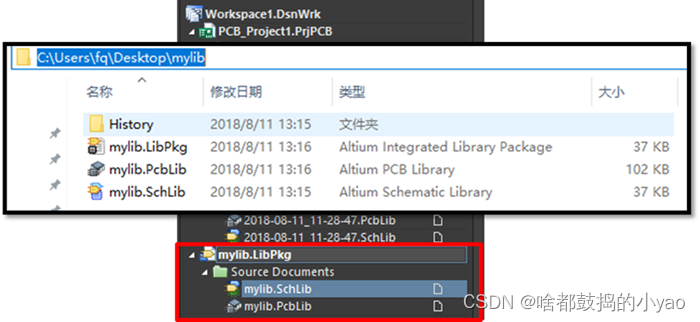
图32 保存自建的集成库
如何复制集成库中的元件?
(1)先用AD直接打开集成库文件,得到如图33所示的提示,按默认选项点OK。
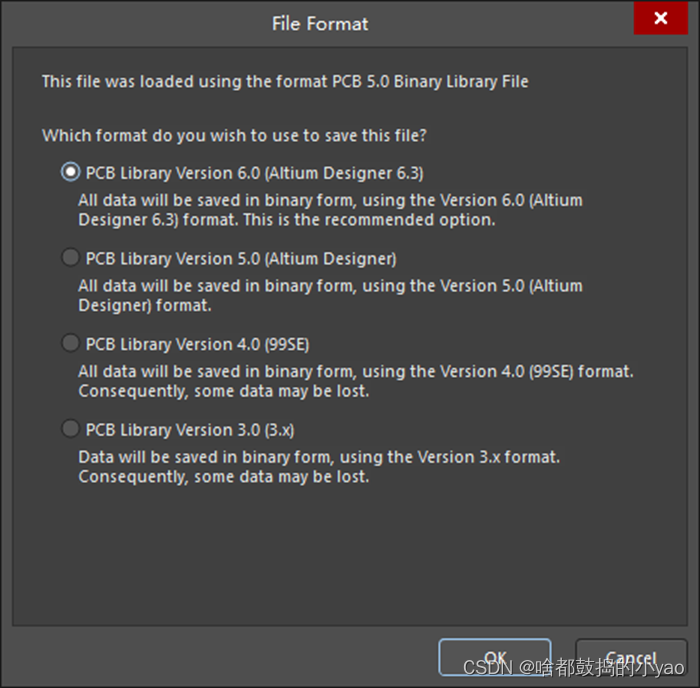
图33 集成库extract窗口
(2)将集成库extract后就可以和前面一样操作其中的元件,如图34为AD自带的连接器 集成库extract后的文件结构。
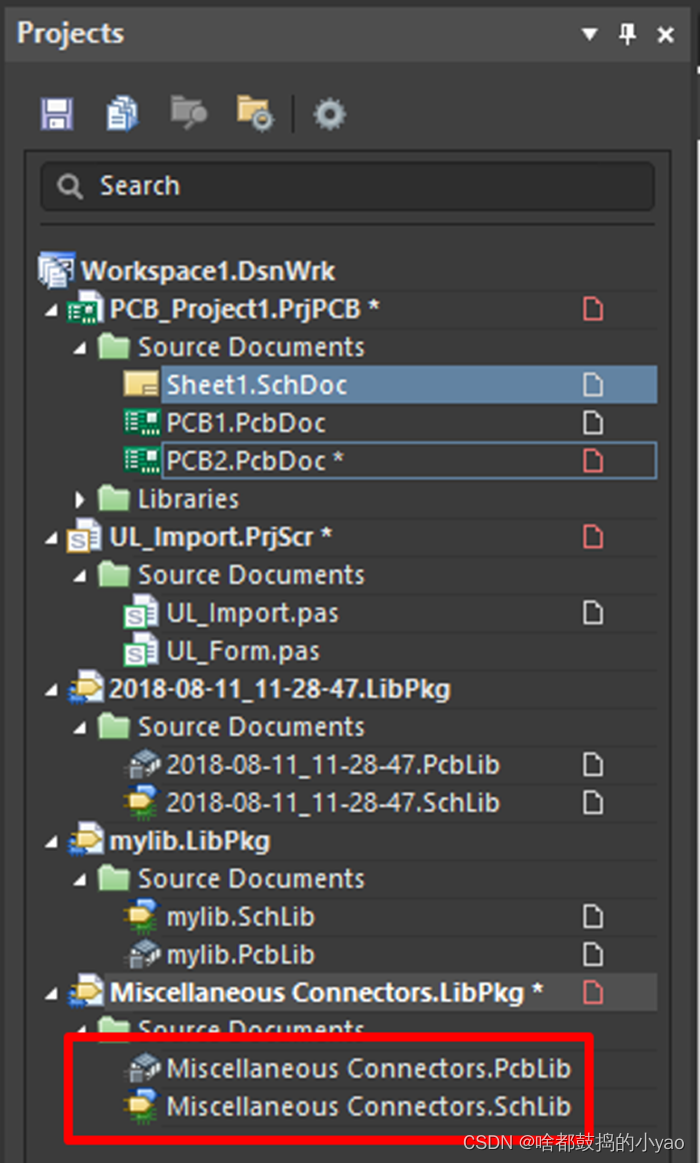
图34 连接器集成库extract后的文件结构
如何合成集成库?
(1)一般情况下,分别使用Sch Library和PCB Library即可,两者都可以直接编辑。有需要,也可将集成库工程中的两个文件SchLib和PcbLib合称为IntLib。
(2)如图35所示,在集成库工程文件LibPkg上点击右键菜单,第一个选项就是合成集成库。
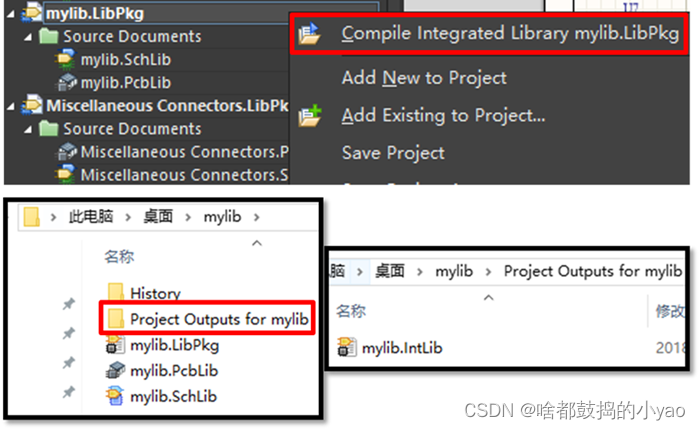
如图35 合成集成库的步骤及其输出位置
推荐浏览
我们在画PCB板子时也会遇到一些基础硬件知识,除了查看相关数据百度外,我推荐可以去牛客网(点击可直达)看看,内容很丰富,属于国内做的很好的了,里面的资源全部免费,有布局布线的知识点补充也有PCB板制作的知识补充等。
*请认真填写需求信息,我们会在24小时内与您取得联系。
