整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
多年来,SAP系统积累了大量数据:临时数据、低价值数据、很少需要的数据,以及仅因法律原因需要保留的数据。随着业务的增加和社会新技术要求的更新换代,企业信息系统也需要不断的更新升级。企业信息系统迁移的过程最重要的是数据迁移,那么要注意什么?

在生产环境中,做数据迁移需要考虑很多的可能性和场景,尽量排除可能发生的问题。 数据迁移需要考虑的问题包括:
1、数据库迁移的停机时间,较长的停机时间是否能够接受,是否不会影响业务中断。在迁移过和中优化停机时间至关重要。
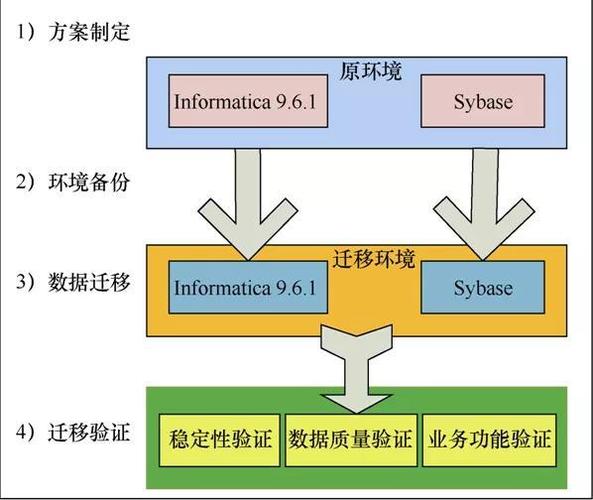
2、数据安全性,迁移过程如何保证数据安全
3、灵活性,企业是否可以灵活选择哪部分数据迁移,系统使用年份较长,必会造成部分冗余数据。那么哪些数据迁移,哪些数据不迁移,哪些历史数据可以选择归档。选择性数据迁移的方法才能满足如上灵活性的要求。
4、时效性,迁移的时间,是需要几个月,几周还是,48小时甚至24小时内就迁移完成上线并将完整性表都可以迁移到新系统或者同时迁移到云端
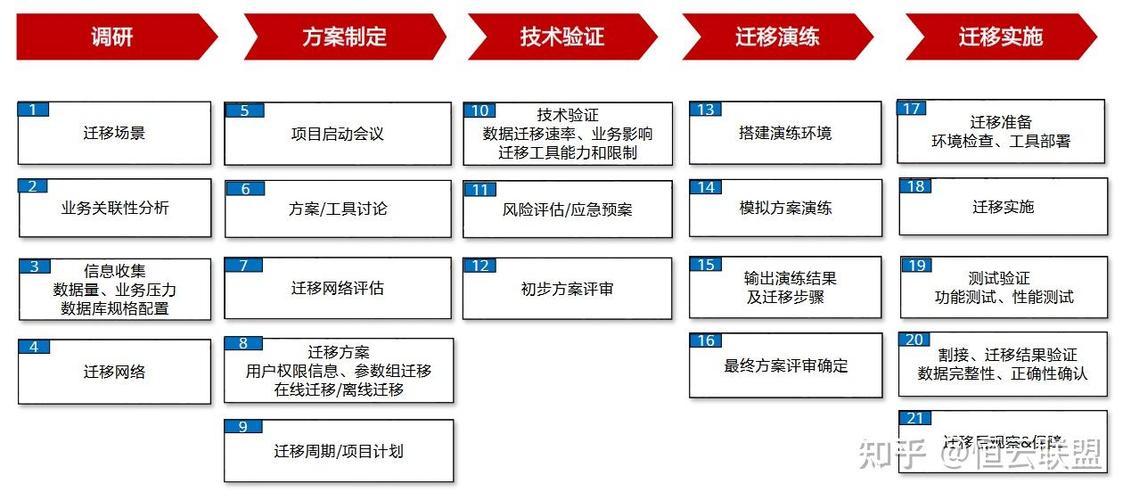
5、数据归档,在基于云的平台上归档数据和文档可以节省高达90%的存储成本。公司需要区分与其业务相关的数据和可以外包的数据。这样可以创建存储空间并降低成本。
6、充分测试,在生产中进行数据的大批量迁移时,充分的测试时必须的。以保证系统成功上线。
SNP 选择性数据迁移方法,通过使用自动化软件平台,可以帮忙SAP客户快速、安全、灵活、高效完成数据迁移工作。可将项目周期时间减少50%以上。
【学习记·第5期】24个为什么?玩转eviews,包括常规统计量+单位根+协整+格兰杰+VAR
中心推出【学习记】,大型连续学习栏目,分别与大家一起分享更多学习内容。一起玩转软件打怪兽升级吧!
Q1:计量经济学是分析啥的?包含些什么内容?
计量经济学的主要用途或目的主要有两个方面:
1、理论检验。
2、预测应用。
研究对象:
计量经济学的两大研究对象:横截面数据(Cross- Data)和时间序列数据(Time-series Data)。前者旨在归纳不同经济行为者是否具有相似的行为关联性,以模型参数估计结果显现相关性;后者重点在分析同一经济行为者不同时间的资料,以展现研究对象的动态行为。
新兴计量经济学研究开始切入同时具有横截面及时间序列的资料,换言之,每个横截面都同时具有时间序列的观测值,这种资料称为追踪资料 (Panel data,或称面板资料分析)。追踪资料研究多个不同经济体动态行为之差异,可以获得较单纯横截面或时间序列分析更丰富的实证结论。
涉及到的相关学科:
计量经济学是结合经济理论与数理统计,并以实际经济数据作定量分析的一门学科。计量经济学以古典回归分析方法为出发点。依据数据形态分为:横截面数据回归分析、时间序列分析、面板数据分析等。依据模型假设的强弱分为:参量计量经济学、非参量计量经济学、半参量计量经济学等。常运用的软件:EViews、Gretl、MATLAB 、Stata、R、SAS、SPSS等……
Q2:知道统计分析有这么多软件,你以为选完软件你就完事了? TOO SIMPLE!,如何下载eviews软件呢?
关注计量经济学服务中心微信公众号,回复关键词eviews,免费下载eviews5.0,6.0,8.0等版本!
Q3:标准差和标准误的区别在哪?
①概念不同;标准差是描述观察值(个体值)之间的变异程度;标准误是描述样本均数的抽样误差;
②用途不同;标准差与均数结合估计参考值范围,计算变异系数,计算标准误等.标准误用于估计参数的可信区间,进行假设检验等。
③它们与样本含量的关系不同:当样本含量 n 足够大时,标准差趋向稳定;而标准误随n的增大而减小,甚至趋于0 。联系:标准差,标准误均为变异指标,当样本含量不变时,标准误与标准差成正比。
Q4:几种相关系数的含义?
简单相关系数:又叫相关系数或线性相关系数。它一般用字母r 表示。它是用来度量定量变量间的线性相关关系。
复相关系数:又叫多重相关系数,复相关是指因变量与多个自变量之间的相关关系。例如,某种商品的需求量与其价格水平、职工收入水平等现象之间呈现复相关关系。
偏相关系数:又叫部分相关系数,部分相关系数反映校正其它变量后某一变量与另一变量的相关关系,校正的意思可以理解为假定其它变量都取值为均数。偏相关系数的假设检验等同于偏回归系数的t检验。 复相关系数的假设检验等同于回归方程的方差分析。
可决系数是相关系数的平方。意义:可决系数越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
Q5:如何最快速的输入数据?
直接导入啊,eviews支持多种格式的数据导入,或者您copy呗!
Q6:面板数据,面板数据的输入又怎么做呢?
首先要明确是做平衡面板数据分析还是非平衡面板数据分析,先介绍前者:
1.准备平衡面板数据集(如xls.txt文件)
2.file/new/建立工作文件
3.选择/undated填上时间序列数据的个数()
4.选object//pool 输入横截面个体的ID
5.导入数据集
导入数据后即可按照你的需要做各种面板数据分析
关于非平衡面板数据
首先将数据在excel表中按企业排序,第一列为企业标识fcode,第二列为时间
1 1990
1 1991
1 1992
2 1990
2 1991
……
然后在eviews中分别通过object//series 建立fcode 和year 两个序列,将上述已排序的数据导入。下一步,双击菜单栏下方的range,在出现的对话框中左边选择 type为dated panel, 在ID series后输入fcode, 在后输入year, 右边的对话框中保持上半部分不变,下半部分去掉所有的勾,然后点ok. 这样会自动生成dateid序列,建立面板数据。其他变量的数据按一般方法输入即可。
说的这么复杂,其实您若是想学,直接留言,免费相关专项面板数据学习的课件,就在路上了。
Q7:简单的描述性统计操作,有方法么?
单击某一序列,如"x",双击弹出该序列,在数据界面-view-graph可以进行作图操作,比如线图或者散点图。你说图画完了怎么保存呢?右键- disk…选择保存路径即可,当然截屏也是ok的。(右键中还有很多可以对图形做调整的,无论是调整横轴还是添加文本,都需要先冻结作图窗口(freeze)才可操作。
那如何获得诸如均值这类的统计量呢?同样点击你需要知道的序列-view-s&test,即可得到均值,标准差,峰度等信息。
至于plot,scat等命令,请自行阅读中心推送的文章【高能推荐】放大招总结的eviews命令,ls+scat+plot+genr你造吗】
Q8:为什么要取对数,如何取对数?
平时在一些数据处理中,经常会把原始数据取对数后进一步处理。之所以这样做是基于对数函数在其定义域内是单调增函数,取对数后不会改变数据的相对关系,取对数作用主要有:
缩小数据的绝对数值,方便计算。例如,每个数据项的值都很大,许多这样的值进行计算可能对超过常用数据类型的取值范围,这时取对数,就把数值缩小了,例如TF-IDF计算时,由于在大规模语料库中,很多词的频率是非常大的数字。取对数后,可以将乘法计算转换称加法计算。
某些情况下,在数据的整个值域中的在不同区间的差异带来的影响不同。也就是说,对数值小的部分差异的敏感程度比数值大的部分的差异敏感程度更高。这取对数之后不会改变数据的性质和相关关系,但压缩了变量的尺度,数据更加平稳,也消弱了模型的共线性、异方差性等。
在经济学中,常取自然对数再做回归,这时回归方程为 lnY=a lnX+b ,两边同时对X求导,1/Y*(DY/DX)=a*1/X,b=(DY/DX)*(X/Y)=(DY*X)/(DX*Y)=(DY/Y)/(DX/X) 这正好是弹性的定义。
告诉你如何取对数
quick\ series\
输入新变量,比如 r=log( ),r就是取完对数后的序列
如何取对数,请自行阅读中心推送的文章
Q9:如何做相关分析?
在Eviews中计算两个序列的的协方差、相关系数和交叉相关系数分别选用、、cross 命令(如果版本中没有选项,可以先选择 ,然后再点)。需要注意的是Eviews在计算协方差和方差时,自由不是样本个数N而不是N-1。
其实,,在多重共线性分析里面可能您需要,请自行回复关键词:学习记,阅读相关教学案例。
Q10:多元回归分析怎么做?
通过quick- 可以到达方程估计的界面,在空白处输入方程中所包含的变量,此处输入的是因变量Y,自变量X和常数项C(一般情况下都会加上常数项)。在method中选择LS(最小二乘法),一般点击确定即可(也可以在OPTIONS中对一些细节做选择)。如果要做样本外预测,首先要扩充样本:工作表中PROC/下面将DATA range进行了扩充,然后在窗口中点击。
Q11:逐步回归,分位数回归呢?
逐步回归:Quick- 中先选择Method:STEPLS
分位数回归:在估计方程时,估计方法的下拉菜单里,不选LS估计,选QREG(LAD)就可以。
Q12:模型需要做哪些检验?
要考虑经济意义(符号是否正确,系数大小是否合理)
模型前期要根据其特点做相关关系检验、平稳、协整检验、因果检验等
建完模型之后要对拟合度,系数显著性检验方程显著性和共线性检验,如有共线性,需要通过删选变量或逐步回归或主成分分法等进行修正
还要对残差做自相关和异方差的检验
Q13::怎么检验异方差?一不小心有了异方差怎么修正?
对方程进行回归后,在显示方程的那个界面中,点view,然后点 Tests 然后点White 即可。可以考虑用用resid^-1作为加权,type选择【.】,weight series输入【1/abs(resid)】。
Q14:自相关,残差有自相关又怎么办?
首先在EVIEWS中建立一个工作文件,然后建立一个序列对象如序列X,然后打开序列X,在VIEW菜单中有个选项.....,选择该选项后会得到另一个对话框,该对话框的左边是选择检验序列本身还是一阶差分、二阶差分后的结果(你自己选择)。右边指定滞后期,EVIEWS会根据你序列数据的多少设定一个数值,你可以使用默认值,再点击OK即可得到检验结果,关键是看检验概率,如果检验概率小于显著性水平就说明有自相关,反之亦然。
自相关消除可以采用广义差分法,建议先取对数,然后再进行一阶自相关的检验,最后再建立广义差分模型,消除自相关。
Q15:何为平稳性检验?
说到平稳,其实有两种平稳——宽平稳、严平稳。严平稳相较于宽平稳来说,条件更多更严格,而我们时常运用的时间序列,大多宽平稳就够了~~
什么是严平稳:是在固定时间和位置的概率分布与所有时间和位置的概率分布相同的随机过程。这样,数学期望和方差这些参数也不随时间和位置变化。(比如白噪声)
什么是宽平稳:宽平稳是使用序列的特征统计量来定义的一种平稳性。它认为序列的统计性质主要由它的低阶矩决定,所以只要保证序列低阶矩平稳(二阶),就能保证序列的主要性质近似稳定。
两者关系:
一般关系:严平稳条件比宽平稳条件苛刻,通常情况下,严平稳(低阶矩存在)能推出宽平稳成立,而宽平稳序列不能反推严平稳成立。
特例:不存在低阶矩的严平稳序列不满足宽平稳条件,例如服从柯西分布的严平稳序列就不是宽平稳序列。当序列服从多元正态分布时,宽平稳可以推出严平稳。
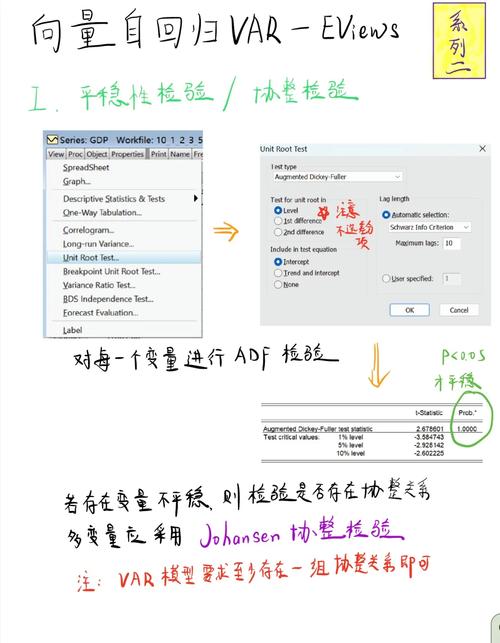
Q16:如何进行平稳性检验:
检查序列平稳性的标准方法是单位根检验。有6种单位根检验方法:ADF检验、DFGLS检验、PP检验、KPSS检验、ERS检验和NP检验,本节将介绍DF检验、ADF检验。
ADF检验和PP检验方法出现的比较早,在实际应用中较为常见,但是,由于这2种方法均需要对被检验序列作可能包含常数项和趋势变量项的假设,因此,应用起来带有一定的不便;其它几种方法克服了前2种方法带来的不便,在剔除原序列趋势的基础上,构造统计量检验序列是否存在单位根,应用起来较为方便。ADF检验是在Dickey-Fuller检验(DF检验)基础上发展而来的。因为DF检验只有当序列为AR(1)时才有效。如果序列存在高阶滞后相关,这就违背了扰动项是独立同分布的假设。在这种情况下,可以使用增广的DF检验方法( Dickey-Fuller test )来检验含有高阶序列相关的序列的单位根。
检验步骤(一般进行ADF检验要分3步):
1) 对原始时间序列进行检验,此时第二项选level,第三项选None.如果没通过检验,说明原始时间序列不平稳;
2 )对原始时间序列进行一阶差分后再检验,即第二项选1st ,第三项选,若仍然未通过检验,则需要进行二次差分变换;

3 )二次差分序列的检验,即第二项选择2nd ,第四项选择Trend and .一般到此时间序列就平稳了!
在进行ADF检验时,必须注意以下两个实际问题:
(1)必须为回归定义合理的滞后阶数,通常采用AIC准则来确定给定时间序列模型的滞后阶数。在实际应用中,还需要兼顾其他的因素,如系统的稳定性、模型的拟合优度等。
(2)可以选择常数和线性时间趋势,选择哪种形式很重要,因为检验显著性水平的 t 统计量在原假设下的渐近分布依赖于关于这些项的定义。
Q17:如果序列平稳了,那怎么看定阶啊?
AR模型:自相关系数拖尾,偏自相关系数截尾;
MA模型:自相关系数截尾,偏自相关函数拖尾;
ARMA模型:自相关函数和偏自相关函数均拖尾。
P Q主要看从第几期开始快速收敛。
Q18:什么是协整分析?
整检验,说明变量之间存在着长期稳定的均衡关系,其方程回归残差是平稳的。因此可以在此基础上直接对原方程进行回归,此时的回归结果是较精确的。
Q19:做协整的条件是什么?Eviews里怎么做?
协整的要求或前提是同阶单整,但也有如下的宽限说法:如果变量个数多于两个,即解释变量个数多于一个,被解释变量的单整阶数不能高于任何一个解释变量的单整阶数。另当解释变量的单整阶数高于被解释变量的单整阶数时,则必须至少有两个解释变量的单整阶数高于被解释变量的单整阶数。如果只含有两个解释变量,则两个变量的单整阶数应该相同。
就是说,单整阶数不同的两个或以上的非平稳序列如果一起进行协整检验,必然有某些低阶单整的,即波动相对高阶序列的波动甚微弱(有可能波动幅度也不同)的序列,对协整结果的影响不大,因此包不包含的重要性不大。而相对处于最高阶序列,由于其波动较大,对回归残差的平稳性带来极大的影响,所以如果协整是包含有某些高阶单整序列的话(但如果所有变量都是阶数相同的高阶,此时也被称作同阶单整,这样的话另当别论),一定不能将其纳入协整检验。
选定你需要检验的series as group ,然后view/...
Q20:何为格兰杰因果检验?
介绍一下因果检验的含义:这里的因果关系是从统计角度而言的,即是通过概率或者分布函数的角度体现出来的:在所有其它事件的发生情况固定不变的条件下,如果一个事件X的发生与不发生对于另一个事件Y的发生的概率(如果通过事件定义了随机变量那么也可以说分布函数)有影响,并且这两个事件在时间上又有先后顺序(A前B后),那么我们便可以说X是Y的原因。考虑最简单的形式,Granger检验是运用F-统计量来检验X的滞后值是否显著影响Y(在统计的意义下,且已经综合考虑了Y的滞后值;如果影响不显著,那么称X不是Y的“Granger原因”();如果影响显著,那么称X是Y的“Granger原因”。同样,这也可以用于检验Y是X的“原因”,检验Y的滞后值是否影响X(已经考虑了X的滞后对X自身的影响)。
Q22:如何做格兰杰因果检验?
先做单位根检验,如果平稳可直接做格兰杰,如果不平稳,做差分后在将两序列做单位根,如果同阶单整,做最小二成估计,将残差存为新序列再做单位根,如果平稳可将差分后序列做格兰杰。如果不平稳则不可做格兰杰。如果不同阶单整,则将其中一个再做差分,新序列就成同阶单整。格兰杰检验的滞后需要用VAR检验计算,根据AIC或SC选择合适的滞后阶。
在菜单栏里的quick-group - test然后会出现series list
在此输入你要检验的变量后点击ok进入lag 画面,选择适当的滞后长度,点击ok则有结果了。 p值小于0.05就是有因果关系。
Q23:只有对平稳序列才能建立VAR模型吗?
只有平稳才能建VAR模型,但有特例,就是涉及到一些变量是如增长率,由于种种原因,如数据太少,或其他原因,ADF检验没通过,但也可以算作平稳,视情况而定。
差分后的变量建立的模型,其经济含义只能是差分后的,比如GDP你就只能说是GDP增长或增长率与其他变量的关系。
非要建立原始变量(GDP)的VAR模型的话,应该建立误差修正的向量自回归模型,要求协整。
Q24:怎么做VAR?
第一步:不问序列如何均可建立初步的VAR模型(建立过程中数据可能前平稳序列,也可能是部分平稳,还可能是没协整关系的同阶不平稳序列,也可能是不同阶的不平稳序列,滞后阶数任意指定。所有序列一般视为内生向量),
第二步:在建立的初步VAR后进行
1 滞后阶数检验,以确定最终模型的滞后阶数
2 在滞后阶数确定后进行因果关系检验,以确定哪些序列为外生变量
至此重新构建VAR模型(此时滞后阶数已定,内外生变量已定),再进行AR根图表分析,
如单位根均小于1,VAR构建完成可进行脉冲及方差分解
如单位根有大于1的,考虑对原始序进行降阶处理(一阶单整序列处理方法:差分或取对数,二阶单整序列:理论上可以差分与取对数同时进行,但由于序列失去了经济含义,应放弃此处理,可考虑序列的趋势分解,如分解后仍然不能满足要求,可以罢工,不建立任何模型,休息或是打砸了电脑),处理过后对新的序列(包括最初的哪些平稳序列)不断重复第一步与第二步,直至满足稳定性为止
第三步,建立最终的VAR后,可考虑SVAR模型。如果变量不仅存在滞后影响,还存在同期影响关系,则建立VAR模型不太合适,这种情况下需要进行结构分析。
上述问题,更详细的教学,将后期学习记慢慢推出!

计量经济学服务中心
学术问题,一对一专家解决
打造中国最大的人文社科+经管类学术交流学习平台!论文指导、软件操作、学术技能、数据分析等,一起见证学术力量!

见证学术力量
让知识更有价值
*请认真填写需求信息,我们会在24小时内与您取得联系。
