整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
在平时的学习生活中,我们总会遇到几个不认识的字,奇形怪状,有的还是古文字,不会读,不知道什么意思,但又想知道,又没有办法,让人抓狂。

这样的情况相信各位都遇到过。由于汉字不表音(形声字虽多,但“认字认半边”的办法并非百试百灵),不认识的字很难一看到就准确读出来并查找它的意义。遇到形体简单的字,可以通过手写的方式来查找,这个比较简单;
但遇到形体复杂的生僻字,输入法又没有收录,那么查找就比较困难了。

特别是古文字,比如小篆、甲骨文等,现在的输入法都打不了,网页也只能以图片的方式显示,借助搜索引擎是查不到的。现在的识图技术也不完善,识图这条路也走不通(谷歌的识图比百度的要好,但是要科学上网,而且不稳定)。

在这里,山竹推荐给大家几种比较方便的查字方法,不包括百度、书写等普遍的方法。
下载字库比较大,收字比较全的输入法:逍遥笔输入法(仅限电脑端使用)
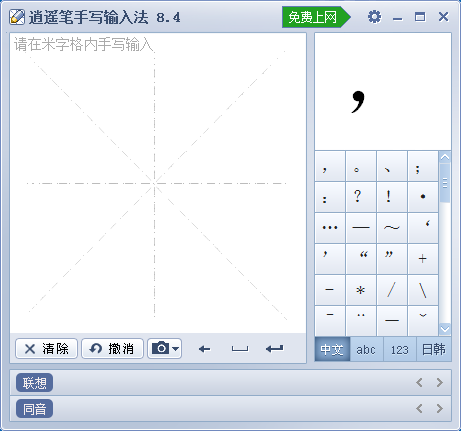
评价:操作简单,收字多,查找常用的汉字和一部分生僻字没问题,可离线使用,但收字不全,查古文不行,没有手机版,不方便。
登录在线网站:国学大师网,支持离线下载大量词典工具书及古籍等数据;也有“国学大师网”App,安装包小,简单实用。需要下载字体:开心字体和说文小篆字体,切换浏览器内核,详情在下。
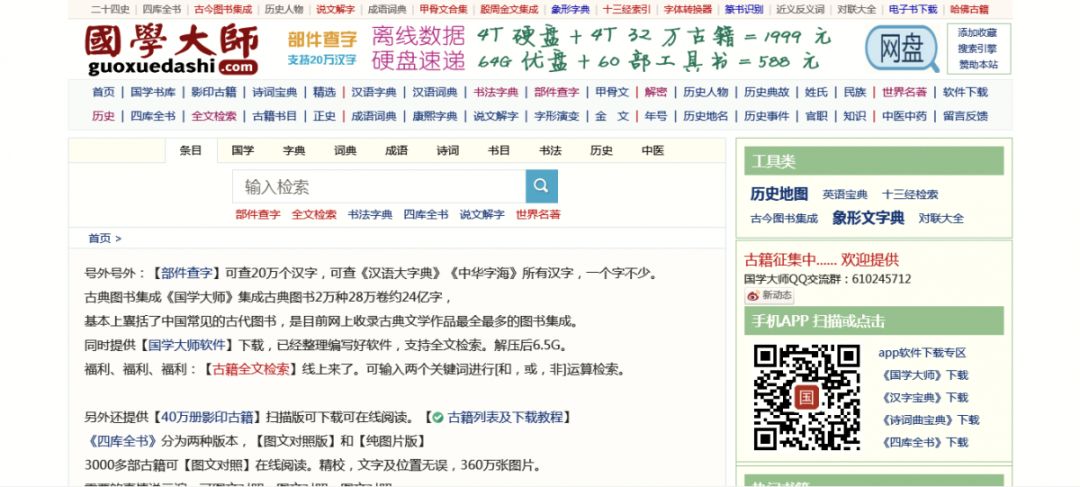
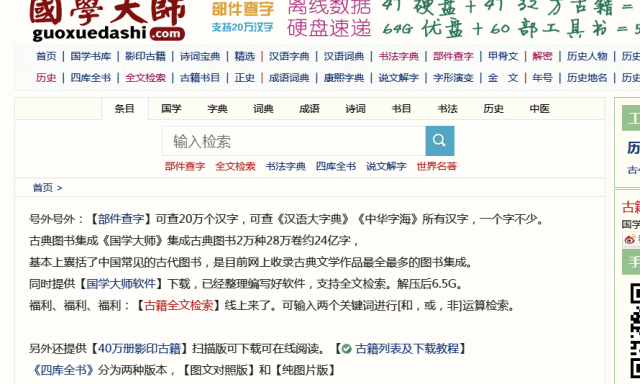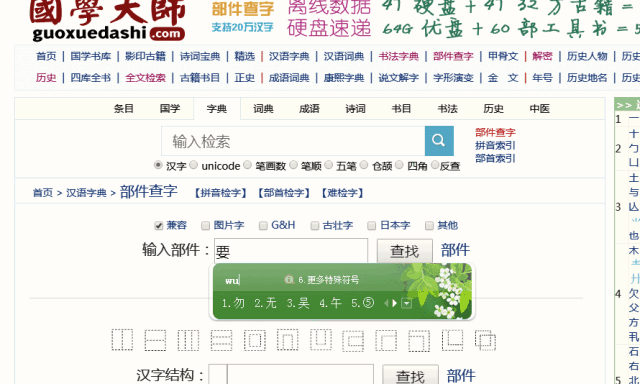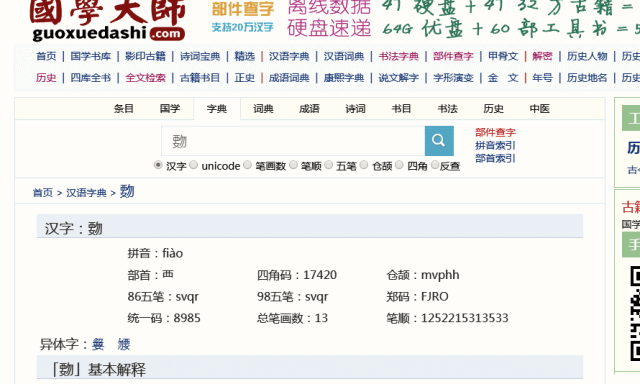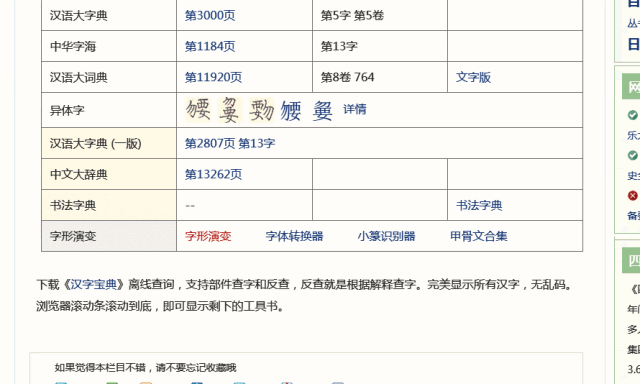
具体的查字方法:登录国学大师网{},在搜索框的下面,有一个“部件查字”,点击进入。
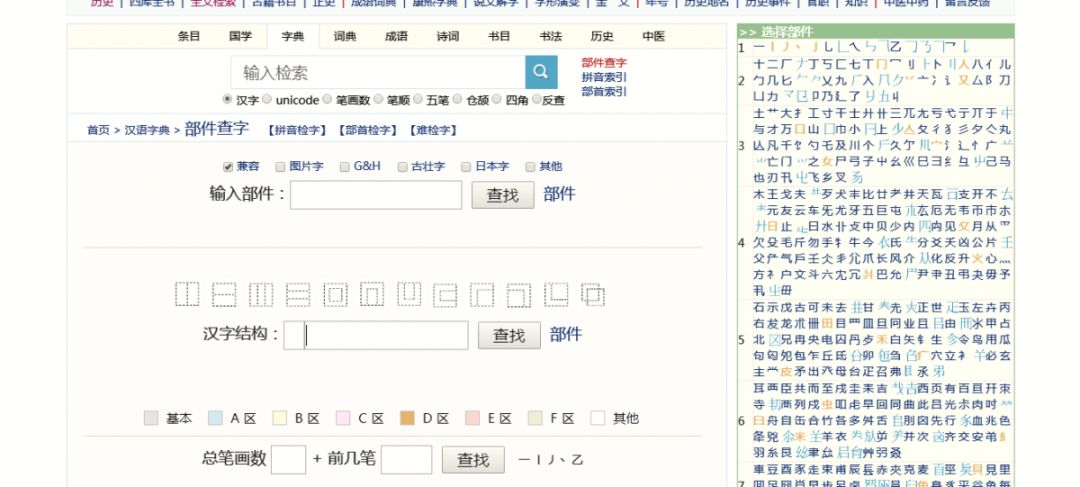
在搜索框内输入你想查找的字的部件,点击“查找”就可以了。比如:我要查“覅”,那么在搜索框内输入“要勿”点击“查找”即可。
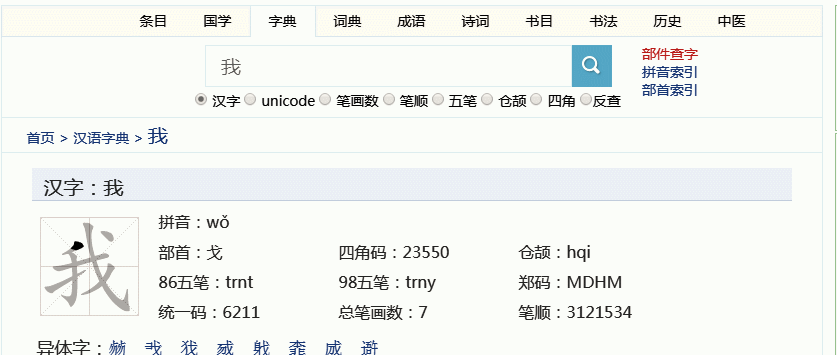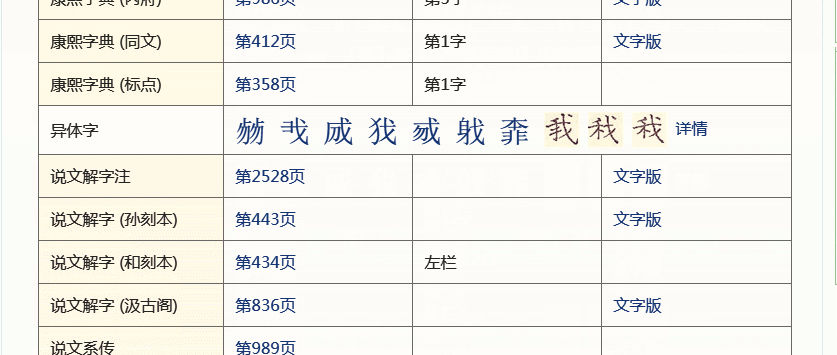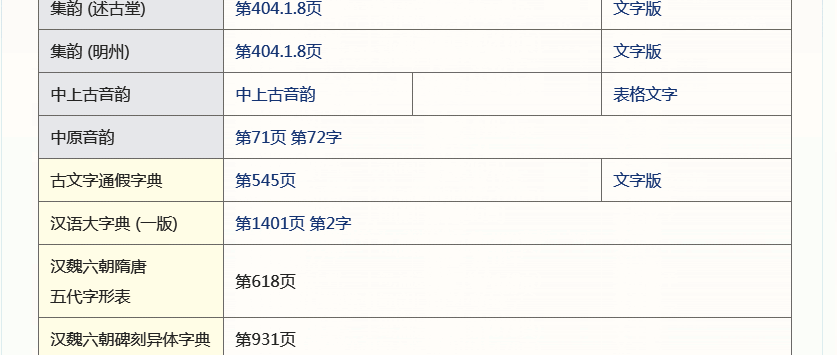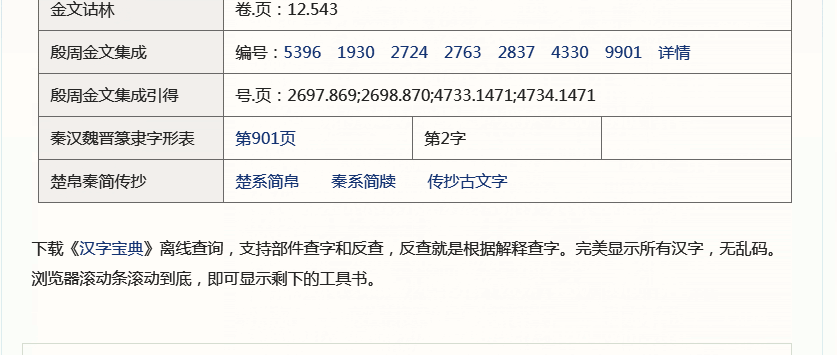
最后显示出来的是“覅”字的信息,包括它在各个词典工具书及古籍的出处,想看“覅”字的详细解释,点进去就可以看到。内容除文字版,还有各种PDF照排版,便于文字学的老师同学查找出处并核定内容是否有误。

如果字显示不出来,可能是字体原因,在网站首页下载“开心宋体”即可解决。

除了汉字的各种书籍信息,还可以查它的古文字字形,每个古文字图片下还有它的编号,便于索引。这里,因为上面的“覅”信息太少,我再以常用字“我”为例。

丰富吧?
但还有一个问题,字是查到了,信息也全,但一些老师同学是为研究来的,光有书,没版本和出版社之类的信息不好引用,还得找纸质书,麻烦!

这个麻烦最近也得到了解决(感谢站长“外星人”)。如果要引用国学大师网中书籍的信息,可以见下:

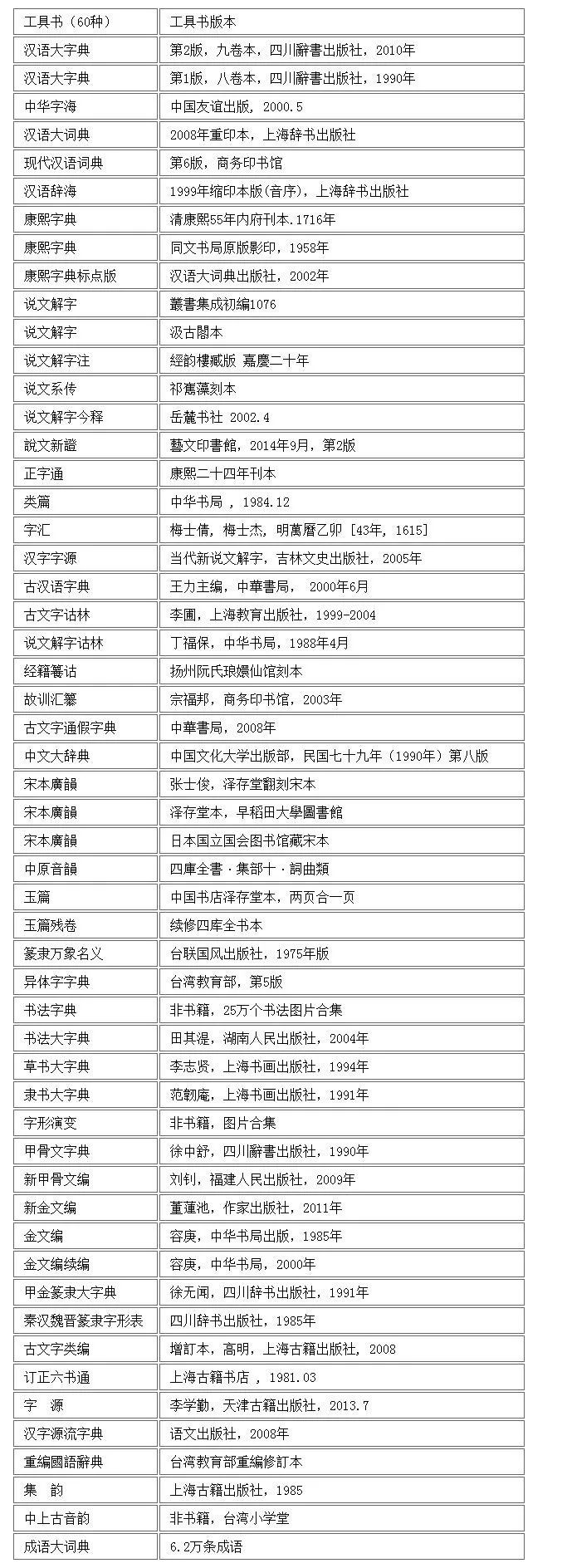
以上信息和图片来自国学大师网站官方群(),感兴趣或者想赞助的朋友可以加下。
说到赞助,这里说下,国学大师网不是盈利性网站,是站长“外星人”及网友们众筹建立起来的,没有广告(如果你手机有,那不是网站推送,是运营商劫持,详情可以百度或者谷歌),没有会员,网站上的东西都是免费。考虑到网站运行比如服务器都需要资金,因而会在网站首页出售U盘硬盘资料。

回到查字上来。在查“覅”字的时候,细心的朋友可能还会发现,“部件查字”的页面有三个搜索框。
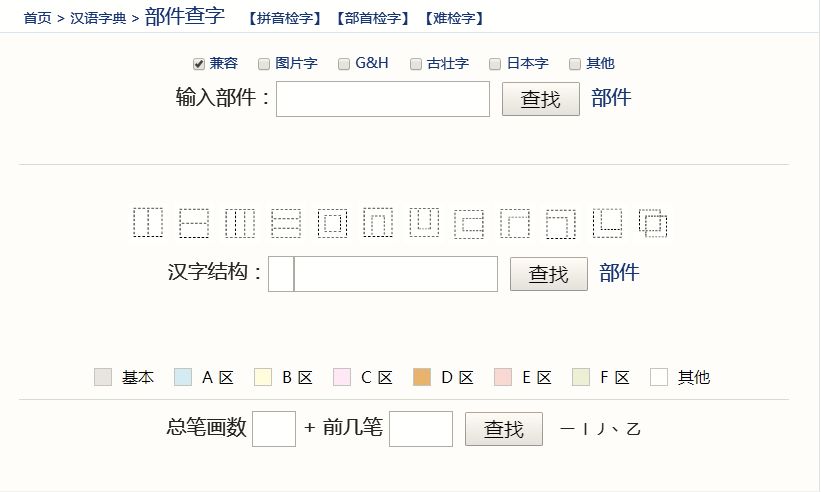
这代表的是三种不同的搜索方法。第一种(如上的动图)是比较模糊,也是比较简单的一种方法。注意上面的搜索框上面的几个空格,默认网站的“兼容”就行了,乱选可能导致自己查不到字;

第二种也是比较精确的查法,它的搜索框上面还有一排虚线方框,大家看到了吗?
这些方框代表的是字的结构。比如
代表的是左右结构,
则代表的是上下结构,其他的类推。知道这个字什么结构,选中可以查得更快。比如查“覅”,输入“要勿”,第一种不限定字形结构,会查出三个字(三个异体字,实际是一个),而第二种只会显示一个。



第三种一看就会,就不解释了。

考虑到一些部件输入法不好打,大家可以在“部件查字”右边栏根据部件的笔画查找。
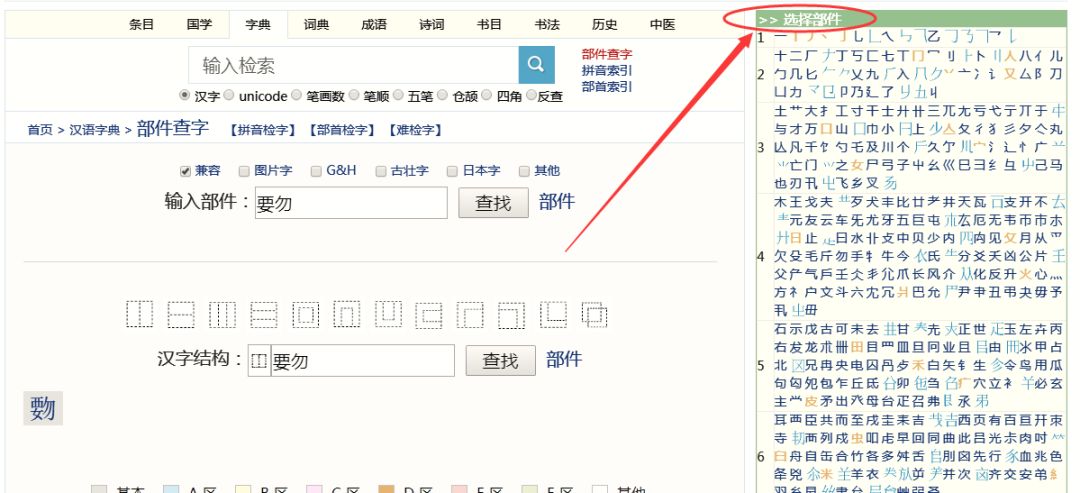
除了查今文字,古文字也是可以查的。点击国学大师网()首页上的“篆书识别”,进入页面,根据你要查的古文字,从右边栏里找篆书部件,按“部件查字”的方法输入。
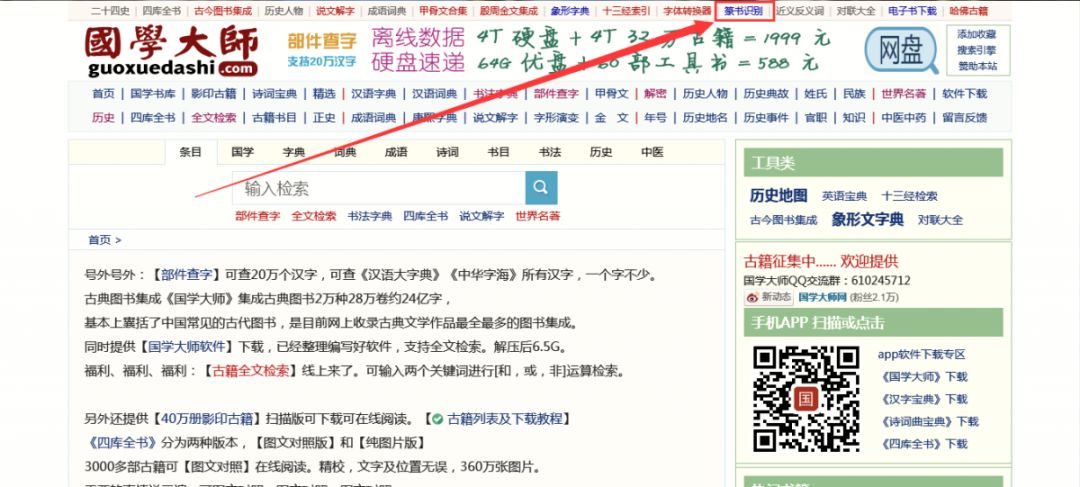
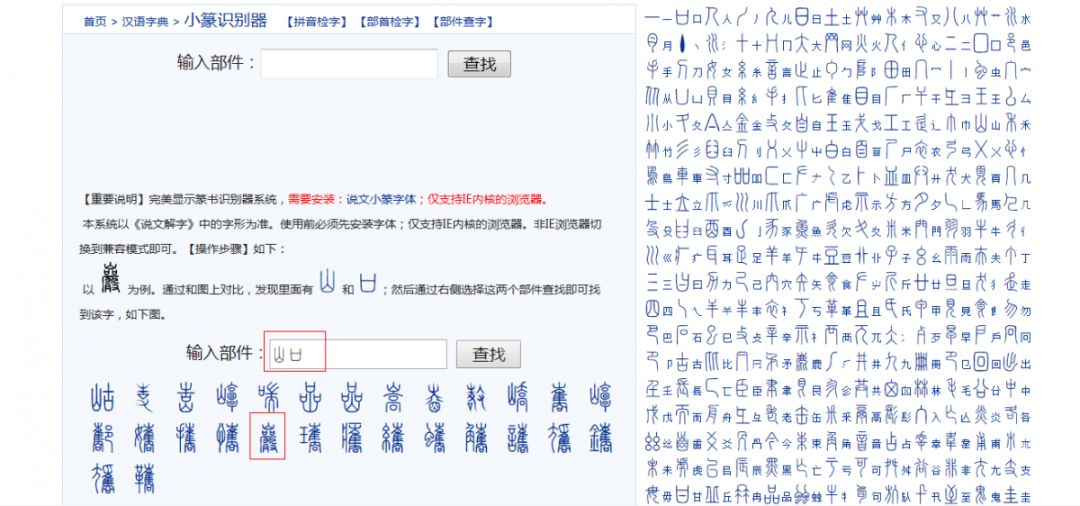
如果你点击“篆书识别”,跳转页面发现你的浏览器是这样显示的:
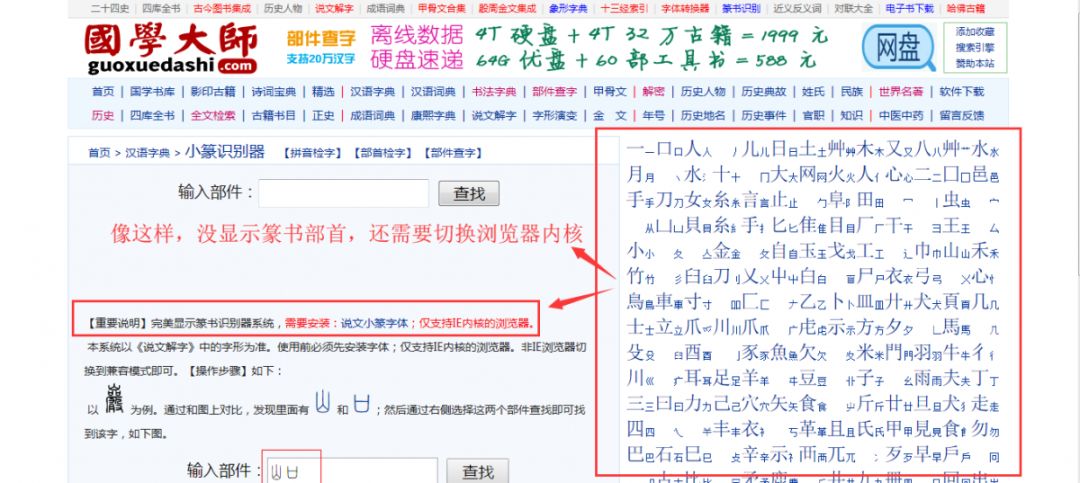
这表示你的电脑没安装说文小篆字体,点击页面中“说文小篆字体”下载安装。(电脑安装字体方法:下载字体至桌面,复制到C盘/Windows/Fonts下粘贴即可)
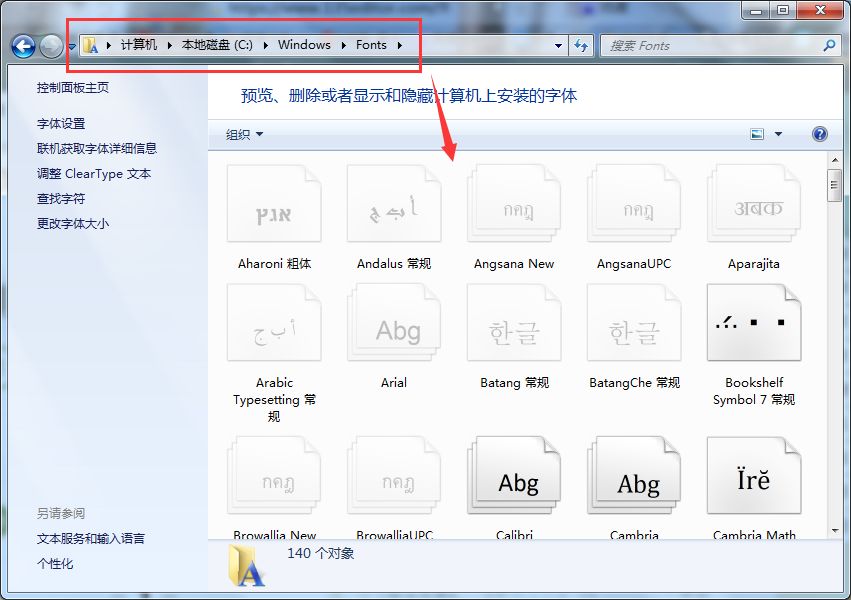
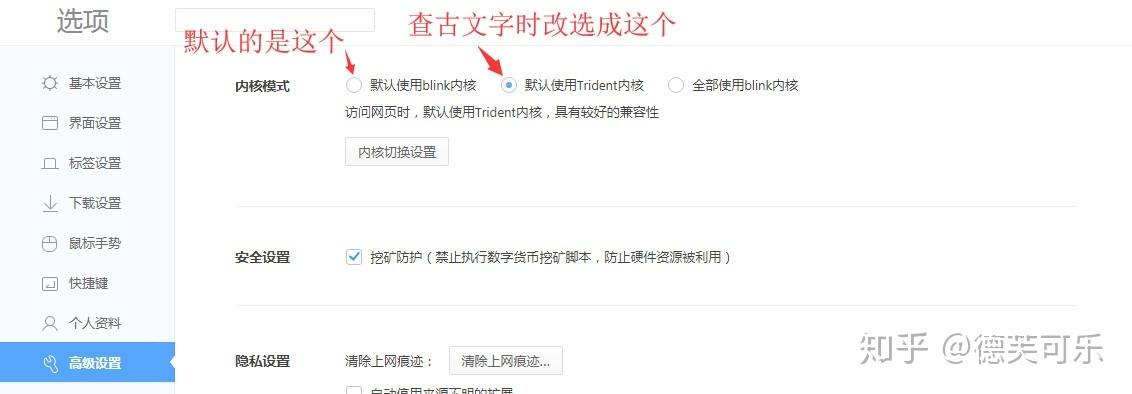
如果还是没变化,那就是阁下的浏览器内核兼容性不好,切换下内核就行了。不同的浏览器默认的内核不一样,以360极速浏览器为例,默认的是blink内核,加载速度快,但兼容性不如Trident内核,方法:在浏览器“选项”里找“高级设置”,把默认内核改成Trident内核即可。
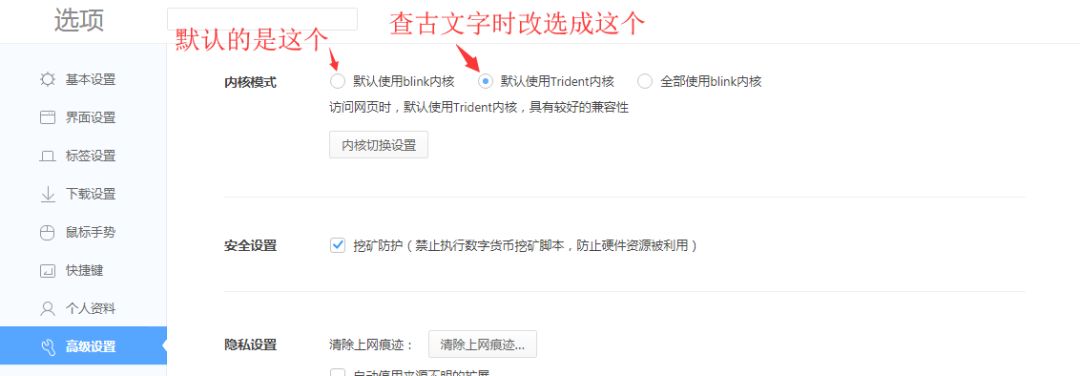
不常查古文字的老师同学,可以查完字后再改回blink内核。当然,有的浏览器可能不支持切换内核,那就没办法了,只能换个浏览器。

手机App“国学大师网”的操作也差不多,如果“篆书识别”用不了,建议电脑操作。
熟悉古文字与今文字的对照表(包括甲骨文古今汉字对照表、常用小篆体2500字对照字典等),根据对照表来比对(平时多看多练多写)
这种方法属于认字型,看到一个古文字,不好打,用国学大师网又不好查,那么根据对照表做一一比对也是一种切实可行的办法。因为古文字中可识的数量并不多,古今文字对照表收录的数量也不大(很久没人更新了),逐个排查并不会花费很多功夫。关于古今文字的对照表,网上有PDF文件下载,这里就不提供了。

如果以上方法都查不到,那就可以去请问老师或者前辈了。因为以上方法基本都覆盖了大部分的古今文字,查不到,也有可能是价值千金的未释字。
遇到这种字,如果不能变现,可以钻研一下……
详细动态网页、伪静态和静态网页的区别及相关知识(学习笔记)
个人博客:
以下为学习记录内容
Table of
1.定义 1.1动态网页
动态网页是一个对所有动态生成与动态更新的网页的统称。与传统的静态网页相反,它会因为变量的改变而产生不同的网页。这既可能是服务器端生成的网页,也可能是用户端生成的网页,或是两者的混合。
服务器端的动态网页是指服务器通过应用程序服务器处理服务器端脚本而生成的网页。服务器传递给脚本的参数决定了每一个网页的生成方式,有时包括如何生成更多的用户端脚本。常见的实现方式有PHP,Active Server Pages(Asp),通用网关接口(CGI)。在服务器端脚本执行完毕后,生成的网页是一个标准的HTML页面,所有的服务器端的脚本不会传给客户端。
用户端的动态网页在浏览器加载网页的时候进行处理。和其他脚本语言决定了收到的HTML如何嵌入到文档对象模型(DOM)中。这些脚本语言也可以动态地更新或改变最初的文档对象模型。
总结:动态网页是随操作而改变的网页,由脚本生成,可能是服务器端和用户端混合体。
1.2伪静态网页
伪静态是相对真实静态来讲的,通常我们为了增强搜索引擎的友好面,都将文章内容生成静态页面,但是有的朋友为了实时的显示一些信息。或者还想运用动态脚本解决一些问题。不能用静态的方式来展示网站内容。但是这就损失了对搜索引擎的友好面。怎么样在两者之间找个中间方法呢,这就产生了伪静态技术。伪静态技术是指展示出来的是以html一类的静态页面形式,但其实是用ASP一类的动态脚本来处理的。
总结:利用动态脚本处理静态页面后所生成的页面。
备注:伪静态只是改变了URL的表现形式,实际上还是动态页面
1.3 静态网页
静态页面,即静态网页,是实际存在的,无需经过服务器的编译,直接加载到客户浏览器上显示出来。静态页面需要占一定的服务器空间,且不能自主管理发布更新的页面,如果想更新网页内容,要通过FTP软件把文件DOWN下来用网页制作软件修改(通过fso等技术例外)。常见的静态页面举例:.html扩展名的、.htm扩展名的。
总结:我们下载中常看到以html结尾的就是静态网页,他们是自从出生就没有整过容,一直是那个样子。
2.各种网页的优缺点及特点 2.1 动态网页
优点:维护方便,易于查询数据,存储资源占用小
缺点:不利于搜索引擎收录,制作成本较高,需要人员维护
不利于收录:通常动态脚本需要某些信息来返回页面内容,最常见的如 Cookie 数据, 或一个环境变量。但对搜索引擎的 Spider 程序来说,它们压根不可能知道去使用你的搜索功能,或者该问什么问题。就是因为如此, Spider 对网站的检索往往会在一个动态站点前不得不止步。此外,在动态页的 URL 中包含了问号 (?) 和百分号 (%) 。还有一些符号诸如 & , % , + 和 $ 等在一个动态页的 URL 中也经常能看到。这样的 URL 被称作“环境变量” () 。不过大多数 SPIDER 都无法解读符号“ ? ”后的字符 。很显然,由于这个 URL 并不实际存在,所以它们一无所获。因此,如果你的整个网站或网站上有大部分网页都是采用动态来生成的,为了使 SPIDER 易于读取你网站上的内容,你需要对网站做一定的修改。还有一些搜索引擎在对页面进行检索时往往也会拒绝对 cgi-bin 目录下的静态页面 ( 即被保存成静态页面的动态页 )URL 进行检索 。
特点:把储存在数据库中内容以动态的形式展现在客户面前,并把客户的数据存储在数据库中留在以后使用。所以说网站中后台运行的数据库存储的信息更新的速度比较快。
2.2 伪静态网页
优点:易于收录
缺点:占用CPU较大
特点:静态页面的地址是真实存在的,路径当中不含有? &% 之类的变量符号,所以对搜索引擎来说更友好更容易得到信任,为了追求动态页面和静态页面的优点又回避缺点产生了 “ 伪静态 ” ,在动态页面的基础上通过 url 重写技术把转移参数插入到 url 地址中达到迷惑蜘蛛的作用。
2.3 静态网页
优点:速度快,可以跨平台,跨服务器,并且可以将数据库及后台系统与前台划分开,从而从提高站点的安全。
缺点:消耗资源大,交互性差,内容更新维护复杂
由于静态页面存放在服务器中药占据空间内存,可以想象如果某论坛有 10 万帖,每个帖的大小 100K ,如果全部作为静态页面存在于服务器中就要占据 10G 的大小,不包括存储计算中造成的空间浪费,所以相当消耗空间资源。
特点:静态网页每个网页都有一个固定的URL,且网页URL以.htm、.html、.shtml等常见形式为后缀,而不含有“?”。
3.文件格式
网页获取页面的格式:
4.工作原理
静态网页的工作流程可以分为以下4个步骤:
① 编写一个静态文件,并在web服务器上发布;
② 用户在浏览器的地址栏中输入该静态网页的URL并按回车键,浏览器发送访问请求到web服务器;
③ web服务器找到此静态文件的位置,并将它转换为HTML流传到用户的浏览器;
④ 浏览器收到HTML流后,显示此网页的内容。
动态网页的工作流程分为以下4个步骤:
① 编写动态网页文件,其中包括程序代码,并在web服务器上发布;
② 用户在浏览器的地址栏中输入该动态网页的URL并按回车键,浏览器发送访问请求到web服务器;
③ web服务器找到此动态网页的位置,并根据其中的程序代码动态建立HTML流传到用户的浏览器;
④ 浏览器收到HTML流后,显示此网页的内容。
5.相关问题答案 5.1搜索引擎为何不读取?后的内容
搜索引擎的 SPIDER 不愿意读取放在 cgi-bin 目录下的网页,或是 URL 中包含了符号“ ? ”的字符。其原因就在于,如果在 CGI 中提供了“无穷”数量的 URL ,那么 SPIDER 往往就会因为对这些“无穷”网页的检索而被牢牢套住,陷入死循环。这就是所谓的蜘蛛陷阱 () 。数据库程序对 SPIDER 亦有可能创建一个与此类似的情形。因而为避开可能的陷阱, Spider 对于那些带有符号“ ? ”的 URL 中的“ ? ”之后的字符一概不予读取。倘若 Spider 被你的服务器套住,不只是对 Spider 本身不妙, Spider 对你网站页面的重复访问请求也会导致你的服务器系统彻底瘫痪。
5.2 为什么伪静态网页容易被收录
在文章列表中把文章的连接如/blog/.do?=zy&&blogId=1&&=1转换成blog/a/3416.html这种URL,这样蜘蛛就可以进而爬进去看相应的内容了,因为文章列表中的每一篇文章都是不同的静态URL。
5.3 存在意义
爬虫不喜欢爬取带问号的动态网页,无论参数怎么加,返回内容一成不变,例如也会指向我的的首面。于是有了,它可以重新映射地址。对页面的地址Web服务器收到请求后并重新映射,然后再执行那个PHP程序。(以上网址均为假设)这样,在内部不改变的情况下,对外呈现出来的网址变成了没有问号的象静态网页的网址一样。
5.4 为什么爬虫会爬取伪动态网页
搜索引擎会不收录带问号的网址是因为搜索引擎怕由于问号而进入死循环(以前动网就有这样一个漏洞,蜘蛛进去出不来了),所以很多时候带问号的地址是不会进去的,伪静态对于搜索引擎来说,其实就是静态,因为地址中没有带问号。
静态页面的地址是真实存在的,路径当中不含有? &% 之类的变量符号,所以对搜索引擎来说更友好更容易得到信任,为了追求动态页面和静态页面的优点又回避缺点产生了 “ 伪静态 ” ,在动态页面的基础上通过 url 重写技术把转移参数插入到 url 地址中达到迷惑蜘蛛的作用。
6.相关知识 6.1 AJAX
AJAX即“ and XML”(异步的与XML技术),指的是一套综合了多项技术的浏览器端网页开发技术。
出现原因:
传统的Web应用允许用户端填写表单(form),当提交表单时就向网页服务器发送一个请求。服务器接收并处理传来的表单,然后送回一个新的网页,但这个做法浪费了许多带宽,因为在前后两个页面中的大部分HTML码往往是相同的。由于每次应用的沟通都需要向服务器发送请求,应用的回应时间依赖于服务器的回应时间。这导致了用户界面的回应比本机应用慢得多。
出现效果:
与此不同,AJAX应用可以仅向服务器发送并取回必须的数据,并在客户端采用处理来自服务器的回应。因为在服务器和浏览器之间交换的数据大量减少,服务器回应更快了。同时,很多的处理工作可以在发出请求的客户端机器上完成,因此Web服务器的负荷也减少了。
存在问题:
对应用Ajax最主要的批评就是,它可能破坏浏览器的后退与加入收藏书签功能。在动态更新页面的情况下,用户无法回到前一个页面状态,这是因为浏览器仅能记下历史记录中的静态页面。
总结:AJAX能够实现对网页的部分更新,保留无需更新的部分,以使得Web应用程序更为迅捷地回应用户动作。
参考:
Wiki百科,百度百科
网站静态化——伪静态&SEO
静态网页与动态网页的区别?
关于伪静态的特点和优点
*请认真填写需求信息,我们会在24小时内与您取得联系。
