整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
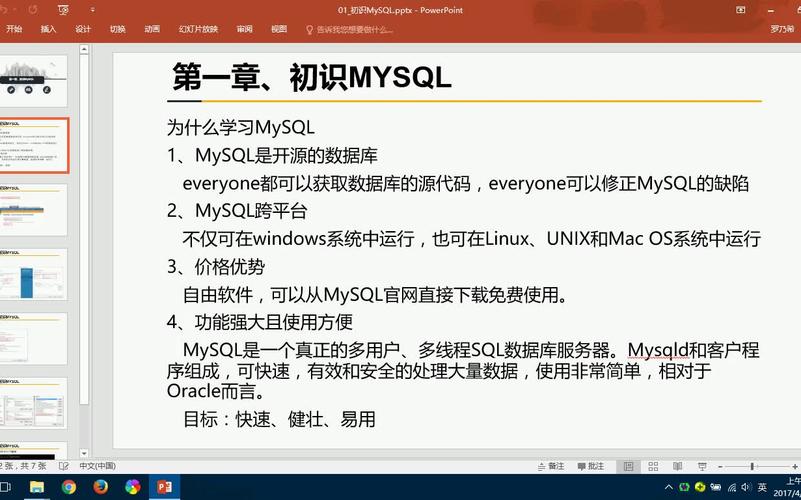
大数据从业者必知必会的Hive SQL调优技巧
摘要:在大数据领域中,Hive SQL被广泛应用于数据仓库的数据查询和分析。然而,由于数据量庞大和复杂的查询需求,Hive SQL查询的性能往往不尽人意。本文针对Hive SQL的性能优化进行深入研究,提出了一系列可行的调优方案,并给出了相应的优化案例和优化前后的SQL代码。通过合理的优化策略和技巧,能够显著提升Hive SQL的执行效率和响应速度。
关键词: Hive SQL;性能优化;调优方案;优化案例
1. 引言
随着大数据时代的到来,数据分析和挖掘变得越来越重要。Hive作为Hadoop生态系统中的数据仓库工具,扮演着重要的角色。然而,由于数据量庞大和查询复杂性,Hive SQL查询的执行效率往往较低。因此,深入了解Hive SQL调优技巧对于数据工程师和数据分析师来说至关重要。
2. 先做个自我反思
很多时候, Hive SQL 运行得慢是由开发人员对于使用的数据了解不够以及一些不良的使用习惯引起的。
•真的需要扫描这么多分区吗?
**比如,对于销售明细事务表来说,扫描一年的分区和扫描一周的分区所带来的计算、 IO 开销完全是两个量级,所耗费的时间肯定也是不同的。作为开发人员,我们需要仔细考虑业务的需求,尽量不要浪费计算和存储资源。
•习惯使用select *这样的方式,而不是用到哪些列就指定哪些列吗?
比如,select coll, col2 from ,另外, where 条件中也尽量添加过滤条件,以去掉无关的数据行,从而减少整个 任务中需要处理、分发的数据量。
•需要计算的指标真的需要从数据仓库的公共明细层来自行汇总吗?
是不是数仓团队开发的公共汇总层已经可以满足你的需求?对于通用的、管理者驾驶舱相关的指标等通常设计良好的数据仓库公共层肯定已经包含了,直接使用即可。

3 查询优化
3.1 尽量原子化操作
尽量避免一个SQL包含复杂逻辑,可以使用中间表来完成复杂的逻辑。建议对作业进行合理拆分,降低作业出问题重跑时资源的浪费和下游时效的影响。
3.2 使用合适的数据类型
选择合适的数据类型可以减小存储空间和提高查询效率。例如,将字符串类型转换为整型类型可以节省存储空间并加快查询速度。
优化案例
优化前:
SELECT * FROM table WHERE age = '30';
优化后:
SELECT * FROM table WHERE age = 30;
3.3 避免全表扫描
尽量避免全表扫描,可以通过WHERE子句筛选出需要的数据行,或者使用LIMIT子句限制返回结果的数量。
反面案例
天天全表扫描计算所有历史数据。 map数超20万。
Select * from table where dt<=’{TX_DATE}’
优化案例1
优化前:
--优化前副表的过滤条件写在where后面,会导致先全表关联再过滤分区。
select a.* from test1 a left join test2 b on a.uid = b.uid where a.ds='2020-08-10' and b.ds='2020-08-10'
优化后:
select a.* from test1 a left join test2 b on (b.uid is not null and a.uid = b.uid and b.ds='2020-08-10') where a.ds='2020-08-10'
优化案例2
利用max函数取表最大分区,造成全表扫描。
优化前:
Select max(dt) from table
优化后:
使用自定义(show partition 或 hdfs dfs –ls )的方式替代max(dt)
3.4 使用分区
数据分区是一种将数据按照某个字段进行分组存储的技术,可以有效减少查询时的数据扫描量。通过分区字段进行数据过滤,可以只对目标分区进行查询,加快查询速度。
优化案例
优化前:
SELECT * FROM table WHERE date = '2021-01-01' AND region = 'A';
优化后:
SELECT * FROM table WHERE partition_date = '2021-01-01' AND partition_region = 'A';
反面案例
代码写死日期,一次性不合理扫描2年+日志数据。map数超20万,而且会越来越大,直到跑不出来。
Select * from table where src_mark=’23’ and dt between ‘2020-05-16’ and ‘{TX_DATE}’ and scr_code is not null
3.5 使用索引
在Hive SQL中,可以通过创建索引来加速查询操作。通过在关键字段上创建索引,可以减少数据扫描和过滤的时间,提高查询性能。
优化案例
优化前:
SELECT * FROM table WHERE region = 'A' AND status = 'ACTIVE';
优化后:
CREATE INDEX idx_region_status ON table (region, status);
SELECT * FROM table WHERE region = 'A' AND status = 'ACTIVE';
3.6 查询重写
查询重写是一种通过改变查询语句的结构或使用优化的查询方式,来改善查询的性能的技巧。可以通过重写子查询、使用JOIN代替IN/EXISTS子查询等方法来优化查询。
优化案例
优化前:
SELECT * FROM table1 WHERE id IN (SELECT id FROM table2 WHERE region = 'A');
优化后:
SELECT * FROM table1 t1 JOIN (SELECT id FROM table2 WHERE region = 'A') t2 ON t1.id = t2.id;
3.7 谓词下推
谓词下推是一种将过滤条件尽早应用于查询计划中的技术(即SQL语句中的WHERE谓词逻辑都尽可能提前执行),减少下游处理的数据量。通过将过滤条件下推至数据源,可以减少查询数据量,提升查询性能。
优化案例
优化前:
select a.*,b.* from a join b on a.name=b.name where a.age>30
优化后:

SELECT a.*, b.* FROM ( SELECT * FROM a WHERE age > 30 ) a JOIN b ON a.name = b.name
3.8 不要用COUNT
COUNT 操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT 使用先GROUP BY再COUNT的方式替换,虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
优化案例
优化前:
select count(distinct uid) from test where ds='2020-08-10' and uid is not null
优化后:
select count(a.uid) from (select uid from test where uid is not null and ds = '2020-08-10' group by uid) a
3.9 使用with as
拖慢hive查询效率出了join产生的shuffle以外,还有一个就是子查询,在SQL语句里面尽量减少子查询。with as是将语句中用到的子查询事先提取出来(类似临时表),使整个查询当中的所有模块都可以调用该查询结果。使用with as可以避免Hive对不同部分的相同子查询进行重复计算。
优化案例
优化前:
select a.* from test1 a left join test2 b on a.uid = b.uid where a.ds='2020-08-10' and b.ds='2020-08-10'
优化后:
with b as select uid from test2 where ds = '2020-08-10' and uid is not null select a.* from test1 a left join b on a.uid = b.uid where a.ds='2020-08-10' and a.uid is not null
3.10 大表Join小表
在编写具有Join操作的查询语句时,有一项重要的原则需要遵循:应当将记录较少的表或子查询放置在Join操作符的左侧。这样做有助于减少数据量,提高查询效率,并有效降低内存溢出错误的发生概率。
如果未指定MapJoin,或者不符合MapJoin的条件,Hive解析器将会将Join操作转换成Common Join。这意味着Join操作将在Reduce阶段完成,由此可能导致数据倾斜的问题。为了避免这种情况,可以通过使用MapJoin将小表完全加载到内存中,并在Map端执行Join操作,从而避免将Join操作留给Reducer阶段处理。这种策略有效地减少了数据倾斜的风险。
优化案例
--设置自动选择Mapjoin
set hive.auto.convert.join = true; 默认为true
--大表小表的阈值设置(默认25M以下认为是小表):
set hive.mapjoin.smalltable.filesize=25000000;
3.11 大表Join大表
3.11.1 空key过滤
有时候,连接操作超时可能是因为某些key对应的数据量过大。相同key的数据被发送到相同的reducer上,由此导致内存不足。在这种情况下,我们需要仔细分析这些异常的key。通常,这些key对应的数据可能是异常的,因此我们需要在SQL语句中进行适当的过滤。
3.11.2 空key转换
当某个key为空时,尽管对应的数据很丰富,但并非异常情况。在执行join操作时,这些数据必须包含在结果集中。为实现这一目的,可以考虑将表a中那些key为空的字段赋予随机值,以确保数据能够均匀、随机地分布到不同的reducer上。
3.12 避免笛卡尔积
在执行join操作时,若不添加有效的on条件或者使用无效的on条件,而是采用where条件,可能会面临关联列包含大量空值或者重复值的情况。这可能导致Hive只能使用一个reducer来完成操作,从而引发笛卡尔积和数据膨胀问题。因此,在进行join时,务必注意确保使用有效的关联条件,以免由于数据的空值或重复值而影响操作性能。
优化案例
优化前:
SELECT * FROM A, B;
--在优化前的SQL代码中,使用了隐式的内连接(JOIN),没有明确指定连接条件,导致产生了笛卡尔积
优化后;
SELECT * FROM A CROSS JOIN B;
在优化后的SQL代码中,使用了明确的交叉连接(CROSS JOIN),确保只返回A和B表中的所有组合,而不会产生重复的行。 通过明确指定连接方式,可以避免不必要的笛卡尔积操作,提高查询效率。
4. 数据加载和转换
4.1 使用压缩格式
在数据加载过程中,选择合适的数据存储格式(对于结构化数据,可以选择Parquet或ORC等列式存储格式;对于非结构化数据,可以选择或等格式),可以提高查询性能和减少存储空间。
优化案例
优化前:
LOAD DATA INPATH '/path/to/data' INTO TABLE table;
优化后:
LOAD DATA INPATH '/path/to/data' INTO TABLE table STORED AS ORC;
4.2 数据转换和过滤
在数据加载之前,对数据进行转换和过滤可以减小数据量,并加快查询速度。例如,可以使用Hive内置函数对数据进行清洗和转换,以满足特定的查询需求。
优化案例
优化前:
SELECT * FROM table WHERE name LIKE '%John%';
优化后:
SELECT * FROM table WHERE name = 'John';
4.3 多次INSERT单次扫描表
默认情况下,Hive会执行多次表扫描。因此,如果要在某张hive表中执行多个操作,建议使用一次扫描并使用该扫描来执行多个操作。
比如将一张表的数据多次查询出来装载到另外一张表中。如下面的示例,表是一个分区表,分区字段为dt,如果需要在表中查询2个特定的分区日期数据,并将记录装载到2个不同的表中。
INSERT INTO temp_table_20201115 SELECT * FROM my_table WHERE dt ='2020-11-15';
INSERT INTO temp_table_20201116 SELECT * FROM my_table WHERE dt ='2020-11-16';
在以上查询中,Hive将扫描表2次,为了避免这种情况,我们可以使用下面的方式:
FROM my_table
INSERT INTO temp_table_20201115 SELECT * WHERE dt ='2020-11-15'
INSERT INTO temp_table_20201116 SELECT * WHERE dt ='2020-11-16'
这样可以确保只对表执行一次扫描,从而可以大大减少执行的时间和资源。
5. 性能评估和优化
5.1 使用EXPLAIN命令
使用EXPLAIN命令可以分析查询计划并评估查询的性能。通过查看查询计划中的资源消耗情况,可以找出潜在的性能问题,并进行相应的优化。
优化案例
优化前:
EXPLAIN SELECT * FROM table WHERE age = 30;
优化后:
EXPLAIN SELECT * FROM table WHERE age = 30 AND partition = 'partition1';
5.2 调整并行度和资源配置
根据集群的配置和资源情况,合理调整Hive查询的并行度和资源分配,可以提高查询的并发性和整体性能。通过设置参数hive.exec.值为true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。建议在数据量大,sql很长的时候使用,数据量小,sql比较的小开启有可能还不如之前快。
优化案例
优化前:
SET hive.exec.parallel=true;
优化后:
SET hive.exec.parallel=false; SET hive.exec.reducers.max=10;
6. 数据倾斜
任务进度长时间维持在99%(或100%),检查任务监控页面后发现仅有少量(1个或几个)reduce子任务未完成。这些未完成的reduce子任务由于处理的数据量与其他reduce子任务存在显著差异。具体而言,单一reduce子任务的记录数与平均记录数之间存在显著差异,通常可达到3倍甚至更多。此外,未完成的reduce子任务的最长时长明显超过了平均时长。主要原因可以归结为以下几种:
6.1 空值引发的数据倾斜
在数据仓库中存在大量空值(NULL)的情况下,导致数据分布不均匀的现象。这种数据倾斜可能会对数据分析和计算产生负面影响。当数据仓库中某个字段存在大量空值时,这些空值会在数据计算和聚合操作中引起不平衡的情况。例如,在使用聚合函数(如SUM、COUNT、AVG等)对该字段进行计算时,空值并不会被包括在内,导致计算结果与实际情况不符。数据倾斜会导致部分reduce子任务负载过重,而其他reduce子任务负载较轻,从而影响任务的整体性能。这可能导致任务进度长时间维持在99%(或100%),但仍有少量reduce子任务未完成的情况。
优化方案
第一种:可以直接不让null值参与join操作,即不让null值有shuffle阶段。
第二种:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中。
6.2 不同数据类型引发的数据倾斜
在数据仓库中,不同数据类型的字段可能具有不同的取值范围和分布情况。例如,某个字段可能是枚举类型,只有几个固定的取值;而另一个字段可能是连续型数值,取值范围较大。当进行数据计算和聚合操作时,如果不同数据类型的字段在数据分布上存在明显的差异,就会导致数据倾斜。数据倾斜会导致部分reduce子任务负载过重,而其他reduce子任务负载较轻,从而影响任务的整体性能。这可能导致任务进度长时间维持在99%(或100%),但仍有少量reduce子任务未完成的情况。
优化方案
如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了。
6.3 不可拆分大文件引发的数据倾斜
在Hadoop分布式计算框架中,数据通常会被切分成多个数据块进行并行处理。然而,当遇到一些无法被切分的大文件时,这些大文件会被作为一个整体分配给一个reduce任务进行处理,而其他reduce任务则可能得到较小的数据量。这导致部分reduce任务负载过重,而其他任务负载较轻,从而影响任务的整体性能。
优化方案
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。
所以,我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。
6.4 数据膨胀引发的数据倾斜
数据膨胀通常是由于某些数据在仓库中存在大量冗余、重复或者拆分产生的。当这些数据被用于计算和聚合操作时,会导致部分reduce子任务负载过重,而其他reduce子任务负载较轻,从而影响任务的整体性能。
优化方案
在Hive中可以通过参数
hive.new.job..set. 配置的方式自动控制作业的拆解,该参数默认值是30。表示针对 sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
6.5 表连接时引发的数据倾斜
在数据仓库中,表连接是常用的操作,用于将不同表中的数据进行关联和合并。然而,当连接键在不同表中的数据分布不均匀时,就会导致连接结果中某些连接键对应的数据量远大于其他连接键的数据量。这会导致部分reduce任务负载过重,而其他任务负载较轻,从而影响任务的整体性能。
优化方案
通常做法是将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。
6.6 确实无法减少数据量引发的数据倾斜
在某些情况下,数据的数量本身就非常庞大,例如某些业务场景中的大数据集,或者历史数据的积累等。在这种情况下,即使采取了数据预处理、数据分区等措施,也无法减少数据的数量。
优化方案
这类问题最直接的方式就是调整reduce所执行的内存大小。
调整reduce的内存大小使用
.reduce.memory.mb这个配置。
7. 合并小文件
在HDFS中,每个小文件对象约占150字节的元数据空间,如果有大量的小文件存在,将会占用大量的内存资源。这将严重限制节点的内存容量,进而影响整个集群的扩展能力。从Hive的角度来看,小文件会导致产生大量的Map任务,每个Map任务都需要启动一个独立的JVM来执行。这些任务的初始化、启动和执行会消耗大量的计算资源,严重影响性能,因为每个小文件都需要进行一次磁盘IO操作。
因此,我强烈建议避免使用包含大量小文件的数据源。 相反,我们应该进行小文件合并操作,以减少查询过程中的磁盘IO次数,从而提高查询效率。通过合并小文件,我们可以将多个小文件合并成一个较大的文件,从而减少对磁盘的IO访问次数。这样可以降低系统资源的消耗,提高查询性能。
因此,在构建数据仓库时,应该尽可能使用较大的文件来存储数据,避免大量小文件的产生。如果已经存在大量小文件,可以考虑进行小文件合并操作,以优化数据存储和查询性能。这样可以提高Hive查询的效率,减少资源的浪费,并保证系统的稳定性和可扩展性。
7.1 Hive引擎合并小文件参数
--是否和并Map输出文件,默认true
set hive.merge.mapfiles = true;
--是否合并 Reduce 输出文件,默认false
set hive.merge.mapredfiles = true;
--合并文件的大小,默认字节
set hive.merge.size.per.task = 256000000;
--当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge,默认字节
set hive.merge.smallfiles.avgsize = 256000000;
7.2 Spark引擎合并小文件参数,所以尽量将MR切换成Spark
--是否合并小文件,默认true
conf spark.sql.hive.mergeFiles=true;
8. 结论
本论文介绍了大数据从业者必备的Hive SQL调优技巧,包括查询优化、数据分区和索引、数据加载和转换等方面。通过深入理解Hive SQL语言和优化策略,开发人员可以提升查询效率和性能。通过优化案例和优化前后的SQL代码,展示了每种优化方案的实际应用效果。****
附:实践案例
一、背景
某公司的线上平台每天产生大量的用户数据,包括用户行为、订单信息等。为了更好地分析用户行为和业务趋势,我们需要对数据进行复杂的查询操作。原始的Hive SQL语句在执行时存在性能瓶颈,因此我们决定对其进行优化。
二、原始SQL语句
原始的Hive SQL语句如下:
SELECT * FROM user_data WHERE user_id IN (SELECT user_id FROM order_data WHERE order_date >= '2022-01-01')
这个查询语句的目的是从表中选取所有在表中最近一个月有订单的用户数据。由于表和表的数据量都很大,这个查询语句执行时间较长,存在性能瓶颈。
三、优化策略
针对原始SQL语句的性能瓶颈,我们采取了以下优化策略:
使用Spark计算引擎:Spark是一种高效的分布式计算框架,可以与Hive SQL集成使用来提高查询效率。我们将使用Spark计算引擎来执行查询。
使用JOIN操作:将两个表通过JOIN操作连接起来,可以减少数据的传输和计算开销。我们将使用JOIN操作来连接表和表。
使用过滤条件:在查询过程中,使用过滤条件可以减少数据的处理量。我们将使用过滤条件来筛选出符合条件的用户数据。
四、优化后的SQL语句
基于上述优化策略,我们优化后的Hive SQL语句如下:
SELECT u.* FROM user_data u JOIN (SELECT user_id FROM order_data WHERE order_date >= '2022-01-01') o ON u.user_id = o.user_id
这个查询语句使用了JOIN操作将表和子查询结果连接起来,并通过过滤条件筛选出符合条件的用户数据。同时,我们使用了Spark计算引擎来执行查询。
五、性能对比
我们对优化前后的SQL语句进行了性能对比。以下是性能对比的结果:
执行时间:优化后的SQL语句执行时间比原始SQL语句减少了约50%。
数据传输量:优化后的SQL语句减少了数据的传输量,提高了数据处理的效率。
内存消耗:优化后的SQL语句使用了Spark计算引擎,可以更好地利用内存资源,提高了查询性能。
通过对比可以看出,优化后的SQL语句在执行时间、数据传输量和内存消耗等方面都取得了显著的提升。
i.MX6ULL开发板-Buildroot制作交叉编译器
前言
文章基于HD-IMX6ULL-MB 系列开发板测试验证,该开发板由武汉芯路遥科技有限公司与武汉万象奥科电子有限公司合作推出。此开发板基于 NXP iMX6ULL 系列 Cortex-A7 高性能处理器设计,适用于快速开发一系列具有创新性的产品如人机界面工业 4.0 扫描仪、车载终端以及便携式医疗设备。

1. 制作交叉编译器
在前面我们提到,如果想要自己制作交叉编译器的话,通常会用到两个工具,分别是 -NG 和 。但需要了解的是制作交叉编译器只是嵌入式开发的第一步,后面我们还需要使用交叉编译器来移植 、linux kernel 以及制作根文件系统 rootfs,之后还会用它来交叉编译各种所需要的应用程序。其中 -NG 只是制作了一个交叉编译器,而如果你希望一键完成这所有的事情, 则可以使用 。
如果你是一个嵌入式软件工程师,那你有必要要知道是什么。这个工具除了可以制 作交叉编译器以外,还提供了一种更加高效的管理方法,它把,linux,应用程序和rootfs集 成在一起,可以非常方便的去定制,管理,编译和组装一个自己需要的,针对自己的设备的一个完整的 软件系统,这样我们可以利用针对自己的嵌入式设备开发完整的BSP和SDK。
接下来我们将介绍如何使用 来制作交叉编译器,同时生成一个开发板可以使用的根文件系统。需要注意的是,因为 Linux 内核 和 u-boot 今后需要自己针对开发板做移植修改,所以这里将不编译 Linux内核 和 u-boot 程序。
1. 介绍
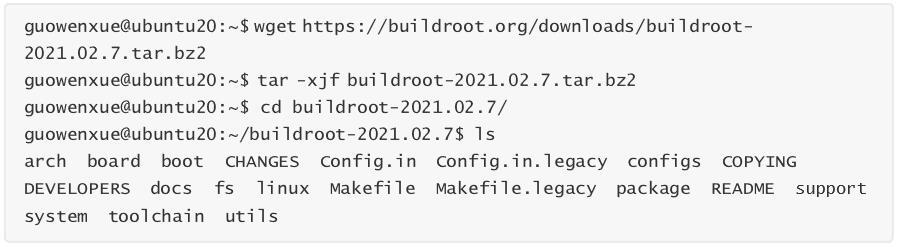
官网首页对的定义,和特点有非常明确的介绍: h ttps:/// 。

这里,我们从的官方下载地址下载当前的最新长期支持版本 -2021.02.7 并解压缩。
整个是由(*.mk)脚本和Kconfig(Config.in)配置文件构成的,因此可以像配置Linux内 核一样执行make 进行配置,编译出一个完整的、可以直接烧写到机器上运行的Linux系统文件(包含、kernel、rootfs以及rootfs中的各种库和应用程序)。而构建开源软件包的流程, 工作流大致如下:
构建每个软件包的工作流几乎是相同的,主要就是把这些重复操作自动化,用户只需勾选上所 需软件包,便自动完成以上所有操作。其次,U-boot、Linux Kernel的编译工作流的差不多,只是配置的自定义参数更多,在设置好了,也就一并生成。
1. 配置
在 源码路径下,有很多参考的示例配置,其中就包含有 的参考配置。我们没有必要所有的选项都自己从0开始配置,接下来我们将在它的基础上来修改。

如果是使用 远程登录到Linux服务器上操作的话,需要 export TERM=vt100 命令配置TERM 环境变量,否则接下来的配置可能不能输入。接下来再执行 make 对交叉编译器制作进行配置。
下面是 的配置界面,接下来我们将对齐进行配置。在配置的过程中:
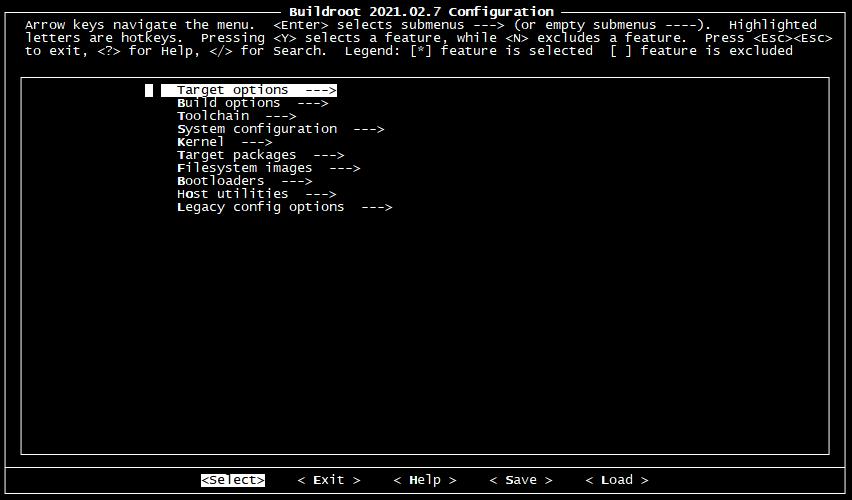
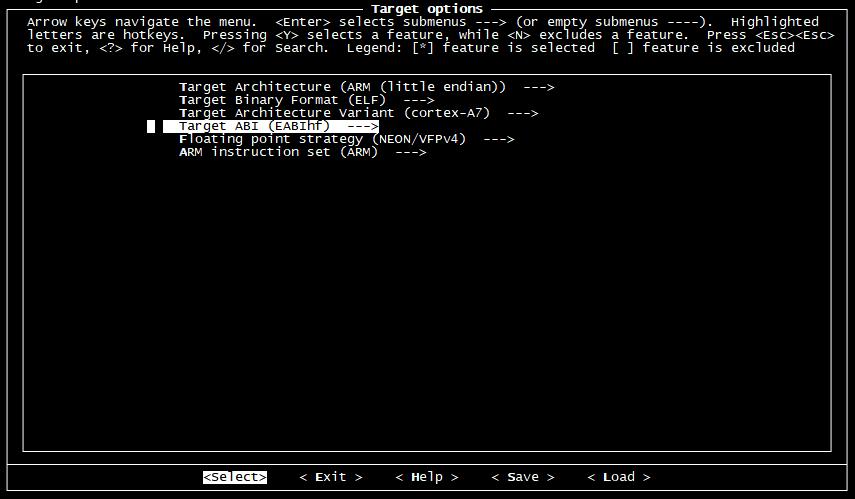
在 Target options 选项中 ,这里配置了交叉编译器的体系架构信息。因为我们的开发板所有的处理器
i.MX6ULL 是采样 Cortex-A7架构,带有 NEON 浮点运算,所以这里做如下的默认配置。
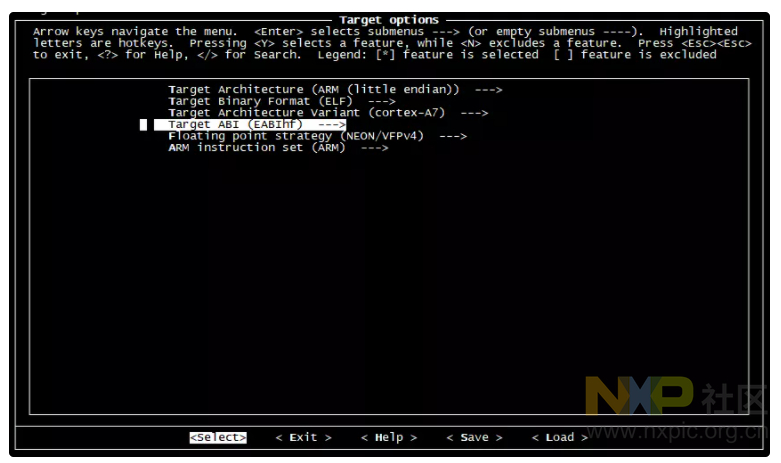
在 Build options 选项中 ,这里主要修改一下:
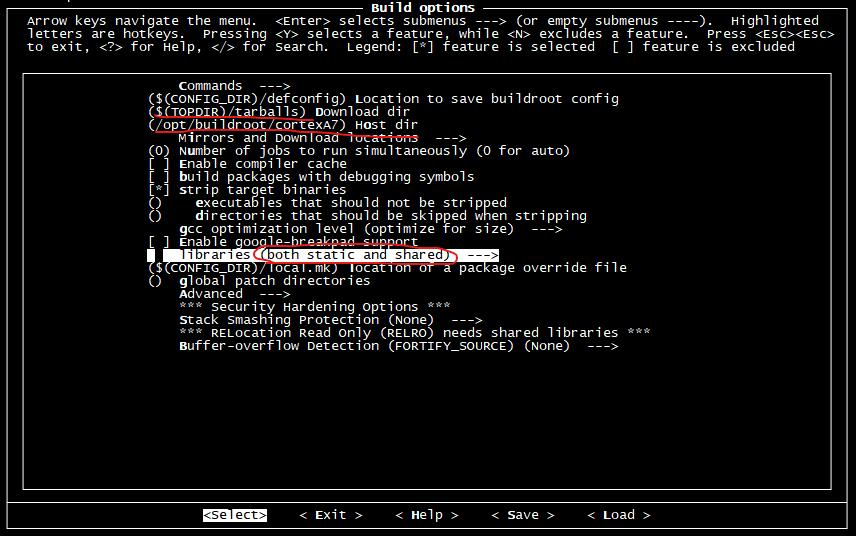
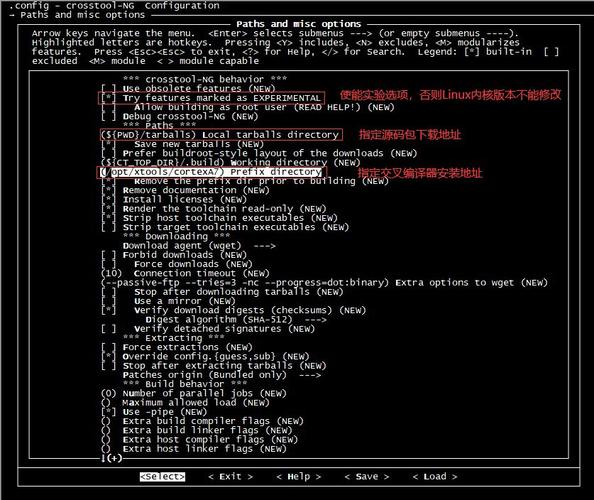
在 选项中,这里做如下修改:
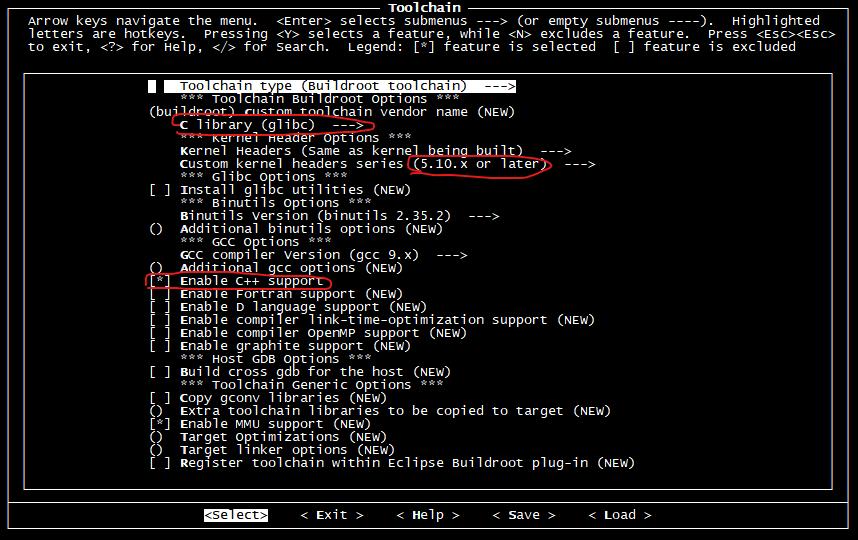
System 选项中配置了根文件系统的相关信息,我们做如下修改:
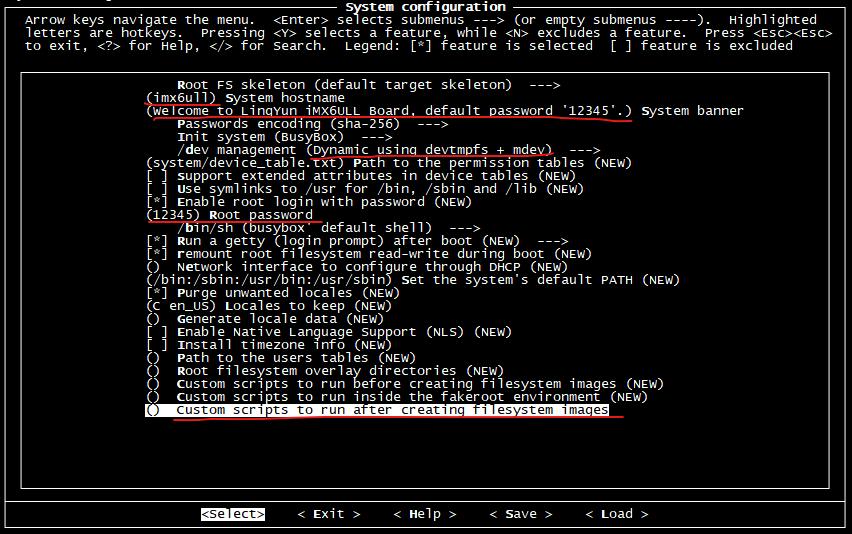
Kernel 选项主要是Linux内核的编译配置,今后我们将会自己移植并编译Linux内核,所以这里不要选择。
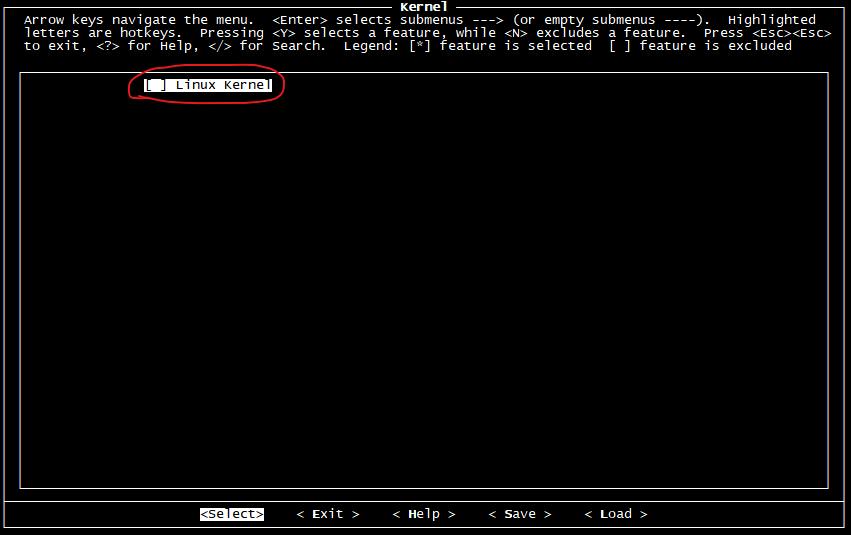
Target 选项这里有大量的应用程序或开源库编译选项,如果想制作到根文件系统树中的话, 这里可以做相应的选择。
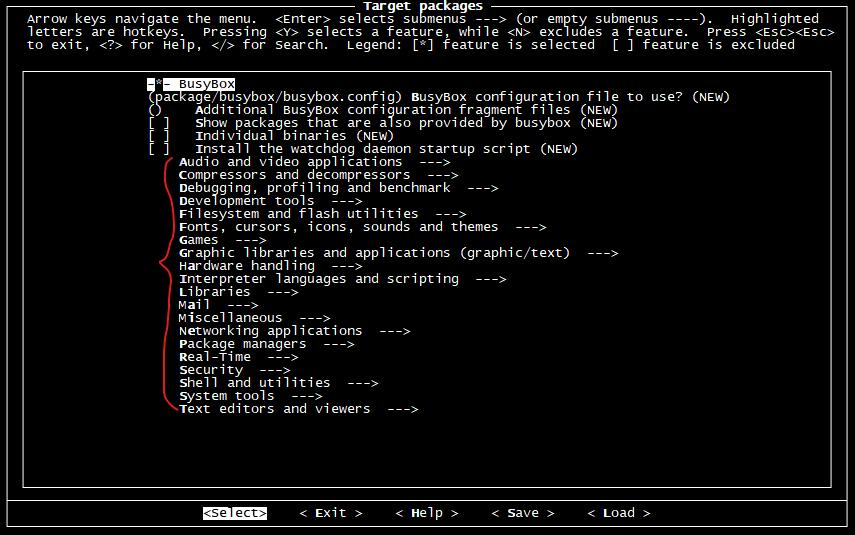
下面是一些建议可以选择的软件包:





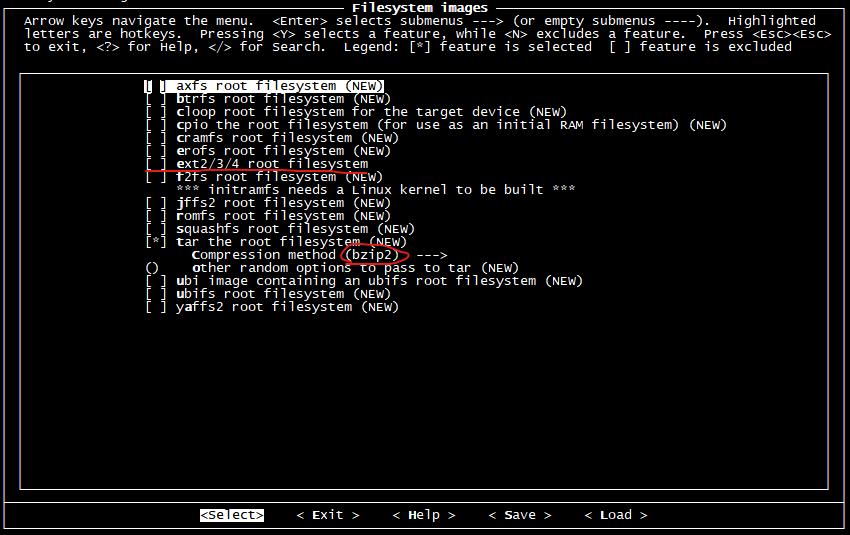
images 选项指定生成根文件系统镜像的类型,因为我们将来将会自己制作系统镜像,所以这里不需要生成。只需要将根文件系统树打包并使用 bzip2 压缩即可。
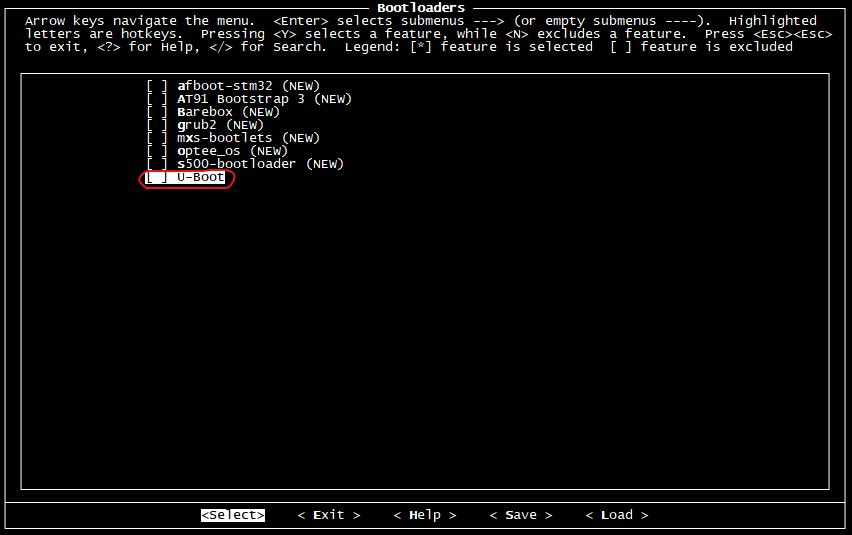
选项主要是u-boot的编译配置,今后我们将会自己移植并编译U-boot,所以这里不要选择。
Host 是在编译 过程中,X86主机上所依赖的一些工具。可以进去把一些能取消的都取消,从而节省编译时间;
Legacy config options 是一些过期作废的软件包,一般都不需要;
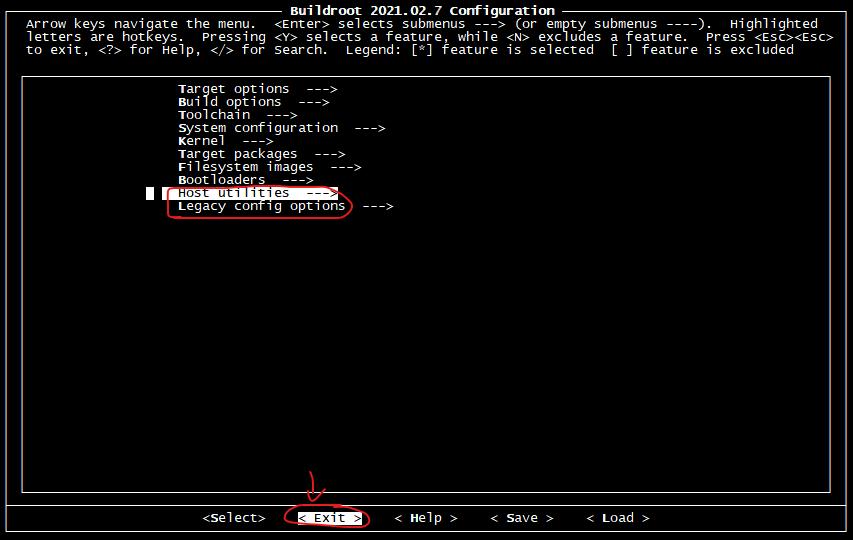
配置完成之后,选择 < Exit > 退出并保存该配置,这些配置将会保存在当前路径下的 .config 隐藏文件里。之后的编译过程将根据这里面的配置,选择下载、编译相关程序或代码。
1. 编译
首先创建交叉编译器的安装路径,注意制作交叉编译器别用 root 账号来完成,否则小心破坏自己的
Linux系统。

接下来我们就开始交叉编译的编译制作过程,这个过程的时间依赖PC的性能和所选择的选项多少。我的
Linux服务器处理器是Intel(R) Xeon(R) CPU E31235 @ 3.20GHz,4核8线程,所以我这里使用 make -j8
命令用8个进程同时编译。
编译成功完成之后,输出如下:
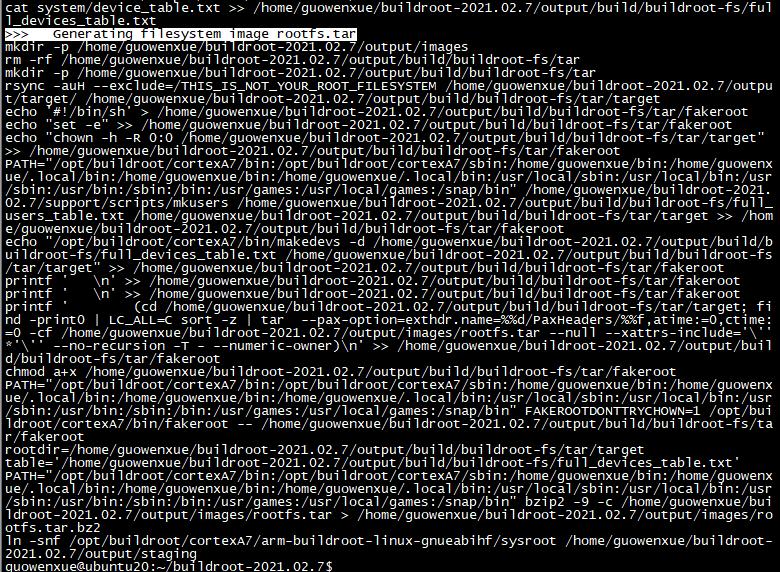
编译过程中 下载的源码包 将会放到 文件夹下:


编译生成的 根文件系统树 将会放到 output/images/ 文件夹下:

编译生成的 交叉编译器 将会放到 /opt// 路径下:

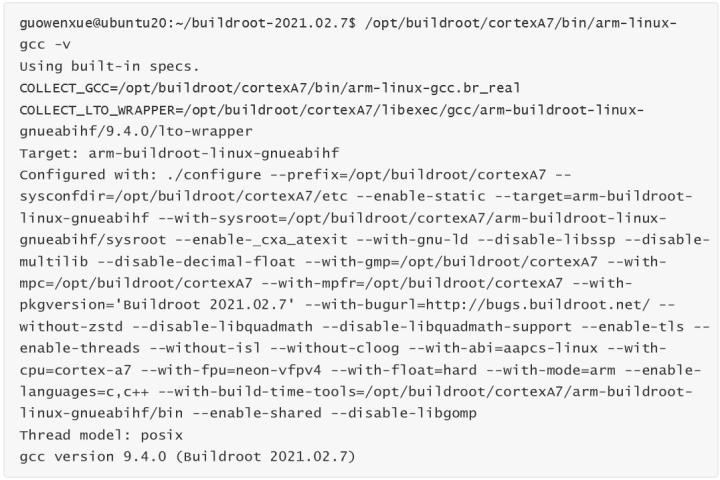
我们可以使用下面命令查看制作好的交叉编译器相关版本信息:
1.4 测试
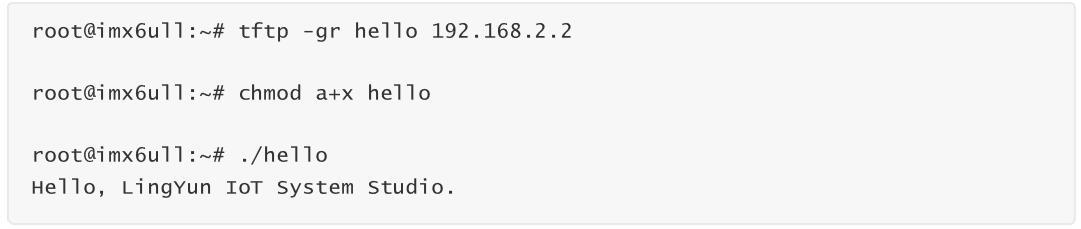
接下来我们使用制作好的交叉编译器,交叉编译之前写好的 hello.c 测试程序,并放到 ARM 开发板上运行测试。需要注意的是因为新制作的交叉编译器跟开发板上运行的C运行库版本不一致,这里必须加上 -static 进行静态链接,这样编译生成的程序才能在开发板上运行。

ARM 开发板上下载运行测试:
*请认真填写需求信息,我们会在24小时内与您取得联系。
