整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
【摘要】常用的关系型数据库有闭源系列和开源系列,闭源系列有国外数据库(如Oracle、DB2等)和国产数据库(如GaussDB T等);开源系列有MySQL、等。本文拟介绍几种常用关系型数据库的架构和实现原理,以方便广大用户更进一步了解。涉及产品最新参数指标等请以各官网为准。
【作者】范永清,系统架构师,现就职于厦门银行信息技术部,目前主要负责厦门银行技术架构设计。
一、 Oracle
(一) Oracle 架构
Oracle Server包括数据库()和实例()两大部分,两者相互独立。数据库由数据文件 、控制文件和日志文件组成,实例由内存池和后台进程组成,示意图如下:
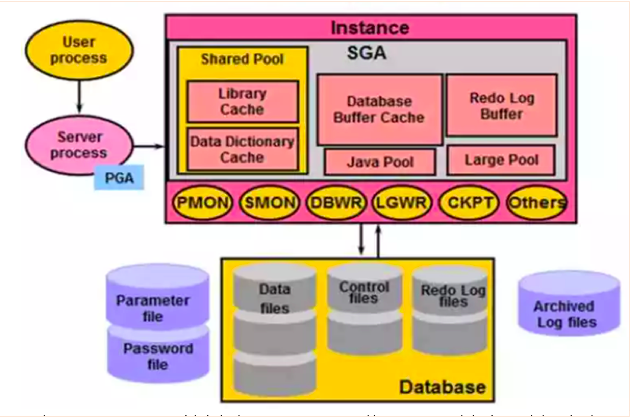
一台Oracle Server可创建多个,不同的之间相互独立。每个有属于自己的全套相关文件,如:密码文件,参数文件,数据文件,控制文件和日志文件
由一系列物理文件(如二维表文件)组成。用户不能直接读取中的内容,必须通过Oracle 才能读取,一个只能连接一个,但是一个可以被多个连接。
各功能组件说明如下:
1、用户连接进程
用户连接进程是连接用户和Oracle 的桥梁。包括:用户进程、服务进程和PGA
当一个 User请求连接到Oracle Server时,Oracle Server创建的User Process。
用于处理 User和Oracle Server之间的连接。
PGA:由Server Process分配,用于当前User Session的内存区,不同的用户拥有不同的PGA。PGA包含了Server Process数据和控制信息的内存区域。包括栈空间、 Session Info、 私有SQL区。
2、SGA(System Global Area)
SGA与Oracle性能息息相关,在启动时被分配,关闭时被释放。主要包含如下几种数据结构:
oracle 执行SQL语句的区域。当进行数据更新或数据查询时,用户执行的SQL语句不会直接对磁盘上的数据文件进行更改操作,而是首先将数据文件复制到数据库缓冲区缓存,再更改或查询缓存中的副本。此外,被频繁访问的数据块会存在于数据库缓冲区缓存中。
用于短期存储redo log。
用于缓存所有频繁执行的代码和频繁访问的对象定义。共享池内有下列三种数据结构:
用于共享的服务器进程。
只有当应用程序需要在数据库中运行java存储程序时,才需要java池。
3、后台进程
后台进程主要用于数据库管理 ,是Oracle 和Oracle 的联系纽带,分为核心进程和非核心进程。
1) 核心进程:
Server process连接Oracle后,通过数据库写进程(DBWn)将数据缓冲区中的“脏缓冲区” 的数据块写入到数据文件;
(CKPT)检查点进程主要用于更新数据文件头,更新控制文件和触发DBWn数据库写进程。
当后台进程执行失败后负责清理数据库缓存和闲置资源,是Oracle的自动维护机制。
用途如下:
用于记录数据库的改变和记录数据库被改变之前的原始状态,当满足以下条件时,激活LGWR:
2) 非核心进程
是可选的后台进程,当数据库处于模式时,自动归档redo log,并保存数据库的所有修改记录。
SGA(System Global Area)和后台进程组成。
4、存储结构
存储结构可从物理结构和逻辑结构两方面理解。
1) 物理结构
物理结构:是在操作系统中的文件集合,即:磁盘上的物理文件,主要由数据文件、控制文件、重做日志文件、归档日志文件、参数文件、口令文件组成。
数据文件、重做日志文件、控制文件、跟踪文件、警告文件属于数据库文件
数据文件是数据的存储仓库,数据被使用时才被调入内存中的。
重做日志文件包含对数据库所做的更改操作记录,在Oracle发生故障时能够恢复数据。
控制文件包含维护和验证数据库完整性的必要的信息。例如,控制文件用于识别数据文件和重做日志文件,一个数据库至少需要一个控制文件。
在 中运行的每一个后台进程都有一个跟踪文件(trace file)与之相连。Trace file记载后台进程所遇到的重大事件的信息。
是一种特殊的跟踪文件,每个数据库都有一个跟踪文件,同步记载数据库的消息和错误。
参数文件、口令文件、归档文件属于非数据库文件。
实例参数文件,当启动oracle实例时,SGA结构会根据此参数文件的设置内存,后台进程会据此启动。
用户通过提交/来建立会话,Oracle根据存储在数据字典的用户定义对用户名和口令进行验证。
是重做日志文件的脱机副本,这些副本可能对于从介质失败中进行恢复很必要。
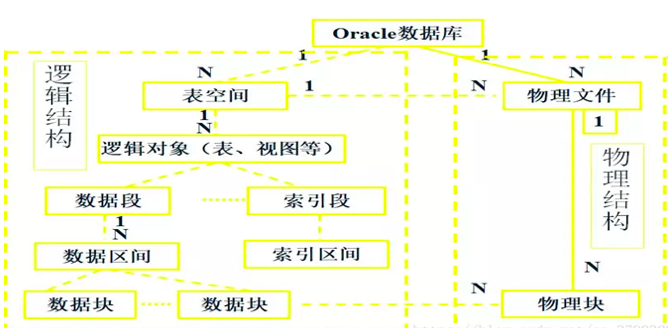
2) 逻辑结构
用于存储数据库对象的逻辑空间,是信息存储的最大逻辑单位,是一系列数据文件的集合。一个数据库可以由多个表空间组成,每个表空间包括多个段。
是对象在数据库中占用的空间。段是区的集合
是为数据一次性预留的一个较大的存储空间,区是块的集合
ORACLE最基本的存储单位,在建立数据库的时候指定,并被映射到磁盘块。
3) 逻辑空间到物理空间的映射
(二) Oracle RDBMS的运行过程
1. User访问Oracle Server之前提交一个请求(包含了db_name、、、等信息);
2. Oracle Server接收到请求并通过 File的验证后,分配SGA内存池,启动后台进程同时创建并启动实例;
3. 启动实例之后,User Process与Server Process建立Connect;
4. Server process和Oracle 建立,随后接收用户请求,执行相关操作;
(三) 写SQL语句的执行过程
1. 用户执行SQL语句,Server process收到后,将SQL语句送到,再将SQL语句载入数据库缓冲区。
2. Server Process通知Oracle 将与SQL语句相关的数据块副本加载到缓冲区中。
3. 在数据库缓存区执行SQL语句,修改数据文件副本,形成“脏缓冲区”
4. CKPT检查到”脏缓冲区”,调用DBWn数据库写进程,
5. 在DBWn运行之前,先运行了LGWR,将数据文件的原始状态和数据库的改变记录到Redo Log Files
6. 运行DBWn,将“脏缓冲区的内容写入到数据文件”
7. 同时CKPT修改控制文件和数据文件头
8. SMON回收不必要的空闲资源
9. 返回结果给用户
(四) Oracle的高可用性架构
1. Oracle RAC(Real )
RAC 是 Oracle 数据库的一个群集解决方案,包括计算层和存储层。如下图所示:
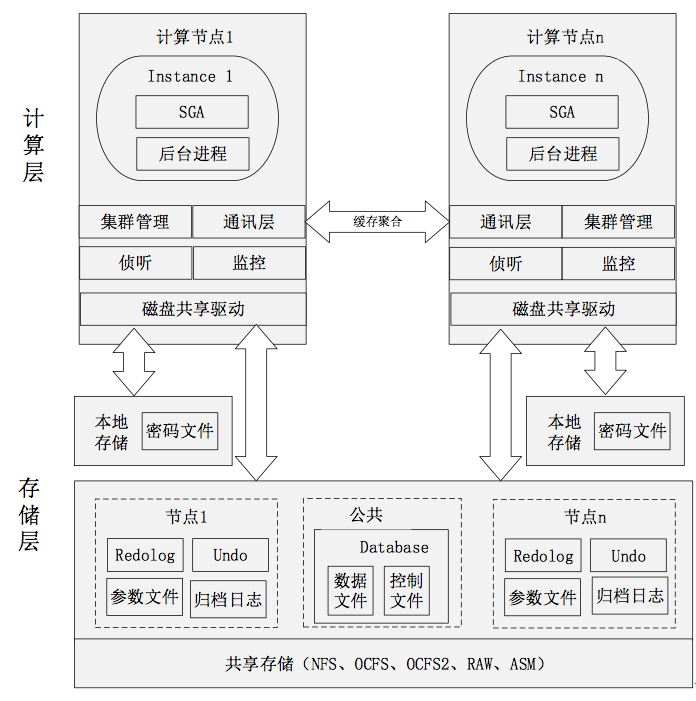
1) 存储层——共享存储
Oracle RAC的核心是共享磁盘子系统,集群中所有节点必须能够访问所有数据文件、重做日志文件、控制文件和参数文件,因此,这些文件必须存放在共享存储中。常用的共享存储方式有OCFS、OCFS2、RAW、NFS、ASM 等。说明如下:
OCFS(Oracle Cluster File System) 和 OCFS2 都是文件系统,和 NFS 一样,提供集群环境共享存储的文件系统。
RAW 裸设备也是一种存储方式。把共享存储映射到 RAW Device,Oracle在存储数据时,选择 RAW device存储即可。但相对于文件系统来说, RAW不直观,不便于管理,而且有数量的限制,现已被OCFS取代。
ASM 是一种数据库存储的方案,并不是 cluster 的方案,使用 ASM 时,还需使用OCFS/OCFS2 或RAW。
2) 计算层
计算层至少需要两台以上的服务器,在每台服务器上安装集群软件和Oracle的 RAC 组件,从逻辑结构上看,每个节点都有一个独立的实例,这些实例访问同一个数据库。节点之间通过集群软件的通信层( Layer)进行通信,利用高速缓存合并技术,实现集群中各节点缓存的高速同步,使得集群中的每个实例,都保留了一份相同的数据库 cache。从而最大限度地低降低磁盘I/O。因此,RAC有如下特点:
2、Data Guard
在Data Gurad 环境中,至少有两个数据库,一个主库(Primary )处于Open 状态,另一个备库(Standby )处于standby状态。
备库又分物理库和逻辑库。物理库和主库完全一样,通过REDO应用来保持与主库的数据一致性,支持只读服务;逻辑库通过SQL应用,在备库端执行和主库同样的SQL语句,以此来保持与主库的数据一致,因此文件的物理结构(甚至数据的逻辑结构)都可以与主库不一致。逻辑库支持读写服务。
Data Guard适合多机房方案,实际部署时,主库部署在主机房,备库部署在其他机房。
二、 MySQL
(一) MySQL架构

1、连接器()
MySQL向外提供的接口,如java,.net,php等语言可以通过该组件来操作SQL语句,实现与SQL的交互。
2、管理服务组件和工具组件( Service & )
提供对MySQL的集成管理,如备份(Backup),恢复(),安全管理()等
3、连接池组件( Pool)
负责监听对客户端向MySQL Server端的各种请求,接收请求,转发请求到目标模块。每个成功连接MySQL Server的客户请求都会被创建或分配一个线程,该线程负责客户端与MySQL Server端的通信,接收客户端发送的命令,传递服务端的结果信息等。
4、SQL接口组件(SQL )
接收用户SQL命令,如DML,DDL和存储过程等,并将最终结果返回给用户。
5、查询分析器组件(Parser)
首先分析SQL命令语法的合法性,并尝试将SQL命令分解成数据结构,若分解失败,则提示SQL语句不合理。
6、优化器组件()
对SQL命令按照标准流程进行优化分析。
7、缓存主件(Caches & Buffers)
缓存和缓冲组件
8、MySQL存储引擎
MySQL属于关系型数据库,而关系型数据库的存储是以表的形式进行的,对于表的创建,数据的存储,检索,更新等都是由MySQL存储引擎完成的。
因MySQL的开源性,允许第三方基于MySQL骨架,开发适合自己业务需求的存储引擎。因此,MySQL支持的存储引擎种类较多,可以分为官方存储引擎和第三方存储引擎。
当前,MySQL的存储引擎有MyISAM、InnoDB、NDB、Archive、、Memory、Merge、Parter、、Custom等。其中,比较常用的存储引擎包括InnoDB、MyISAM和Momery。
9、物理文件(File System)
实际存储MySQL数据库文件和一些日志文件等的系统,如Linux,Unix,Windows等。
(二) 一个查询流程图
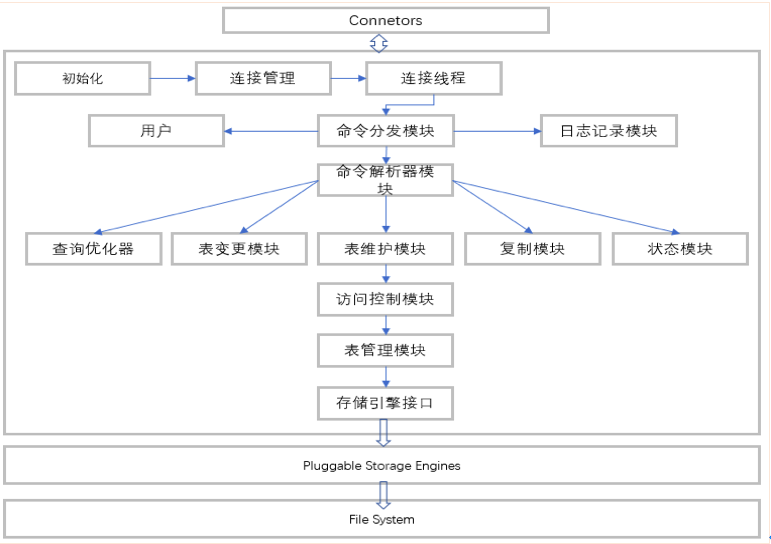
(三) MySQL的高可用架构
因MySQL的开源属性,其高可用架构非常灵活,目前常用的主要有以下几种:
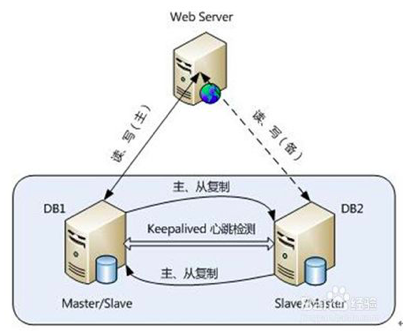
1、主从复制模式
这是MySQL自身提供的一种高可用解决方案,数据同步方法采用的是MySQL 技术。为了达到更高的可用性,在实际的应用环境中,需要配合高可用集群软件来实现自动,否则,需要手工切换。
2、MHA(Master High )
MHA是相对成熟的高可用解决方案,该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。搭建MHA时,要求一个集群必须最少有三台数据库服务器,一主二从(即一台master,一台备用master,另外一台slave)。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,或部署在一台slave节点上,MHA Node运行在每台MySQL服务器上。
运行时,MHA Manager会定时探测集群中的master节点,当master故障时,会自动将最新数据的slave提升为新的master,然后将其他所有slave重新指向新的master。整个故障转移过程对应用程序完全透明。整个切换过程如下:
3、MGR(MySQL Group )
MGR是MySQL官方推荐的另一种高可用架构,复制组间的数据同步基于Paxos协议。
当客户端发起更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作。在还没有真正提交之前,需要将产生的复制写集广播出去,复制到其它成员。如果冲突检测成功,组内决定该事务可以提交,其它成员可以应用,否则就回滚。
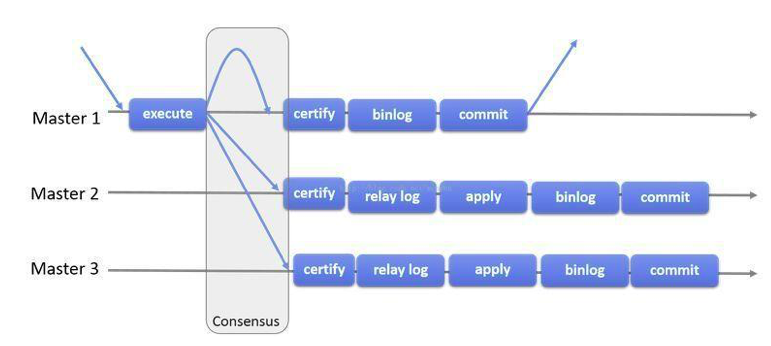
组复制可以在两种模式下运行:
三、
(一) 的体系架构
使用C/S模式提供服务。客户端和服务器可以在不同的主机上,通过TCP/IP进行网络连接,架构如下:
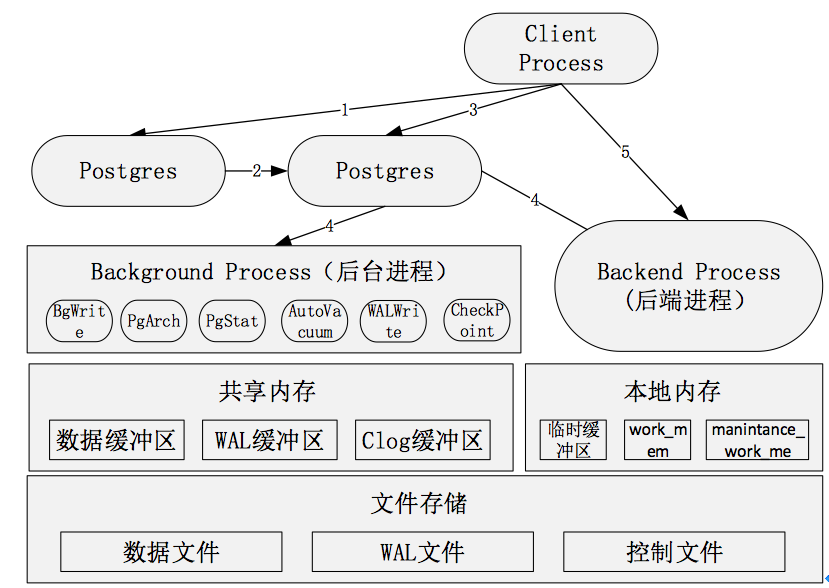
1、主进程(常驻进程)
主进程是启动时,第一个启动的进程。启动时,他会执行恢复、初始化共享内存,启动后台进程。当有客户端发起链接请求时,会生成子进程,同时创建后端进程。
是整个数据库实例的总控进程,负责启动和关闭该数据库实例。
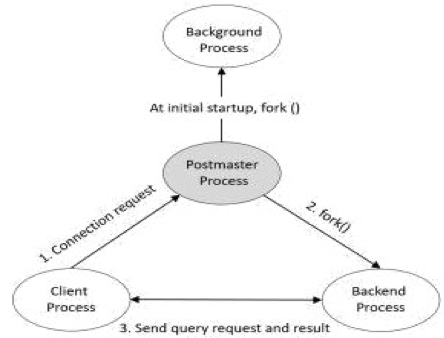
2、(子进程),子进程
接受前端请求,对数据库进行检索,最后返回结果。如请求是对数据库进行更新,会先记录日志(称为WAL日志),以便宕机重启时的数据恢复。另外,日志会定期归档保存,以便需要时进行数据恢复。
3、后台进程( Process)
4、共享内存和本地内存
示意图如下:
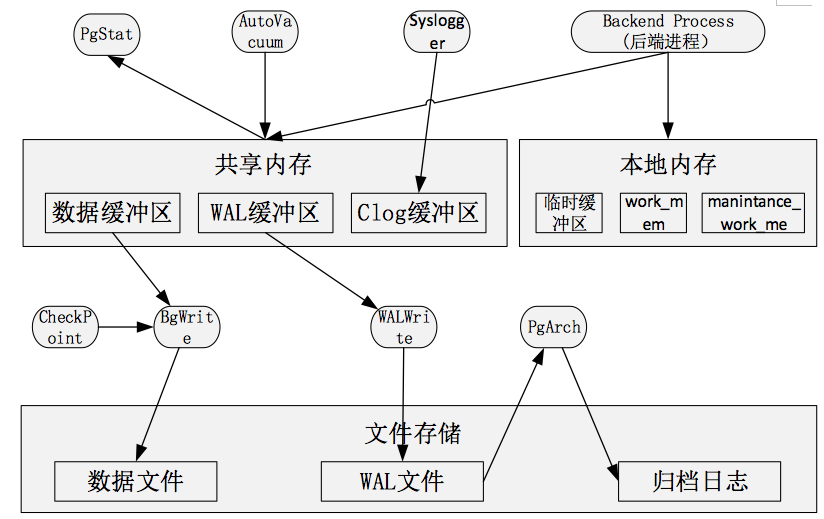
启动后,会生成一块共享内存,用于做数据块的缓冲区,以便提高读写性能。WAL日志缓冲区和Clog缓冲区也存在共享内存中,除此之外还有全局信息比如进程、锁、全局统计等信息也保存在共享内存中。
数据缓冲区通过BgWrite进程,定期将数据写入数据文件。WAL缓冲区通过进程写入WAL文件,并通过PgArch定期进行归档,写入归档日志
非全局存储的数据都存在本地内存中,主要包括:
(二) 数据结构
1. 数据库相关概念:
由一系列数据库组成。一套程序称之为一个数据库群集。
当initdb()命令执行后, , , 和数据库被创建。
和数据库是创建用户数据库时使用的模版数据库,他们包含系统元数据表。
initdb()刚完成后,和数据库中的表是一样的。但是数据库可以根据用户需要创建对象。
用户数据库是通过克隆数据库来创建的;
2. 表空间相关概念:
initdb()后,创建和表空间。
建表时如果没有指定特定的表空间,表默认被存在表空间中。
用于管理整个数据库集群的表默认被存储在表空间中。
表空间的物理位置为$目录。
表空间的物理位置为$目录。
一个表空间可以被多个数据库同时使用。此时,每一个数据库都会在表空间路径下创建为一个新的子路径。
创建一个用户表空间会在$目录下面创建一个软连接,连接到表空间制定的目录位置。
3. 表相关概念:
每个表有三个数据文件:
一个文件用于存储数据(文件名是表的OID);
一个文件用于管理表的空闲空间(文件名是OID_fsm)。
一个文件用于管理表的块是否可见(文件名是OID_vm)。
索引没有_vm文件,只有OID和OID_fsm两个文件
(三) 后端进程的处理流程
接收前端发送过来的查询(SQL文)
构文解析。将SQL文(单纯的文字)转换成构文树parser tree。
构文树解析完以后,换为查询树。这时会访问数据库,检查表是否存在,如果存在的话,则把表名转换为OID。这个处理称为分析处理(Analyze)。
因还通过查询语句的重写实现视图(view)和规则(rule),所以需要时,此阶段会对查询语句进行重写。
解析查询树后,可生成计划树。
按照执行计划里面的步骤可以完成查询要达到的目的。
执行结果返回给前端。
返回到步骤一重复执行。
四、 国产关系型数据库
国产关系型数据库较多,此处以GaussDB T为例
(一) GaussDB T架构
1. 内存结构
内存结构分为4部分,如下图:
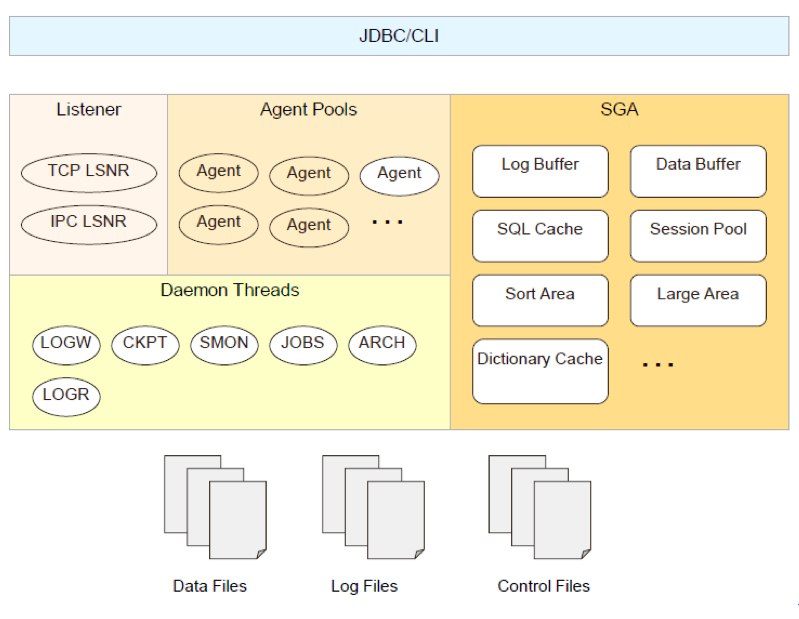
:包括TCP LSNR和IPC LSNR,用于侦听用户的连接请求
Agent Pool:代理的连接池
SGA:
2、存储结构
数据以文件方式存储,主要有三种文件:
DATA FILE,数据文件,用于存放各种数据,单库最多1024个数据文件,每个数据文件最大8T(undo除外,undo最大32G)
LOG FILE,日志文件,用于存放redo日志,可以重复使用,最少3组,每个redo 日志文件一般建议5-20G
CONTROL FILE,控制文件,用于数据库名、数据文件位置等信息,在数据库启动到mount阶段时会检查。
(二) GaussDB T关键技术
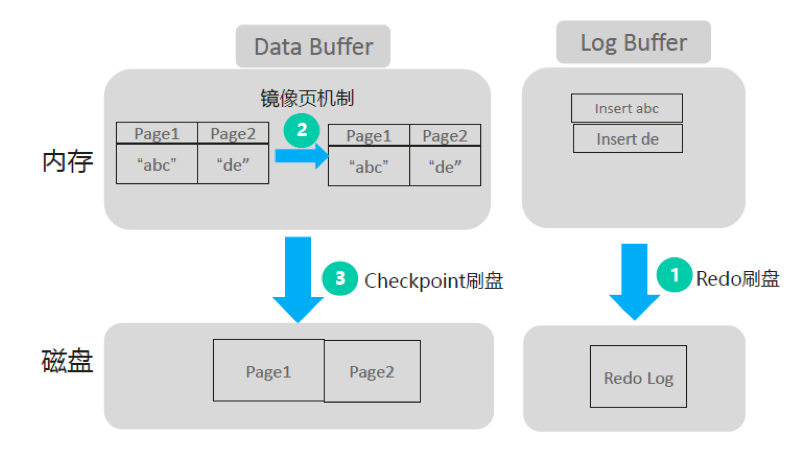
当进行事务提交时,必须先将Redo log刷盘。
脏页数据刷盘后,可用Redo日志可回收。
如果数据未刷盘前掉电,加电后需要重做Redo,保持数据的一致性。
脏页队列:脏页按时序组成链表,即脏页队列,按该队列顺序分组刷盘;
任务调度:后台服务线程通过定时、脏页量、RedoLog满,三个策略满足之一会触发刷盘操作;
Redo 任务调度:Redo后台服务线程通过定时、Redo buffer量、事务提交满足之一时会触发Redo Log Buffer刷盘操作;
镜像页机制:刷盘时间相对较长,为避免I/O阻塞,通过一个镜像页面缓存来完成刷盘。
采用MVCC机制提高事务并发能力。
(三) GaussDB T的高可用部署模式
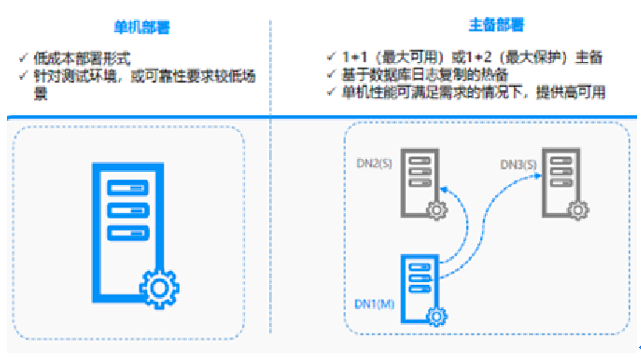
1、单机和主备部署模式
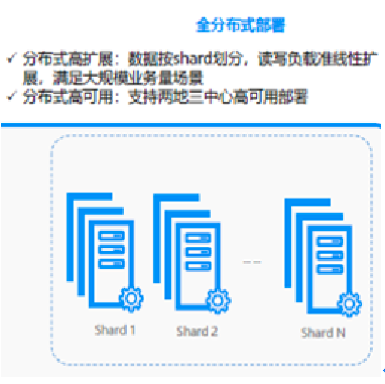
2、分布式部署模式
(四) 典型的分布式部署架构
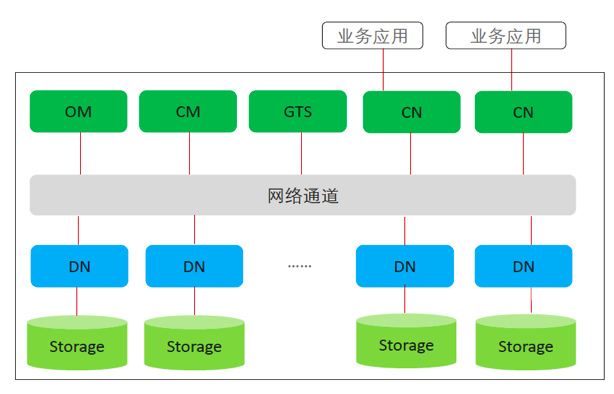
各组件说明如下:
OM( Manager):运维管理模块。提供集群日常运维、配置管理的管理接口、工具。
CM(Cluster Manager):集群管理模块。管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。
CN( Node):协同调度节点。负责接收来自应用的访问请求,并向客户端返回执行结果;负责分解任务,并调度任务分片在各DN上并行执行。集群中,CN有多个且CN的角色是平等的。
DN():数据节点。负责存储业务数据,执行数据查询任务以及向CN返回执行结果。在集群中,DN有多个。每个DN支持设置多个存储备机。
GTS(Global Time Server):全局时钟服务器。用于强一致场景下,为各个节点提供逻辑时钟。
五、 主流关系型数据库特点分析

原题:常用(闭源、开源)关系型数据库的分析与比较
*请认真填写需求信息,我们会在24小时内与您取得联系。
