整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:

电脑端+手机端+微信端=数据同步管理
免费咨询热线:
前言
本书第1版自2015年2月出版后,在市场上获得了强烈的反响,当月在当当网的新书热卖榜中排名第二,半年内销售近万册,至2016年1月已经印刷了5次,共发行近两万册,图书被收录进百度百科。
如此巨大的市场销量和好评,引起笔者的深思,除本书构思巧妙、内容翔实、文法流畅等主观因素外,宏观的市场环境也是不容忽视的。2015年,中国经济由原来的爆发式增长进入到略显低迷的新常态,无论是企业还是商家都感受到了压力,钱不再像以前那样好赚了。如何实现经济增长,如何让企业存活下去,这就需要深挖企业内部的痛点和洞察外部客户的特点。深挖和洞察的过程就是数据分析的过程,数据分析时代在中国悄然到来了。
随着数据分析师的价值凸显,有越来越多先知先觉的人们纷纷转行加入到数据分析师的大军中。而统计学是数据分析师们必修的课程之一,“从零进阶!数据分析的统计基础”的本意就是让更多的人能从零基础快速进阶到数据分析领域,并且重点讲述数据分析师们必须具备的概率和统计的关键知识点。而经管之家(原人大经济论坛)适时地推出本书,使其得到了很好的市场回馈。正所谓天时地利人和,造就了一本好书。
为了和市场的发展紧密结合,以及更好地适应读者的需求,本书进行了改版。本次改版继续坚持从零进阶,强化数据分析基础理论,和市场接轨等核心理念,继续使用“三国武将”这个大家都耳熟能详的业务背景知识。根据学员的需求和市场的实际情况,作者还对本书内容进行了如下调整。

(1)进一步精练数据分析的理论基础,去除了一些不必要的数学公式。由于数据分析涉及概率论、微积分、数理统计的很多内容,但有些内容又不用全部学会,这让初学者很难找出哪些是需要学习的内容,哪些是不需要学习的内容。因此在编写本书第1版时,将很多数据分析师不需要知道的知识点都省略了,比如省略了统计量服从某个分布的证明过程,省略了抽样平均误差的证明过程。这样做的目的是为了让数据分析师们能更快地进入这个领域,更好地洞察数据。在编写本书的第2版时,继续沿用此思想,去掉了一些数据分析师不必要知道的公式,增加了更多的数据分析思想的内容。
(2)将原来的第3章抽样估计分解成数理统计基础和抽样估计两章,这样做的目的是考虑到原来的第3章涉及的理论内容太多,并且比较枯燥,将其分成两部分,一来可以在每一部分增加更多的公式解读内容,也可以补充更多的案例进来;二来降低了阅读难度,使读者能在学习知识的同时,获得更多的成就感,从而更加有兴趣学习。
(3)对试验数据进行了更多的数据分析,增加了对读者数据分析思维的培养。尤其是第2章的描述性数据分析过程,进行了更深入的数据分析过程剖析,主要宗旨在于让读者更快地进入到数据分析行业的队伍中来。当然,这也使得第2版中的三国武将数据和第1版中的数据存在一些差异。
当然,仅就本书而言,读者并不会学到数据分析师所需要的全部知识,这需要几年的循序渐进学习,但我希望读者看过本书后,能快速具有数据分析师所需要的最基本的统计学知识,能快速地进入到数据分析的行业,从而具备一个数据分析师应具备的最起码的知识,在工作中能说内行话,而不是说行外话。

在本书改版之际,作者衷心感谢经管之家(原人大经济论坛)和CDA课程研发团队多年来始终不渝的关心与鼎力支持,感谢关继杰,感谢广大读者给予我的理解与感受,感谢电子工业出版社多年来的密切合作与支持。没有这一切,本书不可能取得这么好的成果,我永远感谢曾经帮助和支持过我的相识的和不相识的同志和朋友。由于作者水平有限,本书肯定会有不少缺点和不足,热切期望得到专家和读者的批评指正。
曹正凤
2016年3月于北京
Oracle数据库性能调优实践(一)——概述
摘要:Oracle数据库应用系统的调优主要包括八个方面:1、优化连接数/会话数;2、优化数据库内存;3、优化SQL语句;4、优化索引;5、优化磁盘I/O;6、优化数据存储;7、优化操作系统环境;8、定期生成数据库对象使用状态的统计信息。数据库性能调优的实质就是优化内存、降低CPU负载、改善I/O性能。详细内容请看下文。
1、优化连接数/会话数
查询数据库当前进程的连接数:
SQL> select count(*) from v$process;
查看数据库当前会话的连接数:
SQL> select count(*) from v$session;
查看数据库的并发连接数:
SQL> select count(*) from v$session where status='ACTIVE';
查看当前数据库建立的会话情况:
SQL> select sid,serial#,,program,machine,status from v$session;
查询数据库允许的最大连接数:
SQL> select value from v$ where name = '';
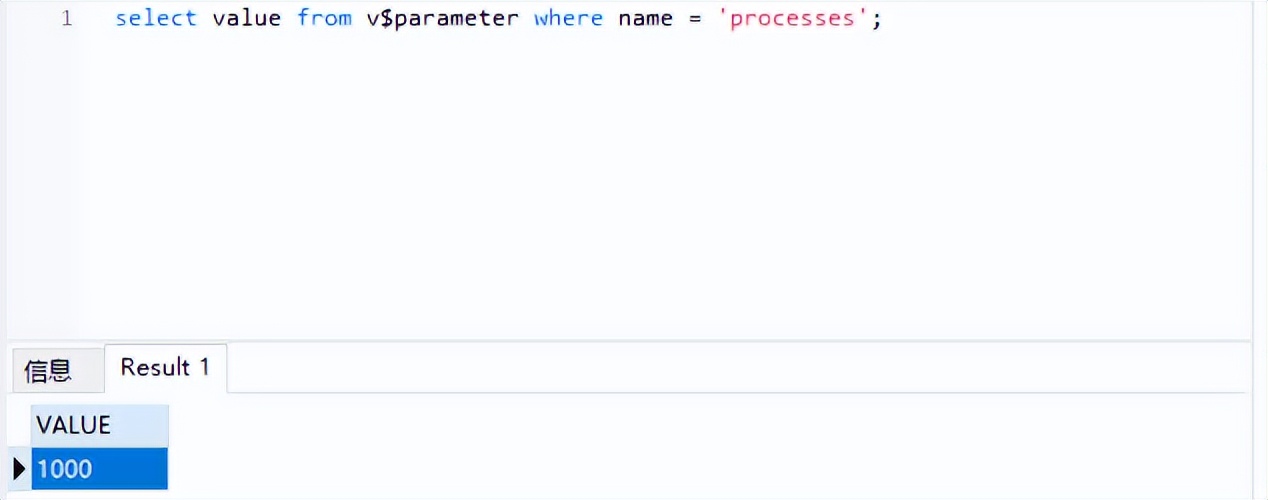
如果需要修改数据库允许的最大连接数,执行alter指令:
SQL> alter system set = 1200 scope = spfile;
(注意:执行alter语句并commit后,需要重启数据库才能实现连接数的修改操作生效。)
2、优化数据库内存
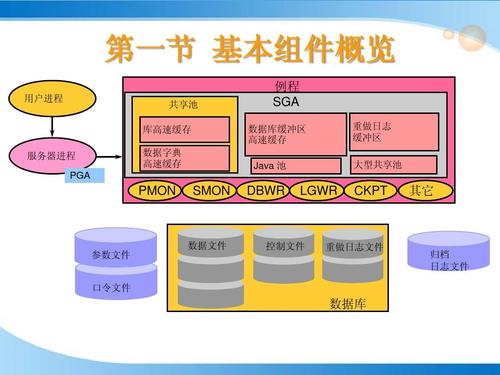
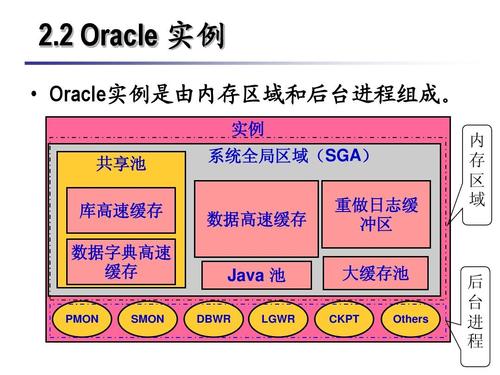
对Oracle数据库来说,Oracle 实例= 内存结构 + 进程结构,而内存结构 = SGA + PGA。SGA(系统全局区)是用户存储数据库信息的内存区,该区域为数据库进程所共享。它包含服务器的数据和控制信息,主要包含高速数据缓冲区、共享池、重做日志缓存区、Java池,大型池等内存结构。SGA的设置,理论上SGA的大小应该占OS的内存的 1/3-1/2左右。SGA + PGA + OS使用的内存 < 服务器中的物理内存。
查看当前系统SGA的信息的指令为:
SQL> select name,bytes/1024/1024 as "Size(M)" from v$sgainfo;
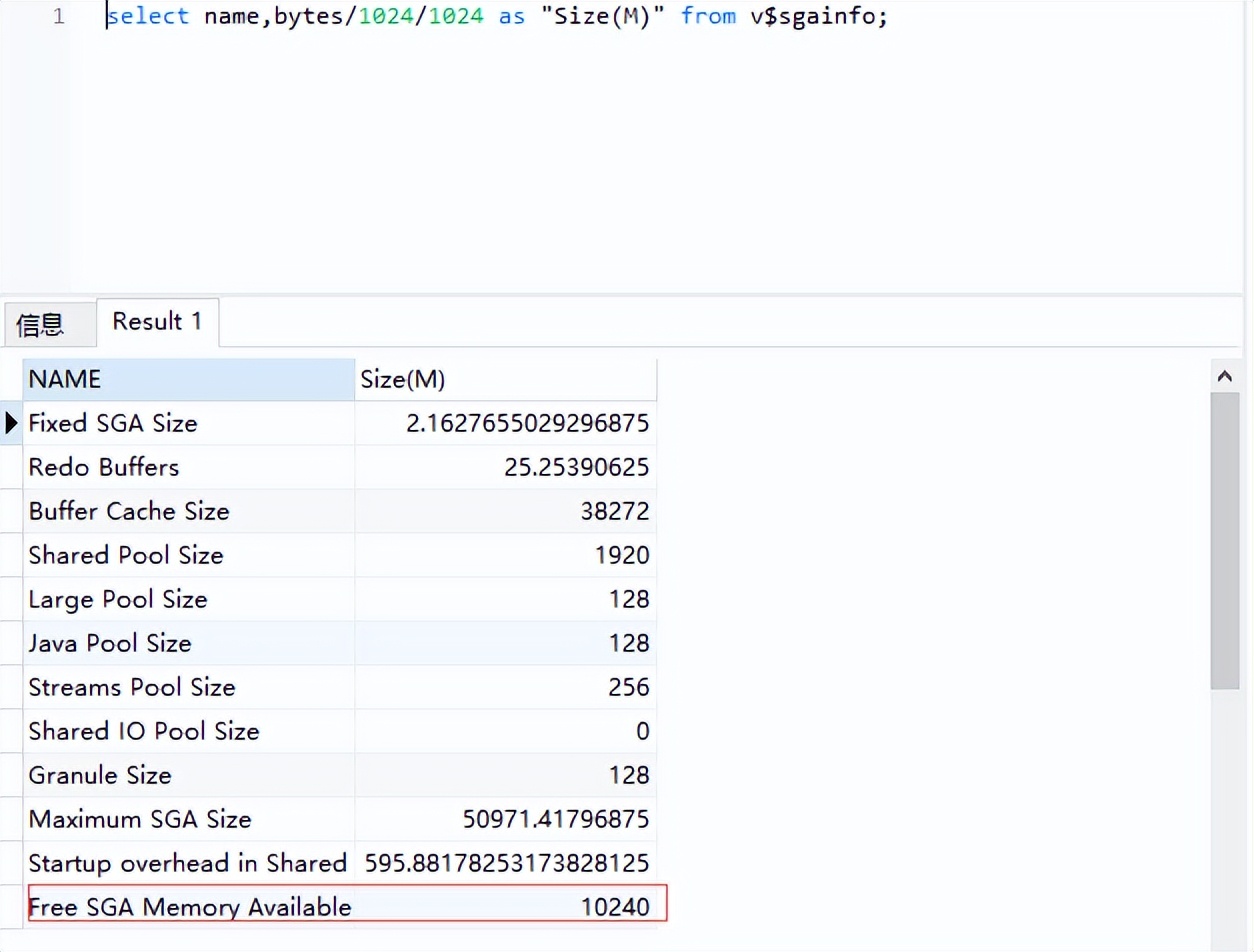
备注:根据查询信息显示当前还有10240M可用的SGA内存,系统当前的内存配置还是比较充足的。
不过,我们在实际使用过程中还是可以根据实际需求重新分配内存。
增大系统全局区:
SQL> alter system set =12000m scope=spfile;
增大数据缓存区:
SQL> alter system set =7000m scope=spfile;
增大共享内存区:
SQL> alter system set =3200m scope=spfile;
增大程序全局区:
SQL> alter system set =5000m scope=spfile;
增大排序区:
SQL> alter system set =3000m scope=spfile;
(注意:执行alter语句并commit后,需要重启数据库才能实现连接数的修改操作生效。)
3、优化SQL语句
SQL 调优的目标是简单的:第一、消除不必要的大表全表搜索,不必要的全表搜索导致大量不必要的 I/O ,从而拖慢整个数据库的性能。第二、确保最优的索引使用 ,对于改善查询的速度,这是特别重要的。有时 Oracle 可以选择多个索引来进行查询,必须检查每个索引并且确保 Oracle 使用正确的索引。第三、确保最优的 JOIN 操作:有些查询使用nested loop join嵌套循环连接快一些,有些则hash join散列连接快一些,另外一些则是sort merge join排序合并连接更快。这三个调优规则看来简单,不过它们占 SQL 调优任务的 90%,需要深入学习 。
4、优化索引
数据库索引是建立在数据表的一列或多个列上的辅助对象,目的是加快访问表中的数据。索引是数据库维护的可选结构,比较难的是怎么准确地判断在什么地方需要使用索引,使用索引有利于调节检索速度。当建立一个索引时,必须指定用于跟踪的表名以及一个或多个表列。一旦建立了索引,在用户表中建立、更改和删除数据库时,数据库就自动地维护索引。如果需要创建索引,请参考下列三个准则:第一、索引应该在SQL语句的"where"或"and"部分涉及的表列被建立。第二、创建索引具有一定范围的表列,这里有一个大致的原则,如果表中列的值占该表中行的20%以内,这个表列就可以作为候选索引表列。第三、如果在SQL语句中多个表列被一起连续引用,则应该考虑将这些表列一起放在一个索引内,数据库将维护单个表列的索引(建立在单一表列上)或复合索引(建立在多个表列上)。
怎么监控无用的索引,如果在一段时间内,发现没有被使用的索引,一般就是无用的索引。其查询指令为:
开始监控:
SQL> alter index usage;
检查使用状态:
SQL> select * from v$;
停止监控:
SQL> alter index usage;
5、优化磁盘I/O
使用指令查看数据文件的I/O:
SQL> SELECT NAME,PHYRDS,PHYWRTS FROM V$ DF,V$ FS WHERE DF.FILE#=FS.FILE# order by readtim desc;
用以下查询语句可以得到各表空间读写次数,phyrds+phywrts 即是磁盘I/O量。
select name,phyrds,phywrts from v$,v$ where v$.file# = v$.file# order by readtim desc;
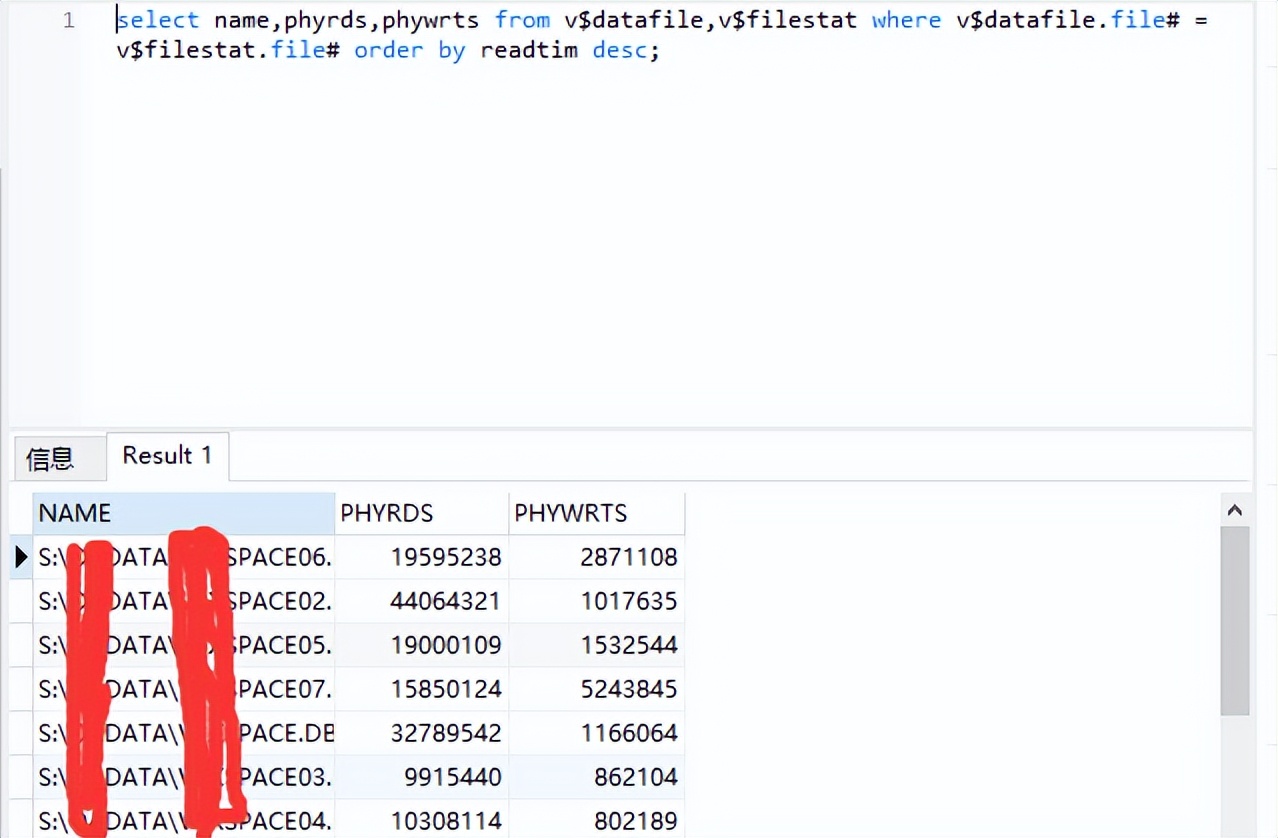
说明:如果发现在磁盘上的写入和读取次数上出现很大的差别,就表明肯定有哪个磁盘负载过多。出现磁盘负载不平衡,这时可以通过移动数据文件来均衡文件I/O:
SQL>alter offline;
$cp /disk1/test.dbf /disk2/test.dbf;
SQL>alter rename '/disk1/test.dbf' to '/disk2/test.dbf';
SQL>alter online;
$rm /disk1/test.dbf
6、优化数据存储
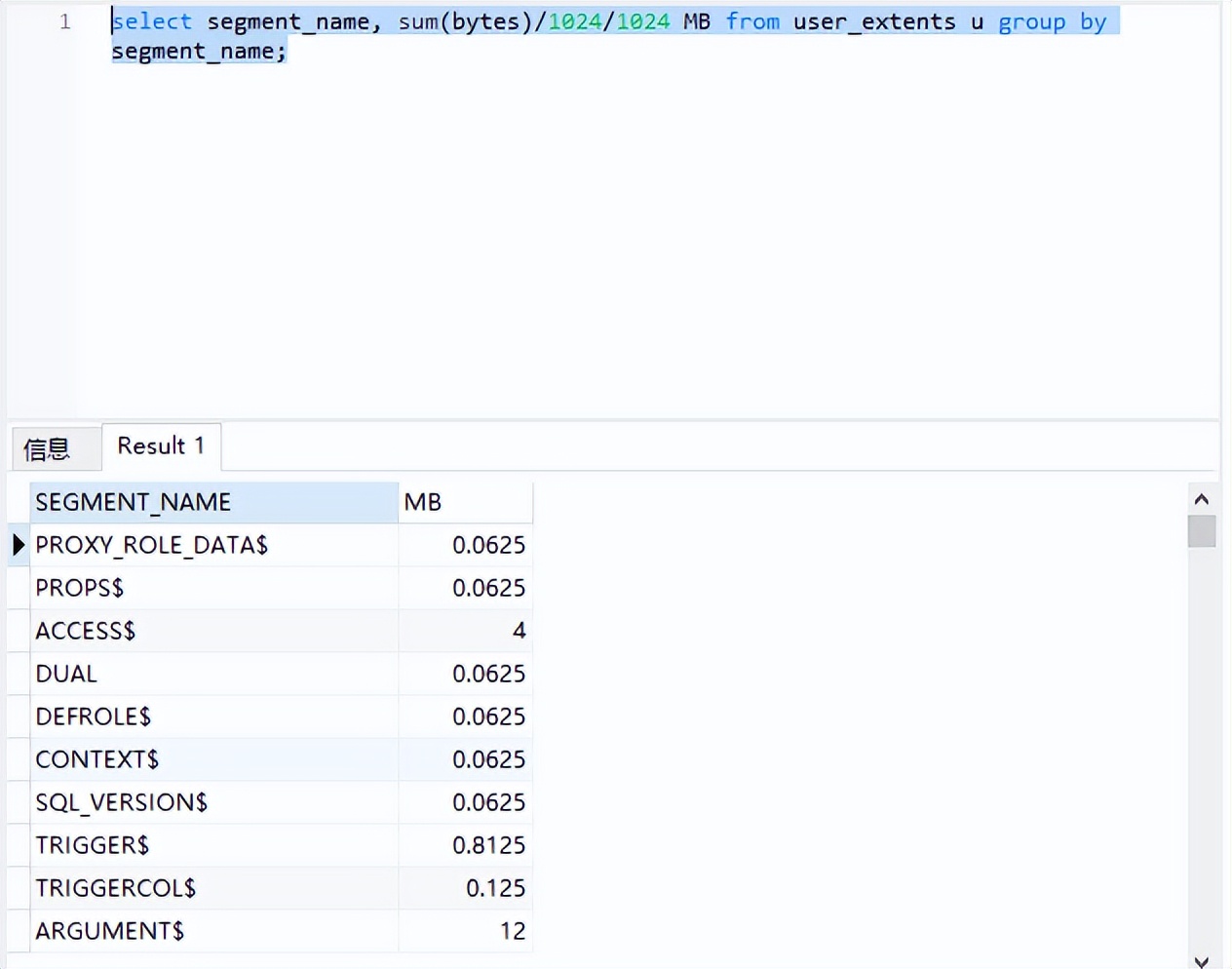
查询数据库中各个表的实际数据存储使用情况的语句:
SQL> select , sum(bytes)/1024/1024 MB from u group by ;
查询表空间对应的存储文件的语句:
SQL> select ,file_id,,round(bytes / (1024 * 1024), 0) from sys. order by ;
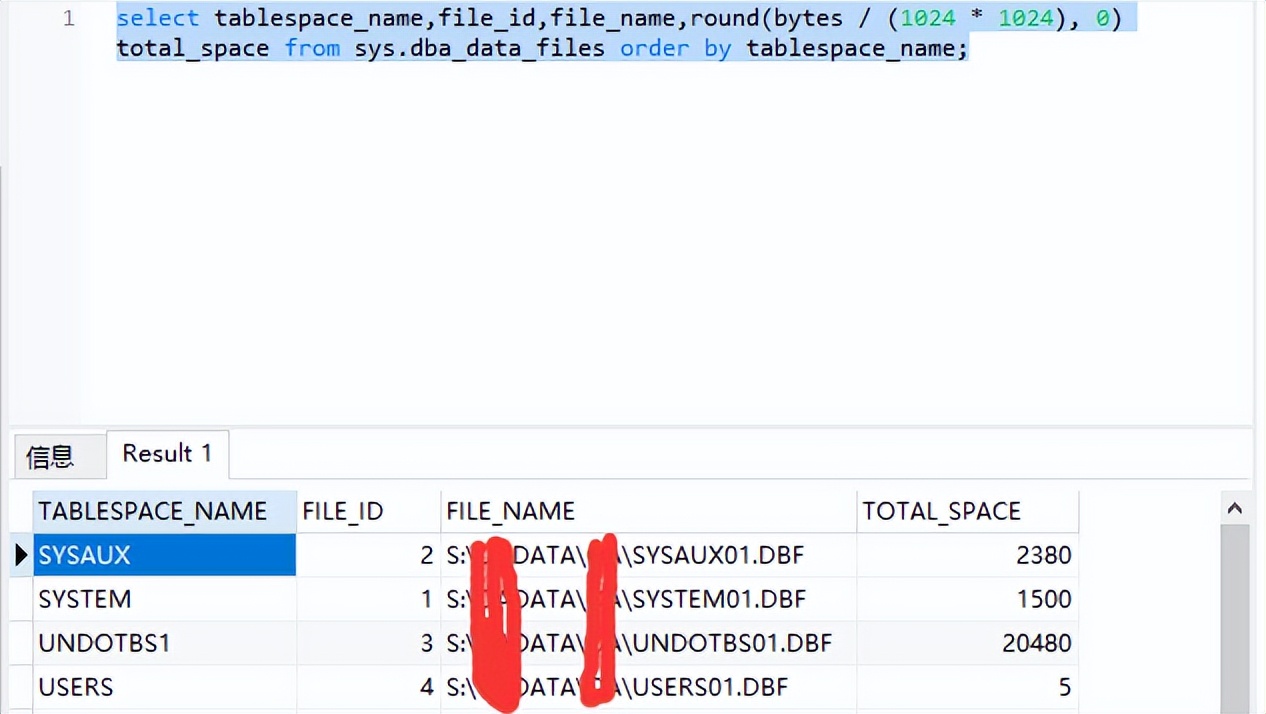
说明:可以通过扩展表空间对应存储文件的方式扩展表空间。其扩容语句为 alter '表空间位置' resize 新的容量。
7、优化操作系统环境
操作系统优化时应该考虑的因素有:内存的使用;CPU的使用;IO级别;网络流量等。各个因素互相影响,正确的优化次序是内存、IO、CPU、网络流量。操作系统使用了虚拟内存的概念,虚拟内存使每个应用感觉自己是使用内存的唯一的应用,每个应用都看到地址从0开始的单独的一块内存,虚拟内存被分成4K或8K的page,操作系统通过MMU(memory unit)管理单元将这些page与物理内存进行映射。
8、定期生成数据库运行状况统计信息
从ORACLE 10g开始,Oracle在建库后就默认创建了一个名为的定时任务,用于自动收集CBO的统计信息。
这个自动任务默认情况下在工作日晚上10:00-6:00和周末全天开启。
调用.收集统计信息。该过程首先检测统计信息缺失和陈旧的对象。然后确定优先级,再开始进行统计信息。
可以通过以下查询这个JOB的运行情况:
SELECT * FROM WHERE = '';
可以通过下面语句查看JOB任务:
SQL> SELECT , FROM ;
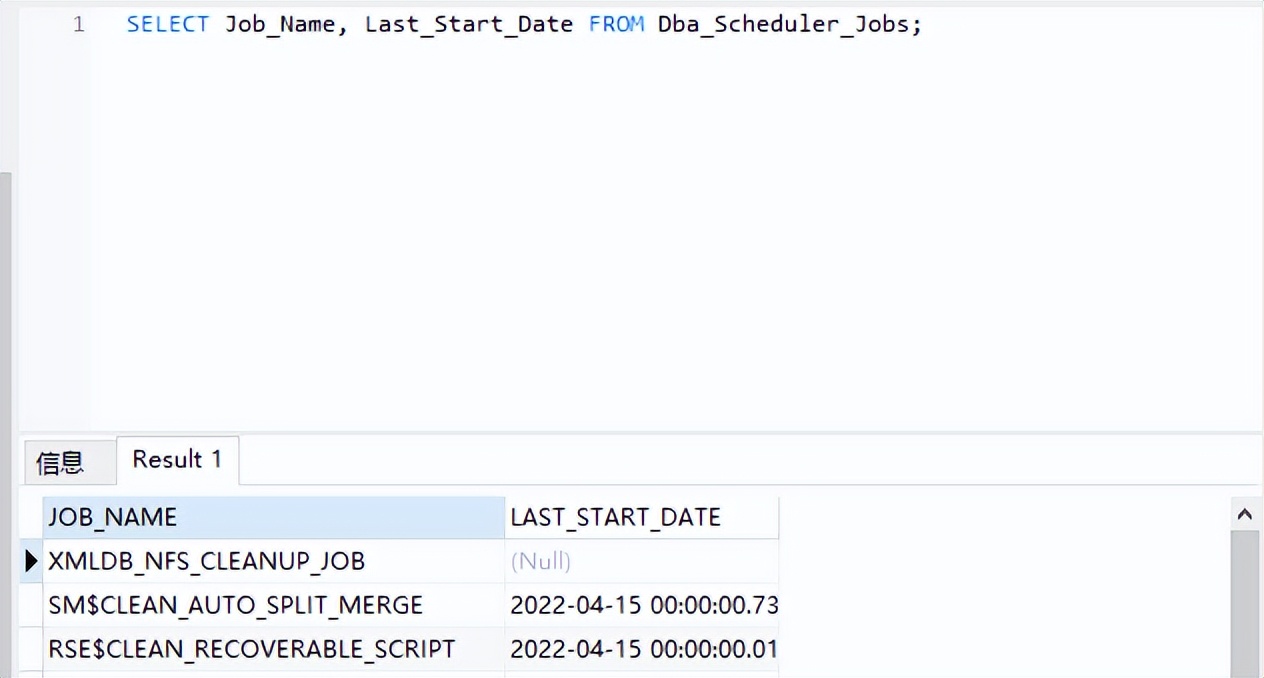
说明:关闭及开启自动搜集功能,有两种方法,分别如下:
方法一:exec .disable('SYS.');
exec .enable('SYS.');
方法二:alter system set "_job"=false scope=spfile;
alter system set "_job"=true scope=spfile;
*请认真填写需求信息,我们会在24小时内与您取得联系。
